


In the fast-paced world of data-driven decision-making, extracting valuable insights from popular platforms like Quora is essential. Whether you’re a business owner, data analyst, or engineer, understanding public opinion and trends on Quora can be transformative in informing your strategies and decisions.
This article will explore how to scrape Quora Q&As using Python, Selenium, and ScraperAPI, efficiently collecting data while navigating Quora’s anti-scraping measures.
In this tutorial, you’ll learn how to:
- Use Selenium to automate browser actions and mimic human behavior
- Navigate Quora’s dynamic content loading to capture all the answers you need
- Use BeautifulSoup to parse and extract the information cleanly and efficiently
- Implement proxy management with Selenium Wire to keep your scraping smooth and uninterrupted.
TL;DR: Full TechCrunch Scraper
Here’s the completed code for those in a hurry:
import time
import csv
from bs4 import BeautifulSoup
from seleniumwire import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
def configure_selenium_wire_proxy(api_key):
"""Configures selenium wire to use a specified proxy with the provided API key."""
proxy_options = {
'proxy': {
'http': f'http://scraperapi.render=true:{api_key}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi.render=true.country_code=us.premium=true:{api_key}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
return proxy_options
def scroll_to_bottom(driver):
"""Scrolls the webdriver instance to the bottom of the page."""
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
time.sleep(10) # Wait for page to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height: # Check if the bottom has been reached
break
last_height = new_height
def scrape_answers(driver):
"""Scrapes non-ad answers from a Quora page."""
soup = BeautifulSoup(driver.page_source, 'html.parser')
main_content = soup.find("div", attrs={"id": "mainContent"})
all_results = main_content.find_all("div", class_="q-click-wrapper qu-display--block qu-tapHighlight--none qu-cursor--pointer ClickWrapper___StyledClickWrapperBox-zoqi4f-0 iyYUZT")
# Class name indicating ads to avoid
ad_class = "q-box dom_annotate_ad_promoted_answer"
non_ad_results = [result for result in all_results if not result.find_parents(class_=ad_class)]
return non_ad_results
def write_to_csv(results, query):
"""Writes the scraped results to a CSV file."""
with open('quora_answers.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Question", "Answer", "Upvotes"])
for result in results:
question = result.find('div', class_="q-text qu-dynamicFontSize--regular_title qu-fontWeight--bold qu-color--gray_dark_dim qu-passColorToLinks qu-lineHeight--regular qu-wordBreak--break-word")
answer = result.find('div', class_="q-box spacing_log_answer_content puppeteer_test_answer_content")
parent = result.find_parent("div")
upvote = parent.find("span", class_="q-text qu-whiteSpace--nowrap qu-display--inline-flex qu-alignItems--center qu-justifyContent--center")
answer_text = answer.text if answer else "No answer text available"
question_text = question.text.replace("Related", "") if question else query
upvote = upvote.text if upvote else "0"
writer.writerow([question_text, answer_text, upvote])
print(f"Written {len(results)} answers to quora_answers.csv")
# Configure the webdriver with proxy support
chrome_options = webdriver.ChromeOptions()
API_KEY = "YOUR_API_KEY"
proxy_options = configure_selenium_wire_proxy(API_KEY)
driver = webdriver.Chrome(options=chrome_options, seleniumwire_options=proxy_options)
try:
query = "What is the easiest way to learn to code?"
driver.get(f"https://www.quora.com/{query.replace(' ', '-')}-q{query.replace(' ', '-')}")
time.sleep(100) # Initial wait for page to load
scroll_to_bottom(driver) # Scroll to the bottom of the page
answers = scrape_answers(driver) # Scrape non-ad answers
write_to_csv(answers, query) # Write the answers to a CSV file
except Exception as e:
print("An error occurred:", e)
finally:
driver.quit() # Ensure the driver is quit properly
Before running the code, add your API key to the API_key parameter within the payload.
Note: Don’t have an API key? Create a free ScraperAPI account to get 5,000 API credits to try all our tools for 7 days.
Want to see how we built it? Keep reading and join us on this exciting scraping journey!
Why Scrape Quora?
Scraping Quora Q&As helps you get lots of useful information for different reasons:
- Stay Informed on Diverse Topics: Quora has answers and opinions on almost everything. This can help you stay updated, see what’s new, and learn from experts in all kinds of areas.
- Market Research and Competitive Analysis: Seeing what people ask and say about products or services can give you great ideas for your business and help you understand what your competitors are doing.
- Content Creation and Strategy: Find out what questions people are really interested in and what answers they like. This can guide you to create content that people will want to read or watch.
Scraping Quora the Right Way
When scraping Quora, it’s important to do it responsibly:
- Respecting Quora’s Terms of Service: Familiarize yourself with and adhere to Quora’s guidelines to avoid violating them while scraping.
- Prioritizing User Privacy: Be mindful of the privacy of Quora’s users. Avoid collecting or disseminating personal data without consent, and consider anonymizing data where possible.
- Legally Sound Practices: Ensure your scraping activities are legal. This means strictly avoiding any content not meant to be publicly accessed or shared, and bypassing login walls.
By keeping these points in mind, you can collect valuable information from Quora in a way that’s fair and respects everyone involved.
Scrape Quora Q&As with Python
In this tutorial; we will navigate through the question’s page to scrape Quora answers, methodically extracting the answers and their corresponding upvote counts.
We will utilize automated browser simulation to ensure we capture the data as a user would see it, enabling us to capture all the dynamically loaded content on the webpage.
Requirements
Before we dive into the scraping of Quora Q&As, we must prepare our environment with the necessary tools and libraries.
Here’s how to set everything up:
- Python Installation: Make sure Python is installed on your system, preferably version 3.10 or later. You can download it from the official Python website.
- Library Installations: For this guide, we will use several Python libraries – Selenium, BeautifulSoup (bs4), and Selenium-wire. Install them using the following command in your terminal or command prompt:
pip install selenium beautifulsoup4 selenium-wire
selenium: This tool allows us to automate web browser interaction, enabling us to navigate through Quora’s pages like a real user. It’s crucial for simulating human-like behavior and dealing with dynamic content.- bs4 (
Beautiful soup): BeautifulSoup aids in parsing HTML content. It helps us sift through Quora’s complex page structure to extract the questions and answers we’re interested in. This library makes it easier to navigate and parse the web pages, extracting the necessary data efficiently. seleniumwire: We’ll use Selenium Wire to extend Selenium’s functionality, enabling proxy management for our web requests through ScraperAPI. This integration is vital for smoothly bypassing Quora’s anti-scraping measures, ensuring our scraping process remains efficient and uninterrupted by leveraging ScraperAPI’s Standard API in proxy mode.
Understanding Quora’s Website Layout
With our environment ready for scraping, it’s time to explore Quora’s website layout to understand how information is structured. Identifying key HTML elements that contain the Q&A data is crucial. We will extract essential details from discussions, including questions, answers, and upvote counts.
In this article, we’re focusing on the Quora question page for the question: “What is the easiest way to learn to code?”.
This is what the page looks like on Quora:

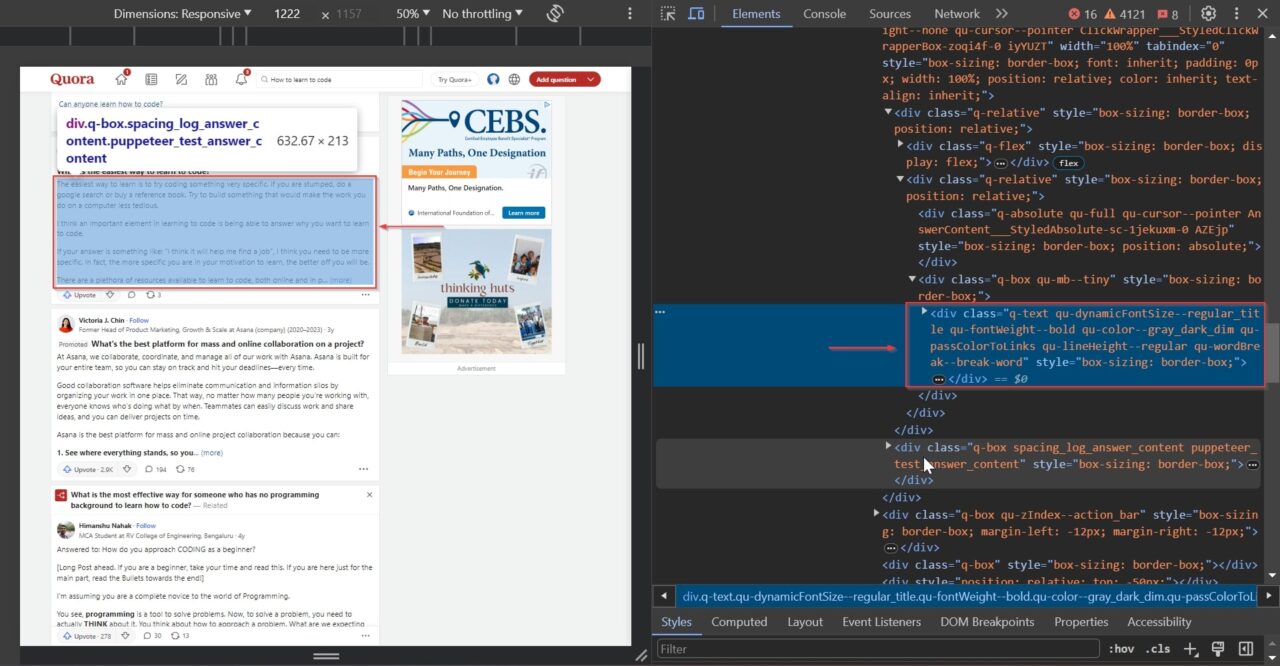
We’ll be scraping the individual answers provided to the question on Quora. We’ll use the developer tools (right-click on the webpage and select ‘inspect’) to examine the HTML structure and locate the HTML elements holding the data we need.
This div tag contains all the answers present on the page; it’s the main tag we will be targeting first: #mainContent

This div tag contains the question:
.q-text qu-dynamicFontSize--regular_title qu-fontWeight--bold qu-color--gray_dark_dim qu-passColorToLinks qu-lineHeight--regular qu-wordBreak--break-word

Extracting answers from Quora is essential for understanding its community’s collective intelligence and insights.
By extracting the answers, we can compile comprehensive knowledge bases, identify common themes or advice, and analyze the depth of user engagement around specific inquiries.
The key to our data extraction process is the HTML element containing the answer text.
This div tag is the tag that contains the answer:
.q-box spacing_log_answer_content puppeteer_test_answer_content
Capturing the number of upvotes on answers lets us know which ones people find most helpful. It’s a quick way to see what information stands out on Quora.
This span tag contains the upvote:
.q-text qu-whiteSpace--nowrap qu-display--inline-flex qu-alignItems--center qu-justifyContent--center

The last element we need to identify to make our scraping more effective is the element that contains ad answers; we need to know this to eliminate them from our results and make them more accurate.
This div contains the ad answers:
.q-box dom_annotate_ad_promoted_answer
Note: Deleting ad answers ensures we’re only considering organic user responses.

Now we’re all set to start scraping!
Step 1: Import Libraries
First, we import all necessary Python libraries:
time: Adds delays between actions to mimic human behavior.csv: Manages CSV file operations for storing our scraped data.BeautifulSoup (bs4): Parses HTML content for data extraction.seleniumwire: Enables web automation with proxy support, which is crucial for using ScraperAPI in proxy mode.Keysfromselenium: Simulates keyboard actions (e.g., End key for page scrolling).Byfromselenium: Specifies methods for locating web elements (tags, IDs, class names), which is helpful for precise data selection during scraping.
import time
import csv
from bs4 import BeautifulSoup
from seleniumwire import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
Step 2: Configuring Proxy with Selenium Wire
Next, to enable Selenium Wire to use ScraperAPI as a proxy, we define a function configure_selenium_wire_proxy() that sets up proxy options.
This setup is needed to bypass web scraping restrictions by making our script’s requests appear as legitimate browser activity.
The function will take our Scraper API key as an argument and return a dictionary of proxy options configured for HTTP and HTTPS protocols.
We include the render=true parameter in the proxy options for ScraperAPI, which ensures the webpage is fully rendered, including JavaScript-generated content, before content is fetched.
Note: Adding the render=true would increase your API credits cost, so test the scraper without the parameter to make sure you actually need it. In most cases, Selenium can render the page on its own.
def configure_selenium_wire_proxy(api_key):
"""Configures selenium wire to use a specified proxy with the provided API key."""
proxy_options = {
'proxy': {
'http': f'http://scraperapi.render=true:{api_key}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi.render=true.country_code=us.premium=true:{api_key}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
return proxy_options
This function ensures that all web traffic from our Selenium Wire-driven browser goes through ScraperAPI, leveraging its capabilities to navigate around anti-scraping measures seamlessly.
Step 3: Implementing Scroll to Load Dynamic Content
Next, in order to fully capture dynamically loaded answers on Quora, we define a scroll_to_bottom() function.
In this function, we start by grabbing the current bottom of the page. Then, we enter a loop where we simulate pressing the End key using the send_keys() function, which scrolls us down.
After each scroll, we wait a bit to let any new content load. We check if we’ve really hit the bottom by comparing the page’s height before and after the scroll. If it hasn’t changed, we’ve reached the bottom, and every piece of content is loaded and ready for us to scrape.
def scroll_to_bottom(driver):
"""Scrolls the webdriver instance to the bottom of the page."""
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
time.sleep(10)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
This step is key to making sure we don’t miss anything dynamically loaded as we move through the page.
Step 4: Extracting Data with BeautifulSoup
Now that our page is fully loaded, it’s time to dig into the content with BeautifulSoup. We’re looking for the answers to our Quora question, so we’ll create a scrape_answers() function, which takes our seleniumwire driver as an argument.
In this function, BeautifulSoup takes the page source from our driver and turns it into a navigable structure. We target the main content area where answers are stored, which is the div element we identified earlier, and loop through each answer, filtering out any that are marked as ads.
def scrape_answers(driver):
soup = BeautifulSoup(driver.page_source, 'html.parser')
main_content = soup.find("div", attrs={"id": "mainContent"})
all_results = main_content.find_all("div", class_="q-click-wrapper qu-display--block qu-tapHighlight--none qu-cursor--pointer ClickWrapper___StyledClickWrapperBox-zoqi4f-0 iyYUZT")
non_ad_results = [result for result in all_results if not result.find_parents(class_="q-box dom_annotate_ad_promoted_answer")]
return non_ad_results
Step 5: Saving Extracted Data to a CSV File
After collecting all the results, it’s time to organize and save them for future use. We’ll do this by creating a CSV file, a format that’s easy to read and analyze. We’ll define a write_to_csv() function to do this.
We start by creating quora_answers.csv. Then, we create a csv.writer object and use it to write the header row with “Question”, “Answer”, and “Upvotes”.
def write_to_csv(results, query):
"""Writes the scraped results to a CSV file."""
with open('quora_answers.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Question", "Answer", "Upvotes"])
We carefully pull the question, answer, and, importantly, the upvotes for each piece of extracted data. The upvotes are tricky since they’re not within the answer’s direct HTML structure but in a containing or parent div.
We use find_parent() to ascend the HTML tree from the answer to where the upvotes are located
for result in results:
question = result.find('div', class_="q-text qu-dynamicFontSize--regular_title qu-fontWeight--bold qu-color--gray_dark_dim qu-passColorToLinks qu-lineHeight--regular qu-wordBreak--break-word")
answer = result.find('div', class_="q-box spacing_log_answer_content puppeteer_test_answer_content")
parent = result.find_parent("div")
upvote = parent.find("span", class_="q-text qu-whiteSpace--nowrap qu-display--inline-flex qu-alignItems--center qu-justifyContent--center")
answer_text = answer.text if answer else "No answer text available"
question_text = question.text.replace("Related", "") if question else query
upvote = upvote.text if upvote else "0"
We compile a row of data for every answer we’ve processed:
- The question text (with a small tweak to remove the text “Related” from the question for clarity)
- The answer text
- The upvote count
If we don’t find an answer or upvotes, we use default values like “No answer text available” or “0”.
writer.writerow([question_text, answer_text, upvote])
After all data is written, we print a confirmation message showing how many answers we’ve saved to our CSV.
print(f"Written {len(results)} answers to quora_answers.csv")
Step 6: Executing the Script for Data Collection
At this stage, we’re ready to bring everything together and run our script against a specific Quora question page.
We first configure the WebDriver with ScraperAPI’s proxy for seamless access to Quora, avoiding potential blocks using our configure_selenium_wire_proxy() function, passing our ScraperAPI API Key as an argument.
chrome_options = webdriver.ChromeOptions()
API_KEY = "YOUR_API_KEY"
proxy_options = configure_selenium_wire_proxy(API_KEY)
driver = webdriver.Chrome(options=chrome_options, seleniumwire_options=proxy_options)
We then store our question in a query variable and construct the URL to reach the exact Quora page where this question lives.
We replace spaces in our question with hyphens to match Quora’s URL format, ensuring our WebDriver knows precisely where to go.
query = "What is the easiest way to learn to code?"
driver.get(f"https://www.quora.com/{query.replace(' ', '-')}-q{query.replace(' ', '-')}")
After waiting for the page using time.sleep(100), we execute our scroll_to_bottom() to ensure all dynamically loaded answers are visible.
Next, scrape_answers() collects these answers, and write_to_csv() saves them into a structured CSV file.
time.sleep(100) # Initial wait for page to load
scroll_to_bottom(driver) # Scroll to the bottom of the page
answers = scrape_answers(driver) # Scrape non-ad answers
write_to_csv(answers, query) # Write the answers to a CSV file
We will place everything within a try-except-finally block.
The try block ensures that our script attempts to execute the scraping process, while the except block is there to handle any errors gracefully; we also ensure that the WebDriver is properly closed in the finally clause regardless of the script’s success or failure.
try:
query = "What is the easiest way to learn to code?"
driver.get(f"https://www.quora.com/{query.replace(' ', '-')}-q{query.replace(' ', '-')}")
time.sleep(100)
scroll_to_bottom(driver)
answers = scrape_answers(driver)
write_to_csv(answers, query)
except Exception as e:
print("An error occurred:", e)
finally:
driver.quit() # Ensure the driver is quit properly
Wrapping Up
We’ve done it! We’ve navigated through Quora, using Selenium and ScraperAPI to bypass any hurdles and gather data. Today, we covered:
- Using Python and BeautifulSoup to sift through Quora, extracting useful Q&A data.
- Storing the extracted data in a CSV file, making our analysis straightforward.
- Utilizing ScraperAPI in proxy mode with Selenium Wire, cleverly navigating Quora’s defenses to access public insights.
If you have any questions, please contact our support team; we’re eager to help, or you can check out our documentation to learn more about how to use ScraperAPI effectively.
Need more than 3M API credits a month? Contact sales and get a custom plan with premium support and a dedicated account manager.
Until next time, happy scraping, and remember to scrape responsibly!
Frequently-Asked Questions
Scraping Quora allows you to gather diverse insights and opinions on various topics, which can be invaluable for research, market analysis, and understanding public sentiment.
While Quora does have measures to detect and limit web scraping, using ScraperAPI can help navigate around these blocks effectively.
ScraperAPI uses machine learning and statistical analysis to smartly rotate proxies and headers, handle CAPTCHAs, enable JS rendering, and more, making it easier to access Quora data.
You can use Quora Q&A data to analyze trends, gauge public interest in topics, create content inspiration, and develop targeted marketing strategies based on user questions and answers.