


Optimizing data pipelines with a web scraping proxy built for efficiency and scale is a must – let me tell you why.
Each time you scrape product prices, track market trends, or gather customer reviews, websites:
- Block your IP after detecting repeated requests
- Trigger CAPTCHAs that break your scraper
- Enforce rate limits that slow down data collection
However, effective proxies route your requests through smart IP rotation to mimic human browsing patterns, prevent IP bans and anti-scraping roadblocks, and keep your scraping operations running(even on autopilot). But you must have the right proxy system to get started.
In this guide, we’ll explain proxy mechanics, compare the different types of proxies, and address common challenges vs. solutions to help you build an effective scraping system.
What Is a Web Scraping Proxy?
A web scraping proxy is a specialized proxy designed to support web scraping activities. It functions as an intermediary server between your scraper and the target website.
When a scraper sends requests through a proxy, they are first routed to the proxy server, which then distributes them across multiple IP addresses before reaching the target website. This setup ensures that the target website perceives the requests as originating from different sources rather than a single user.
As a result, your actual IP address and location remain hidden to safeguard your identity and to minimize the risk of detection and blocking.
Why Do You Need to Use Proxies in Web Scraping?
Websites use advanced detection systems that can (potentially) shut down your entire operation. That makes proxies an important tool in your web scraping toolkit. Here’s why you need them:
- Avoid anti-bot systems and IP blocks: Many websites deploy anti-bot systems that block suspicious IP addresses. Proxies distribute requests from multiple IP addresses using smart IP rotation to prevent IP bans. However, be cautious when using free proxies to scale, as they are overused and have a high chance of being blocked.
- Bypass geo-restrictions: You can access geo-restricted content using proxies from specific locations. This helps when websites limit their content based on geography. For precise local data, use location-specific IPs to scrape targeted regions accurately.
- Stay anonymous: Proxies hide all information about you and your device. Your scraping activities stay anonymous, protecting your IP address. The target websites can’t discover or track your actual identity.
- Handle CAPTCHAs: Websites verify human traffic and block automated access through CAPTCHA systems. Proxies generate headers and cookies to simulate real users to avoid triggering a CAPTCHA challenge and ensure high success rates for your project.
- Improve performance and success rates: Proxies reduce errors, blocks, and timeouts on scraping. Proxies let you send multiple requests while maintaining a high success rate. Some proxies even cache data, giving you better performance than direct server connections.
Note: Invest in quality proxies for consistent results. Premium rotating proxies help you switch IP addresses with each request for undetectable scraping. Random free proxies won’t work against advanced anti-bot systems or for large-scale data extraction.
How Do Web Scraping Proxies Work?
Every device connected to the internet has its own IP address, which acts like a physical street address. When your computer connects to a website, the browser uses your IP address to establish the connection to the web server where the website you want to see is hosted. Through this connection, your machine knows where to find the data you want, and the web server knows where to send the data to.
However, when you use a proxy for web scraping:
- You send your get request to the proxy server
- The proxy server forwards the request to the target website using its own IP address
- The website responds with the requested data, usually in HTML or JSON format, without ever getting your real IP
- The proxy server sends you the response it got from the target server
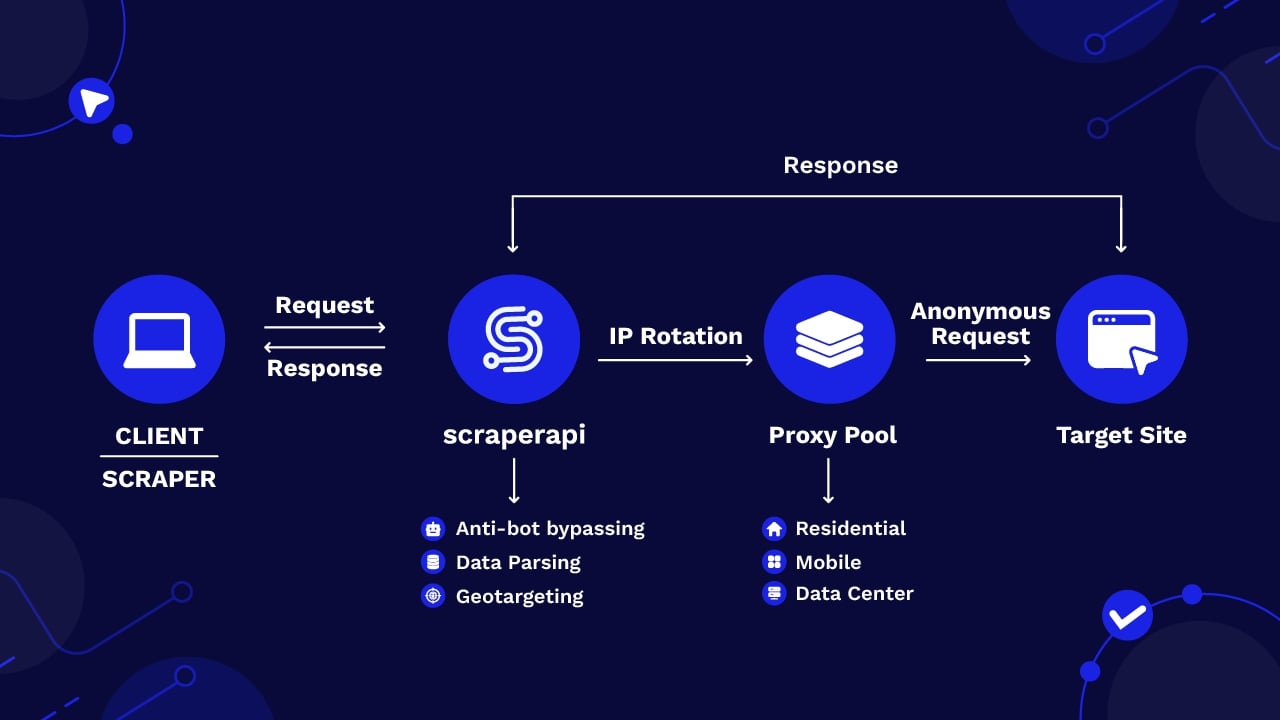
This way, your IP is secure, and your scrapers can access data without the risks of IP-based roadblocks.
Types of Web Scraping Proxies
Let’s explore seven different proxy types to help you make an informed choice for your data collection needs. Each type brings distinct advantages in cost, speed, detection rates, and reliability advantages.
Datacenter Proxies
Datacenter proxies operate through commercial cloud servers instead of internet service providers (ISPs). They’re built for high-volume requests but come with specific risks — websites can detect them through their shared subnetworks and automated patterns.
There are two setups: forward or reverse proxies. Forward proxies hide your identity when sending large volumes of requests to target websites. Reverse proxies protect servers by efficiently managing incoming requests, balancing loads, and caching content.
These proxies specialize in IP range and rotation rather than bandwidth handling. The tradeoff is that datacenter proxies offer speed and accessibility at lower costs. Still, their shared subnetworks make it easier for websites with strict anti-bot systems to detect and block them. You’ll need solid engineering resources to manage proxy rotation and handle blocking rates. Or, choose residential or rotating proxies that offer better anonymity.
Pros
- Fast connection speeds for high-volume scraping
- Lower costs compared to other proxy types
- Reliable performance with consistent uptime
- Work well for large-scale data collection
Cons
- Easy for websites to detect and block
- Share subnet patterns that reveal their datacenter origin
- Limited success against advanced anti-bot systems
- Need manual rotation for new requests
Best Use Cases
- Web scraping from sites with basic security
- Price monitoring across e-commerce sites
- SEO tracking and competitor analysis
- App testing across different locations
- Purchasing limited-supply products at scale
If you’re considering datacenter proxies for web scraping, check out our guide on the 10 Best Datacenter Proxies Worth Buying to find the most reliable options for your needs.
Residential Proxies
Residential proxies operate through IP addresses tied to actual household devices and internet service providers (ISPs), who lease them from real users with residential addresses. When websites receive your requests, they see them coming from legitimate home networks instead of commercial servers. That’s why websites rarely flag or block residential IPs.
Even with strict anti-bot measures, your scraping activities maintain high success rates. If blocks occur, you can switch to fresh IPs instantly and ensure uninterrupted data collection.
Despite higher costs than datacenter options, residential proxies offer minimal engineering overhead because of their high trust score.
Note: Excessive activity like rapid-fire requests or identical user-agent strings can still trigger suspicion and lead to CAPTCHA challenges or IP bans. To maintain access, you must simulate human-like behavior by varying your request patterns and user-agent headers.
Pros
- High success rates on websites with anti-scraping measures
- Access to location-specific content worldwide
- Natural traffic patterns that avoid detection
- Large pool of IPs available for consistent access
Cons
- Higher costs than datacenter proxies
- Slower speeds due to residential connections
- IP availability varies by geographic region
- Potential connection stability issues
Best Use Cases
- YouTube large-volume video extraction
- E-commerce price monitoring
- Ad verification across regions
- Social media multiple account management
- Accessing geo-restricted content
- Stock market research
Also read: What Are Residential Proxies & Why Use Them for Scraping?
Static Proxies
Static proxies give you a single IP address that stays with you throughout your connection — that’s why they’re also called “sticky proxies.” Your session with one IP can last from 5 minutes to 45 minutes or longer, and once you own the IP, it’s yours for its lifetime.
When you connect through a static proxy, your request goes through an intermediary server that links to websites with a separate IP address. There’s no need for gateway servers, hence the higher speeds and improved stability compared to rotating proxies.
Data centers and ISPs sell or lease these proxies at lower prices. However, since each IP comes from one geographical location, access to geo-restricted content is limited.
Sending multiple requests through the same IP address can quickly lead to bans during large-scale data collection. Since static proxies don’t originate from ISPs like residential ones, websites can easily identify and block them.
Pros
- Faster speeds than rotating proxies
- Stable, uninterrupted connections
- Natural user behavior simulation
- Lower costs than rotating options
Cons
- Higher risk of blocking during heavy use
- Limited to single-location data
- Easier for websites to detect
- Not suitable for large-scale scraping
Best Use Cases
- Shopping cart and checkout operations
- Region-specific marketing research
- Security penetration testing and vulnerability scanning
- Platform algorithm analysis
- Location-specific content analysis for advertising
Rotating Proxies
Rotating proxies automatically assign you new IP addresses with each connection request or after set intervals. The system works differently from static proxies. For example, when you connect to a static proxy, your entire session depends on that single IP not getting blocked. But rotating proxies keep assigning fresh IPs throughout your session.
It works great when there’s a demand for consistent anonymity. The constant IP changes make it harder for servers to track and block users. You’re not limited to one region — proxy providers maintain diverse IP pools across global locations. This lets you route requests through different countries as needed.
These proxies are great for bypassing CAPTCHA challenges and accessing well-protected websites. They reduce malware attack risks through constant IP changes. But, for tasks that need stable user sessions, static proxies serve better.
Pros
- Simple configuration across programming languages
- Strong protection against IP bans
- Global proxy pools for worldwide access
- Flexible scaling options
- Enhanced security against tracking
Cons
- Slower speeds from constant rotation
- Incompatible with session-based tasks
- Premium pricing for IP pool access
- Connection stability challenges
Best Use Cases
- Data scraping for big data projects
- Market research across multiple regions
- Competitive analysis and pricing data collection
- SEO monitoring and keyword analysis
- Website evaluation without search bias
To learn more about proxy rotation and how it enhances anonymity, check out our guide on What Are Rotating Proxies? (Functions, Types, and Security).
Mobile Proxies
Mobile proxies use IPs assigned by mobile network towers. Each device gets a dynamic IP address that rotates automatically through mobile carriers. These proxies work through gateway software on devices through IPs that belong to mobile data networks. When a mobile device connects to a cell tower, it receives an available IP from that network.
While the IPs aren’t unique, this works favorably for users looking to hide their online intentions. You can use mobile proxies from any device with mobile hardware that reads SIM cards, like mobile dongles — not just phones or tablets.
They’re particularly effective on social media platforms, letting you manage multiple users without triggering restrictions. Mobile proxies enable access to region-specific content and mask automated activities like commenting and liking, making them appear as actions from different users.
Mobile IPs are unnecessary for most web scraping projects unless you specifically need to see results shown to users with mobile devices. They raise legal concerns since device owners often don’t know their GSM networks are being used for web scraping.
Pros
- High legitimacy from real mobile IPs
- Lower blocking rates on mobile sites
- Automatic IP rotation
- Effective for avoiding verification prompts
Cons
- Higher costs than other proxy types
- Slower speeds on mobile networks
- Performance issues in large-scale scraping
- Shared IPs (often between multiple users) affect reliability
Best Use Cases
- Social media account management
- Mobile-specific content access
- Ad verification across regions
- Brand protection monitoring
- Online privacy enhancement
Check out our list of Our Favorite Mobile Proxy Providers for Web Scraping for even more mobile proxy options.
Shared Proxies
Shared proxies distribute IP addresses among multiple users through a common pool. These proxies are an entry point if you start with web scraping or basic data collection. You can use them in two ways:
- Static IP lists: You get specific IPs to use one at a time. You control which IP to use but must switch manually.
- Rotating pools: You connect through a gateway that automatically switches IPs. This offers better automation but less control.
These proxies run on commercial datacenters, making them cost-effective for basic web access and small-scale operations. They’re much cheaper than dedicated proxies but come with notable performance tradeoffs.
Shared datacenter proxies cost 10-20 times less per GB than residential proxies. They offer enough functionality for basic tasks at a fraction of dedicated proxy prices. But your performance suffers when other users misuse the IPs or overload the bandwidth.
Pros
- Lowest cost option among all proxy types
- Basic anonymity protection
- Access to global IP locations
- Simple setup for beginners
Cons
- Slower speeds because of bandwidth sharing
- Higher risk of IP bans from other users
- Frequent CAPTCHAs on popular sites
- Unreliable connections
Best Use Cases
- Basic data collection from simple websites
- Content aggregation for news and pricing
- Testing geo-restricted content access
- Personal web browsing anonymity
Dedicated
Dedicated proxies assign exclusive IP addresses to a single user. You get complete control over unused IPs without sharing bandwidth or resources with others. While they cost more than shared proxies, they deliver better performance for intensive web tasks and data collection.
Your IP pool size directly affects location access. For example, 20 dedicated proxies give you access to 20 locations maximum, while buying 10 proxies for 20 different locations means purchasing 200.
Exclusive access means websites can’t find historical records of your IPs in public databases. This improves your chances of avoiding blocks when following proper anti-detection practices. But, websites can still detect and block these IPs if they spot automated behavior or excessive API requests.
The proxy management requires manual configuration — you must monitor IP health, implement rotation schedules, and whitelist IPs yourself.
Pros
- Full bandwidth and speed access
- Reliable proxy performance
- Fresh, unused IP addresses
- Better equipped to avoid IP blocking
Cons
- Higher costs per IP and bandwidth
- Smaller IP address pool
- Complex to configure
- Limited location availability
- Manual proxy management
Best use cases
- E-commerce website scraping
- Non-Google search engine data collection
- Limited edition product purchases
- Projects needing stable IP identities
- High-volume data extraction
How to Choose the Right Web Scraping Proxy
This comparison helps you pick the best proxy for your specific needs:
| Proxy Type | Best For | Highlight | Drawback |
|---|---|---|---|
Datacenter | Large-scale non-sensitive data scraping | Fast processing, consistent uptime | Gets blocked by anti-bot systems |
Residential | Intensive data scraping from secured sites | High success on protected websites | High cost, needs IP management |
Static | Basic data extraction with fixed IP | Stable single-IP connection | Blocks during repeated requests |
| Mobile | Mobile-specific content collection | Real mobile network IPs | Expensive, slower performance |
Rotating | Bypassing strict anti-scraping blocks | Auto IP rotation | Complex setup, unstable connections |
| Shared | Testing and small scraping projects | Low entry cost | Frequent blocks, slow speeds |
| Dedicated | Medium-scale structured scraping | Complete IP control | Needs technical expertise |
Consider these factors:
- Request volume: Calculate your total number of requests per minute and assess website size. Large sites with strict anti-scraping measures need bigger proxy pools. Adjust your proxy count accordingly if you target 500 requests per 10 minutes. More pages and stronger website security require more proxies.
- IP quality: Choose between residential, dedicated, or shared proxy IPs based on your needs. Residential IPs offer the highest success rates and lowest detection risk. Dedicated IPs provide better performance than shared ones. Low-quality IPs get detected and blocked faster, disrupting your scraping operations.
- Geographic coverage: Verify that the proxy service’s location coverage matches your target regions. Some providers offer precise targeting down to ZIP codes—regional coverage matters for accessing location-restricted content and gathering accurate local data without blocks.
- Bandwidth and speed: Check provider bandwidth limits, latency rates, and transfer speeds. Higher bandwidth enables faster data collection in large-scale projects. Poor network performance slows down or stops web scraping activities. So test connection stability before committing to a provider.
- Cost structure: Compare pricing models to find the best fit for your needs. Fixed plans are ideal for consistent scraping, offering set data allowances like 5GB or 300GB per month. If you scrape infrequently, a pay-as-you-go model may be more cost-effective. Remember to account for bandwidth fees and the number of IPs required when calculating your total budget.
- Higher-quality proxies and scraping APIs cost more but reduce blocks.
- Provider support: Select providers with round-the-clock technical support. You need immediate help when scraping operations face issues. Check their technical documentation and troubleshooting guidance. Provider reliability affects your scraping success rates.
Common Challenges When Using Proxies and How to Solve Them
Let’s look at some challenges to be cautious of when using web scraping proxy solutions.
Scalability
Building your web scraping setup can be challenging when you need massive competitor and customer data to stay competitive. Price changes, market shifts, customer trends — the data keeps growing. You’ll need the best software, hardware, and constant maintenance. Small businesses often struggle with infrastructure costs and technical demands, and most companies can’t justify the expense of an in-house system.
How to fix it: Switch to web scraping solutions built for scale. These platforms handle high request volumes and process data at speed. You can connect their APIs to your current system and start collecting web data immediately. The infrastructure runs in the background while you focus on using the data.
Dynamic Content
Your target websites use AJAX to load content. This means that content appears as users scroll the page, and the first HTML load misses this dynamic data. Websites also add delays to check if browsers can handle JavaScript content. If your scraper fails this check, the site marks it as a bot and blocks access.
How to fix it: Pick tools that handle JavaScript content. Playwright, Puppeteer, and Selenium work well for web automation. These tools act like real browsers; they load dynamic content and pass website checks. Your scraper can then collect data from infinite scroll web pages and delayed-load sections.
CAPTCHA
CAPTCHAs block bots by asking users to complete tasks. These can include image selection, text reading, or puzzles. Modern CAPTCHAs like reCAPTCHA v3 check user behavior on the website. All these checks make it tough for your scraper to get through.
How to fix it: Use tools powered by Artificial Intelligence (AI) and Machine Learning (ML) to handle different CAPTCHA types. They spot the CAPTCHA type and handle it fast. But remember, websites use CAPTCHAs to protect their data. So, check the website’s terms of service before you start scraping.
Legal and Ethical Issues
Web scraping has multiple legal boundaries: Copyright laws protect website content, Terms of service set rules for data collection, and GDPR and CCPA demand careful handling of personal data. And most platforms act against violations; for example, LinkedIn sued a company for scraping data from user profiles without consent.
How to fix it: Collect specific data you have a clear legal right to use. Run your scraper at speeds that won’t harm website servers, and watch for changes in data protection rules in your target regions. Most importantly, get legal guidance to protect your business from costly mistakes.
Page Structure Changes
Website layout changes and updates happen without warning — a site redesign can make your scraper stop working. Parsers are built with specific HTML paths, but website changes make these paths useless. The content stays the same, but your scraper won’t be able to find it.
How to fix it: Make sure parsers focus on content instead of the exact page layout. Or set up tests to alert you when page structures change. Keep track of errors to spot patterns and update your scraper scripts when such changes occur.
Wrapping Up: Choosing the Best Web Scraping Proxy
As we’ve seen, web scraping gives you options but comes with challenges, too. Once you understand what it takes to build a web scraping proxy system, choose your options based on your needs. The right proxy infrastructure lets you focus on data instead of technical hurdles.
ScraperAPI makes web scraping simple with
- 90M+ residential, mobile, and datacenter proxies across 200+ countries
- Smart routing to prevent IP bans and maintain high success rates
- Specialized proxy pools for eCommerce, search engines, and social media
- Built-in CAPTCHA solving and browser emulation
- 99.9% uptime guarantee with unlimited bandwidth
- Scheduled and asynchronous scraping options
The platform routes requests through different subnets and adjusts throttling automatically to keep your scraping smooth. Sign up with ScraperAPI for free and get 5,000 API credits right away.
FAQ
1. Is proxy or VPN better for web scraping?
Proxies outperform VPNs for web scraping because they operate at the application layer with IP rotation and better request handling. This makes data collection faster and more reliable than VPNs that work at the network layer with limited IP switching options.
2. Can you get IP banned for web scraping?
Yes, websites ban IPs when they spot aggressive scraping patterns. Too many requests, automated behavior, and unusual traffic patterns trigger security blocks. You can use proxy rotation and rate limiting to maintain natural request patterns and avoid bans.
3. What is the fastest proxy scraper?
ScraperAPI delivers fast scraping through smart IP rotation and CAPTCHA handling. The proxy network spans datacenter, residential, and mobile proxies with unlimited bandwidth and geolocation targeting. You get reliable speed without managing complex proxy infrastructure.