


ChatGPT web scraping is changing the way people extract data from web pages. Whether you’re gathering insights for market research, tracking competitors, or automating tedious tasks, web scraping is an incredibly powerful tool. But if you’re not an experienced coder, building a scraper from scratch can feel overwhelming. That’s where ChatGPT comes in.
With the proper prompts, ChatGPT can help you generate Python scripts, refine your scraping code, and even troubleshoot errors along the way. In this step-by-step guide, I’ll walk you through using ChatGPT to build a basic web scraper, enhance it with features like pagination and CSV file exports, and tackle common challenges.
By the end, you’ll have a solid grasp of leveraging ChatGPT web scraping to automate your data collection workflow.
Let’s dive in!
Why Use ChatGPT for Web Scraping?
If you’ve ever tried to scrape websites manually, you know it can be time-consuming and technical. Writing the code, handling HTML content, managing pagination, and troubleshooting errors—it all adds up. ChatGPT makes this easier by generating Python scripts, refining your scraping process, and suggesting fixes when things break.
Here’s why ChatGPT web scraping is worth considering:
1. Generates Code in Seconds
Instead of starting from scratch, you can ask ChatGPT to generate a web scraping script using Python and libraries like BeautifulSoup or Selenium. Just describe what you need—extracting product details, collecting article headlines, or gathering social media posts—and ChatGPT will provide the generated code in seconds.
2. Helps Debug Errors
Web scraping scripts often break due to HTML structure changes, missing elements, or rate limiting by the target website. When that happens, instead of spending hours debugging, you can paste the error message into ChatGPT, and it will suggest solutions.
3. Optimizes Your Scraping Workflow
Need to scrape data from multiple web pages? ChatGPT can modify your script to handle pagination, filter specific elements using CSS selectors, and even save the extracted data to a CSV file or JSON format.
4. Works with APIs and Proxies
Many websites block scrapers, requiring access to CAPTCHAs, proxies, or an official API. ChatGPT can guide you on integrating tools like ScraperAPI to avoid getting blocked and ensure smooth data extraction.
5. Great for Beginners and Experts
ChatGPT makes it easy to get started if you’re new to web scraping. If you’re an experienced developer, it can save time by speeding up script creation, troubleshooting, and optimization.
How to Use ChatGPT for Web Scraping (Step-by-Step Tutorial with Books to Scrape)
Now, let’s build a real web scraper using ChatGPT and Python.
Project Requirements
Before we start, there are a few things you need to have set up.
1. Create an OpenAI Account
Since we’ll be using ChatGPT to generate and refine our scraping script, you’ll need an OpenAI account to access ChatGPT. If you haven’t already:
- Go to OpenAI’s website and sign up.
- Consider using the paid version (GPT-4 Turbo or later) for more accurate and advanced responses if possible.
Once you have access, you can start chatting with ChatGPT using the web app.
2. Install Python and Required Libraries
Ensure you have Python installed on your system. If you’re unsure, run the following command to check:
python --version
If you don’t have it installed, download the latest version from the official Python website.
Next, install the required libraries for web scraping:
pip install beautifulsoup4 requests
These libraries will allow your script to:
- Send HTTP requests to retrieve web pages (
requests). - Parse and extract data from HTML (
BeautifulSoup).
Now that you have everything set up, let’s get started!
Step 1: Inspect the Website’s HTML Structure to Craft a Detailed ChatGPT Prompt
A clear and detailed prompt is key to getting accurate and functional code when using ChatGPT for web scraping. The more specific your prompt, the better ChatGPT’s response will be. Before asking ChatGPT to generate a web scraping script, you must understand how the data is structured on the page.
How to Inspect the HTML
- Open the Books to Scrape website in your browser.
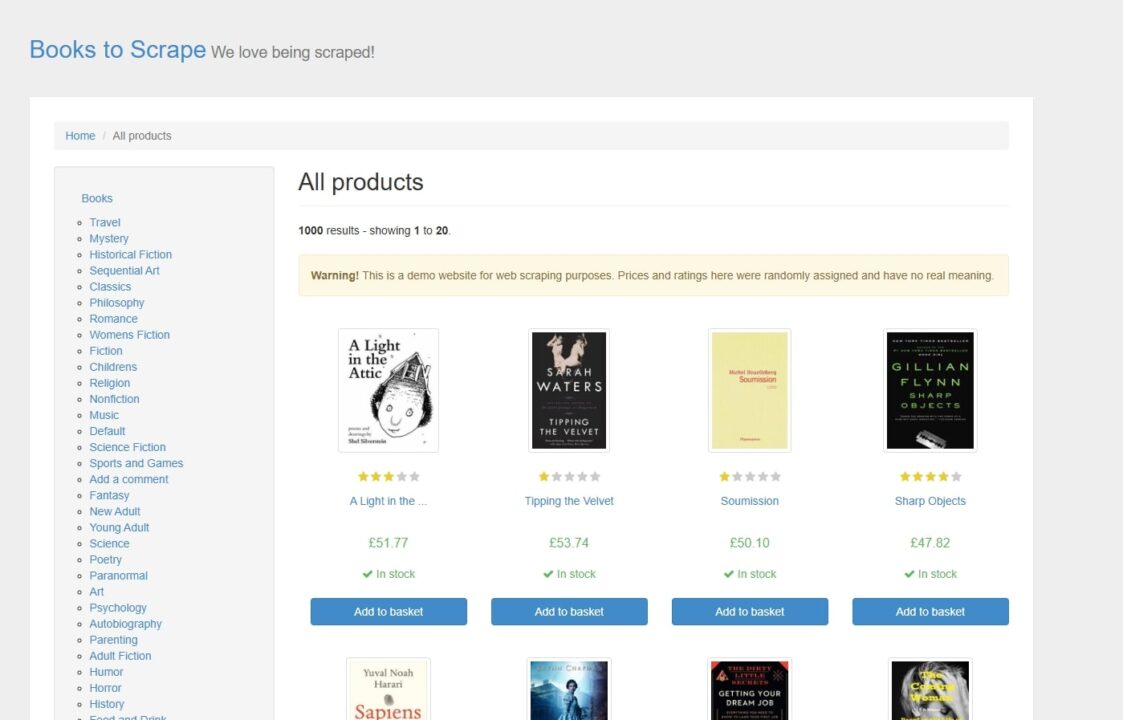
- Right-click on a book title and select Inspect to open Developer Tools.
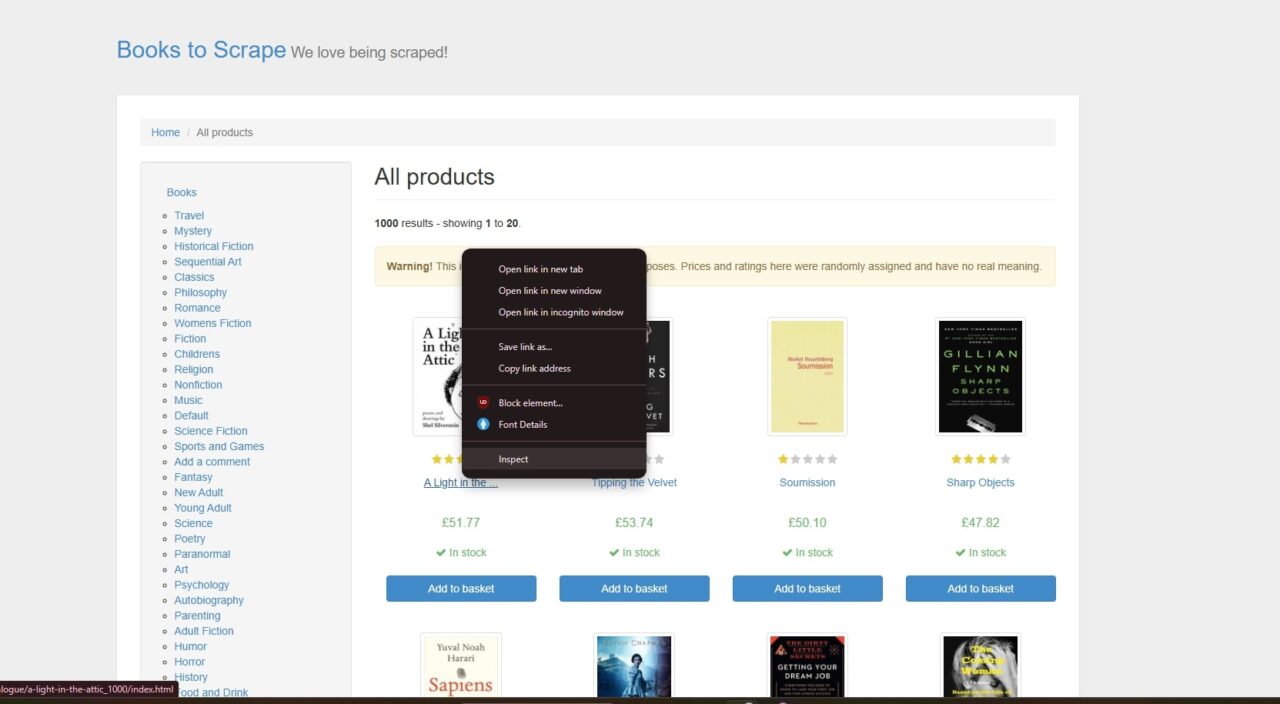
- Look at the HTML structure to see where the title, price, availability, and link are located.
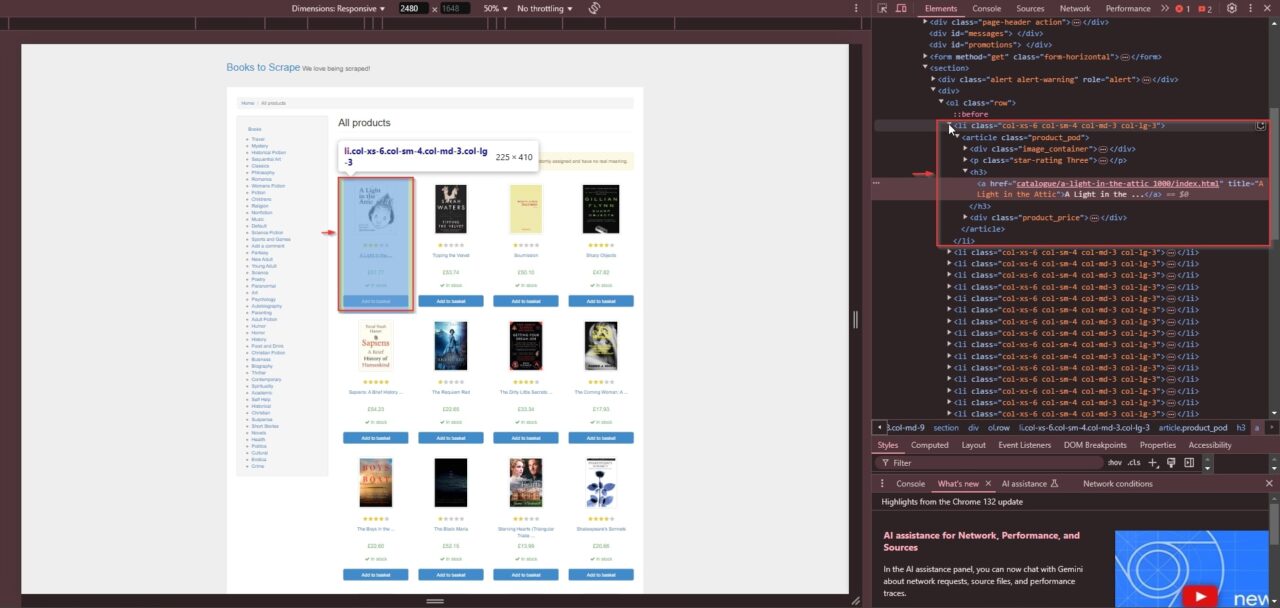
Each book entry follows this structure:
<li class="col-xs-6 col-sm-4 col-md-3 col-lg-3">
<article class="product_pod">
<div class="image_container">
<!-- Book cover image -->
</div>
<p class="star-rating Three">
<!-- Star rating -->
</p>
<h3>
<a href="catalogue/a-light-in-the-attic_1000/index.html"
title="A Light in the Attic">A Light in the ...</a>
</h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<p class="instock availability">
In stock
</p>
</div>
<form>...</form>
</article>
</li>
From this, you can see:
- The book title is inside the
<a>tag’stitleattribute. - The book URL is inside the
<a>tag’shrefattribute (a relative link). - The price is inside the
<p>tag with the class"price_color". - The stock availability is inside the
<p>tag with the"instock availability"class.
Now that you know where the data is, you can describe it clearly to ChatGPT in your prompt.
Step 2: Writing a Clear Prompt for ChatGPT
To get ChatGPT to generate a working web scraping script, you need to give it a clear and detailed prompt. ChatGPT might return a script that misses important data or doesn’t work correctly if the prompt is too vague.
The goal here is simple: write a prompt that tells ChatGPT precisely what you want so it generates the correct code the first time.
Let’s start by looking at a bad example.
“Write a Python script to scrape book data from books.toscrape.com.”
If you enter this into ChatGPT, it will return something, but there’s no guarantee the script will extract the correct data. It doesn’t specify which details to scrape, how to structure the output, or any formatting rules.
Instead, let’s give ChatGPT all the necessary details. Since we already inspected the HTML, we know exactly where the book title, link, price, and availability are located. So, we’ll include that information in our prompt.
“Write a Python script using BeautifulSoup and Requests to scrape book data from books.toscrape.com. The script should extract the following details for each book on the first page:
- Book title: Inside an
<a>tag within an<h3>tag. The title is stored in thetitleattribute. - Book URL: The
hrefattribute inside the same<a>tag. This is a relative link and should be combined withhttps://books.toscrape.com/to create a full URL. - Price: Found inside a
<p>tag with the class"price_color". - Stock availability: Found inside a
<p>tag with the class"instock availability".
Format the output as a printed list where each book’s details are displayed clearly.”
This version is much better. It tells ChatGPT precisely what to look for, where to find it, and how to structure the output.
Now, enter this prompt into ChatGPT and see what it generates. It should return a script similar to this:
import requests
from bs4 import BeautifulSoup
# Base URL of the website
base_url = "https://books.toscrape.com/"
# Send a GET request to fetch the HTML content
response = requests.get(base_url)
soup = BeautifulSoup(response.text, "html.parser")
# Find all book entries on the page
books = soup.find_all("article", class_="product_pod")
# Loop through each book and extract relevant details
for book in books:
title = book.h3.a["title"]
relative_link = book.h3.a["href"]
full_link = base_url + relative_link # Convert relative link to full URL
price = book.find("p", class_="price_color").text.strip()
availability = book.find("p", class_="instock availability").text.strip()
print(f"Title: {title}")
print(f"Link: {full_link}")
print(f"Price: {price}")
print(f"Availability: {availability}")
print("-" * 50)
Now, let’s test it. Copy this script into a Python file and run it. If everything is correct, you should see a list of books with their titles, prices, availability, and links.
If something isn’t working as expected, don’t panic. You can refine your prompt. For example, if the book URLs aren’t displaying correctly, try telling ChatGPT:
“Modify the script to correctly append the base URL to the relative book links before printing them.”
ChatGPT will recognize the issue and return a fixed version of the script.
Following this process, you guide ChatGPT step by step, ensuring the script does exactly what you need.
Step 3: Prompting ChatGPT to Scrape Multiple Pages
The script only scrapes the first page of books right now, but that’s not enough. Books to Scrape has multiple pages, and if you want to collect all the data, you need to modify the script so it loops through every page automatically.
Instead of manually figuring it out, you can ask ChatGPT to do it for you. But, as before, a vague prompt won’t give you the best results.
Let’s take a look at a bad example:
“Modify the script to scrape all pages.”
This doesn’t tell ChatGPT how pagination works or when to stop scraping. It might return a script that assumes an incorrect page structure or doesn’t handle missing pages properly.
Since we already analyzed the website, we know how the pagination works. Each page follows this pattern:
https://books.toscrape.com/catalogue/page-1.html
https://books.toscrape.com/catalogue/page-2.html
https://books.toscrape.com/catalogue/page-3.html
...
Now, we can write a much better prompt:
“Modify the script to scrape all pages of books.toscrape.com by handling pagination. Each page follows this pattern: https://books.toscrape.com/catalogue/page-1.html, https://books.toscrape.com/catalogue/page-2.html, etc. The script should continue scraping until it reaches a page that doesn’t exist. Keep the output format the same.”
Paste this into ChatGPT and let it generate the updated script. You should get something like this:
import requests
from bs4 import BeautifulSoup
# Base URL pattern for pagination
base_url = "https://books.toscrape.com/catalogue/page-{}.html"
page = 1 # Start from page 1
while True:
url = base_url.format(page)
response = requests.get(url)
# Stop if the page does not exist
if response.status_code != 200:
break
soup = BeautifulSoup(response.text, "html.parser")
books = soup.find_all("article", class_="product_pod")
for book in books:
title = book.h3.a["title"]
relative_link = book.h3.a["href"]
full_link = "https://books.toscrape.com/" + relative_link
price = book.find("p", class_="price_color").text.strip()
availability = book.find("p", class_="instock availability").text.strip()
print(f"Title: {title}")
print(f"Link: {full_link}")
print(f"Price: {price}")
print(f"Availability: {availability}")
print("-" * 50)
page += 1 # Move to the next page
When you run the script, it will automatically loop through all pages and stop when no more books are left. There is no need to change the page number manually.
You can refine your prompt again if the script isn’t working as expected. For example, if it’s stopping too soon, you could ask:
“The script stops before reaching the last page. Modify it so it checks if the page exists before stopping.”
ChatGPT will return an improved version that ensures all pages are scraped.
At this point, you now have a fully functional multi-page scraper. The next step is to modify the script to save the data into a file instead of just printing it.
Step 4: Saving the Scraped Data to a File
Instead of printing the scraped data, we’ll save it in a CSV file for easy access. To do this, we’ll ask ChatGPT to modify our script using the following prompt:
“Modify the script to save the scraped book data into a CSV file called books.csv, with columns for Title, Link, Price, and Availability.”
After entering this into ChatGPT, it should return a script like this:
import requests
from bs4 import BeautifulSoup
import csv
base_url = "https://books.toscrape.com/catalogue/page-{}.html"
with open("books.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["Title", "Link", "Price", "Availability"])
page = 1
while True:
url = base_url.format(page)
response = requests.get(url)
if response.status_code != 200:
break
soup = BeautifulSoup(response.text, "html.parser")
books = soup.find_all("article", class_="product_pod")
for book in books:
title = book.h3.a["title"]
relative_link = book.h3.a["href"]
full_link = "https://books.toscrape.com/" + relative_link
price = book.find("p", class_="price_color").text.strip()
availability = book.find("p", class_="instock availability").text.strip()
writer.writerow([title, full_link, price, availability])
page += 1
print("Scraping complete. Data saved to books.csv")
When you run the script, it will scrape all pages and store the data in books.csv, making it easy to open in Excel or other tools.
Step 5: Debugging and Avoiding Blocks
Sometimes, web scraping doesn’t go as planned. Your script might stop working, return empty data, or even get blocked. Instead of digging through error messages, you can use ChatGPT to troubleshoot and improve your scraper.
Let’s say you run the script and get a 403 Forbidden error—a sign that the website is blocking your requests. You can ask ChatGPT:
“My script is getting a 403 Forbidden error when trying to scrape books.toscrape.com. How can I fix it?”
ChatGPT will likely suggest adding headers to make your script look like a real browser:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
response = requests.get(url, headers=headers)
If the site is blocking multiple requests or using CAPTCHAs, you can ask:
“Modify the script to use ScraperAPI to avoid getting blocked.”
ChatGPT will update the script to route requests through ScraperAPI, which helps bypass restrictions:
api_key = "your_scraperapi_key"
url = f"https://api.scraperapi.com/?api_key={api_key}&url={base_url.format(page)}"
response = requests.get(url)
By asking ChatGPT the right questions, you can quickly debug issues and improve your scraper without spending hours troubleshooting!
Best Practices for Using ChatGPT for Web Scraping
Using ChatGPT for web scraping goes beyond just asking for a script. The real value comes from how you use it to refine, troubleshoot, and optimize your approach. Here are some ways to genuinely improve how you leverage ChatGPT for web scraping:
1. Don’t Just Generate Code—Ask for Explanations
ChatGPT can produce working code, but mindlessly copying and pasting it without understanding how it works is a mistake. Instead of just asking for a scraper, take the time to ask why ChatGPT made confident choices. For example, ask about the difference if it selects elements using .find() instead of .select_one(). If it suggests requests.get(), ask if a session would improve efficiency. Treat ChatGPT as a teacher, not just a code generator—this will help you spot issues faster and adapt scripts when sites change.
2. Ask for Edge Case Handling
A common issue with AI-generated scrapers is that they assume perfect conditions—but real-world data is rarely perfect. Many scripts fail if an element is missing, a page is slow to load, or the structure is slightly different.
Before running the script, ask ChatGPT how to handle edge cases, such as:
- What happens if the price or availability field is missing?
- How should the script behave if a request fails or returns a 403 error?
- What if pagination works differently on some pages?
3. Verify the HTML Yourself
ChatGPT can infer a website’s structure based on your description, but it does not browse it. If your script isn’t working, the issue may not be the code itself but an incorrect assumption about the HTML structure.
Instead of relying entirely on ChatGPT’s interpretation, open Developer Tools in your browser, inspect the elements manually, and cross-check them with the generated script. This is especially important for sites with dynamically loaded content, where data might not be present in the initial HTML response.
4. Use ChatGPT to Compare Different Scraping Approaches
There are multiple ways to extract data from a website, and ChatGPT can help you evaluate which method is the best fit. Instead of defaulting to requests and BeautifulSoup, ask ChatGPT to compare different approaches, such as:
- Scrapy vs. BeautifulSoup for large-scale data extraction.
- Selenium vs. Playwright for handling JavaScript-heavy sites.
- API extraction vs. direct HTML scraping if an API is available.
ChatGPT can break down the trade-offs, such as speed, complexity, and reliability, helping you choose the most efficient method for your specific use case.
5. Use the Paid Version for More Accurate and Advanced Results
If you’re using ChatGPT frequently for technical tasks like web scraping, upgrading to the paid version (GPT-4 Turbo or later) can be a worthwhile investment. The paid version offers:
- More accurate and complex code generation, reducing errors and the need for fixes.
- Better long-form memory, meaning it can keep track of previous refinements in your scraper.
- Faster responses, which speeds up debugging and optimization.
While the free version is helpful for basic tasks, the paid version can save time and improve efficiency if you work on large-scale scraping projects or need consistently high-quality output.
Limitations of ChatGPT for Web Scraping
ChatGPT is a powerful tool for generating web scraping scripts, but it has limitations. Since it doesn’t run or test code, the scripts it produces may contain errors, outdated methods, or incorrect selectors. You’ll need to test and refine the code before using it.
Another challenge is the lack of real-time web awareness. ChatGPT can’t detect changes in a website’s structure, verify if an API is still active, or ensure a scraping method will work. Websites update frequently, so manual inspection is necessary to keep scrapers functional.
Many sites use anti-scraping protections like CAPTCHAs, IP blocks, and request rate limits. A basic requests and BeautifulSoup scraper may get blocked quickly. For protected sites, tools like ScraperAPI can help bypass CAPTCHAs, manage proxies, and prevent detection.
Scalability is another factor. While ChatGPT-generated scripts are fine for small projects, scraping thousands of pages requires optimizations like asynchronous requests, distributed crawlers, and efficient data storage solutions.
Finally, legal and ethical considerations are your responsibility. ChatGPT won’t verify if a site allows scraping or if specific data is restricted. Always check robots.txt, review terms of service, and follow best practices.
ChatGPT is a great starting point, but you’ll need hands-on solutions for real-world scraping challenges. Check out our guide on scraping dynamic websites with Python and explore our blog for in-depth tutorials and advanced scraping techniques.
Happy scraping!
FAQ about Using ChatGPT for Web Scraping
No, ChatGPT cannot directly scrape websites. It can generate Python scripts using libraries like requests, BeautifulSoup, and Selenium to help automate web scraping, but you must run the code yourself.
Not by default. Websites can track your IP address, browser fingerprint, and request patterns. Without proper precautions, your scraping activity can be detected and blocked.
To maintain anonymity, use rotating proxies or a VPN to mask your IP address, set custom headers and user agents to mimic real browsers, and introduce randomized delays between requests to avoid detection. Using headless browsers like Selenium can also help simulate human behavior.
No official ChatGPT plugin exists for web scraping, but you can use ChatGPT to generate and refine scraping scripts. For automated web scraping, consider tools like ScraperAPI or Scrapy for large-scale data extraction.