


Here’s how to scrape Alibaba product data using Python and ScraperAP; but before getting started, let’s understand what Alibaba is and how you can benefit from the extracted dataset.
Alibaba offers millions of products across 40+ product categories, making it easily one of the biggest ecommerce marketplaces in the world and one of the best resources for businesses and analysts to gather product data at scale.
By the end of this tutorial, you will be able to extract valuable information such as product details, prices, and descriptions from Alibaba with Python, which you can further use to make informed business and marketing decisions.
TL; DR: Full Alibaba Python Scraper
For those in a hurry, here’s the scraper we’ll build in real time during this tutorial:
import requests
from bs4 import BeautifulSoup
import json
API_KEY = "Api_Key"
base_url = "https://www.alibaba.com/trade/search"
# Format search query based on user input
def format_search_query(user_input):
# Replace spaces with '+' and encode the query
formatted_query = "+".join(user_input.split())
return formatted_query
# User input for the product search
user_input = input("Enter the product you want to search for: ")
# Format the search query
search_query = format_search_query(user_input)
# List to hold the scraped data
product_data_list = []
# Loop through the first 5 pages
for page in range(1, 6):
# Construct the URL for each page
url = f"{base_url}?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&searchText={search_query}&page={page}"
print(f"Currently scraping page {page}... \n")
# Parameters for the ScraperAPI request
payload = {"api_key": API_KEY, "url": url}
# Make a request to the ScraperAPI
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
# Parse the HTML response using BeautifulSoup
soup = BeautifulSoup(html_response, "lxml")
# Find all product containers on the page
product_containers = soup.find_all("div", class_="search-card-info__wrapper")
# Iterate through each product container on the current page
for product_container in product_containers:
# Extract product name
product_name_element = product_container.select_one(
".search-card-e-title a span"
)
product_name = (
product_name_element.text.strip() if product_name_element else "nil"
)
# Extract price
price_element = product_container.select_one(".search-card-e-price-main")
price = price_element.text.strip() if price_element else "nil"
# Extract description
description_element = product_container.select_one(".search-card-e-sell-point")
description = description_element.text.strip() if description_element else "nil"
# Extract MOQ (Minimum Order Quantity)
moq_element = product_container.select_one(".search-card-m-sale-features__item")
moq = moq_element.text.strip() if moq_element else "nil"
# Extract rating
rating_element = product_container.select_one(".search-card-e-review strong")
rating = rating_element.text.strip() if rating_element else "nil"
product_data = {
"Product Name": product_name,
"Price": price,
"Description": description,
"MOQ": moq,
"Rating": rating,
}
# Append the product data to the list
product_data_list.append(product_data)
# Save the scraped data to a JSON file
output_file = "alibaba_results.json"
with open(output_file, "w", encoding="utf-8") as json_file:
json.dump(product_data_list, json_file, indent=2)
print(f"Scraped data has been saved to {output_file}")
In this iteration, we’re sending our requests through ScraperAPI to bypass Alibaba’s anti-scraping mechanisms and manage the technical difficulties when expanding the project.
Note: Substitute API_KEY in the code with your actual ScraperAPI API key.
Just for simplicity’s sake, we’ve built this script to run as an application. It’ll ask you what product you’d like to scrape information from before running the scraping job.
Scraping Alibaba with Python
In this tutorial, we’ll build an Alibaba scraper to collect the following product information:
- Product Name
- Price
- Product description
- Rating
- ( M.O.Q. ) Minimum Order Quantity
That said, let’s get started!
Prerequisites
For this project, you’ll need:
- Python 3.8+
- Requests
- BeautifulSoup
- Lxml
You can easily install them with the following command:
pip install requests beautifulsoup4 lxml
In addition, you’ll need to create a new ScraperAPI account. This is needed to bypass Alibaba’s ecommerce website anti-scraping mechanisms and prevent our IP from getting banned from the site.
Note: You’ll get 5,000 free API credits to test all our tools.
Step 1: Setting Up Your Project
To set up your project, run the following commands on your terminal:
mkdir alibaba-scraper
cd alibaba-scraper
- The first line creates a directory named alibaba–scrapper
- The second one changes the terminal to the project directory
Inside the project’s folder, create a main.py file, which will contain the logic of our scraper, and import our Python libraries at the top.
import requests
from bs4 import BeautifulSoup
import json
Step 2: Define your ScraperAPI Key and the Alibaba URL
To send our request through ScraperAPI, we’ll need two things:
- Specify our API key
- Specify the page URL we want to scrape
import requests
from bs4 import BeautifulSoup
import json
API_KEY = "API_KEY"
base_url = "https://www.alibaba.com/trade/search"
The base_url variable holds the base URL of the search results webpage you want to extract data from.
Step 3: Obtaining User Input and Formatting the Search Query
To make it interactive, we want to ask the user for some input, which will be the query searched in Alibaba.
def format_search_query(user_input):
formatted_query = "+".join(user_input.split())
return formatted_query
user_input = input("Enter the product you want to search for: ")
search_query = format_search_query(user_input)
- The user response is stored in the
user_inputvariable. - The
format_search_queryfunction formats the user’s input by replacing spaces with ‘+’ and encoding the query.
This will generate the URL we’ll use in our get() request.
Step 4: Find the Product Items on the Page
Understanding the page’s HTML layout is crucial for any web scraping. However, don’t worry if you’re not too skilled with HTML. We can use Developer Tools to identify our desired data.
When on the search results page, do “inspect element” on any web browser (Chrome, Safari, etc.) and open the developer tools window. Alternatively, press “CTRL+SHIFT+I” for Windows users or “Option + ⌘ + I” on Mac.
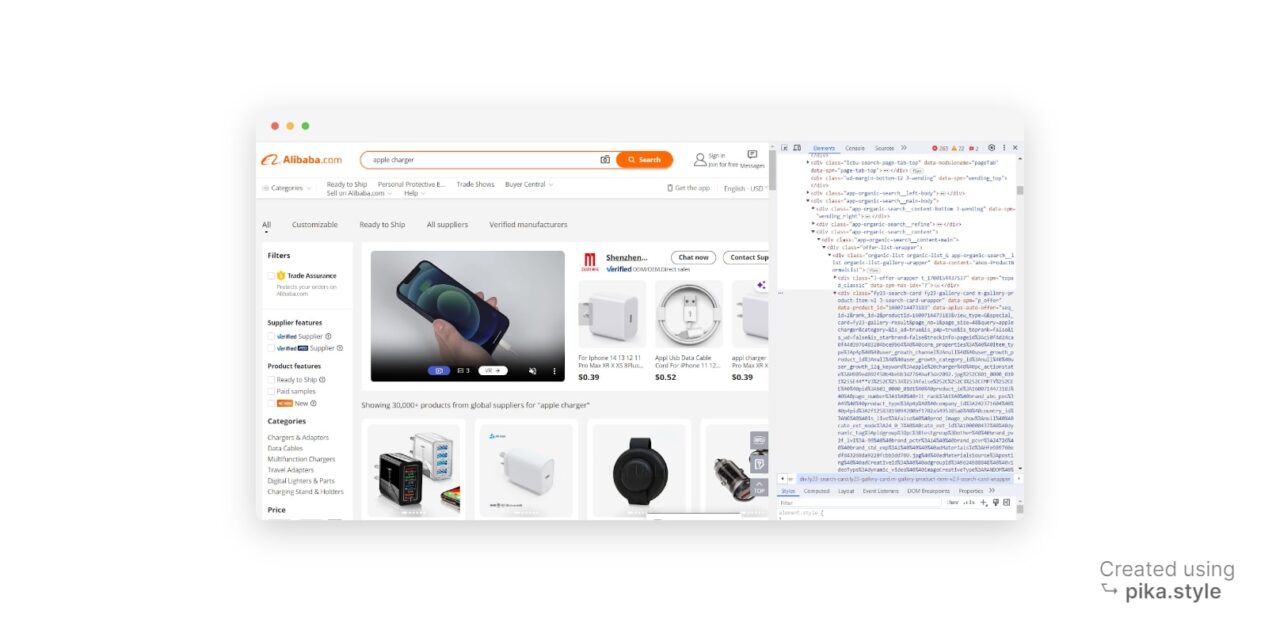
In the new window, you’ll see the source (src) code of the web page we’re targeting.
To grab an HTML element, we need an identifier associated with it. This could be the id of the element, any class name, or any other HTML attribute of the element. In our case, we’re using the class name as the identifier.
Upon closer inspection, we discover that each product container is a div element with the class search-card-info__wrapper.
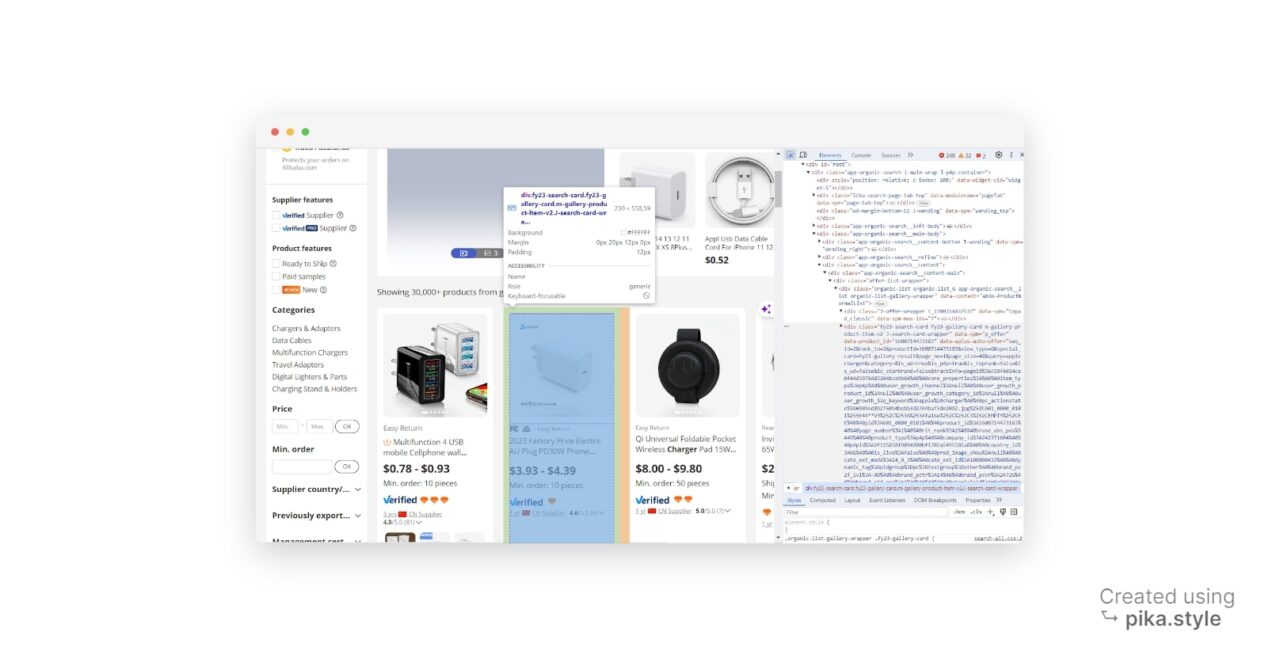
To find the product items on the page, we can use the find_all() method after parsing the HTML response from our get() request.
Step 5: Extract the Product Data
As we’re going to gather information from several URLs, we need to create an empty list where we can append all the data to:
product_data_list = []
For each page we’ll scrape, we need to construct the URL, send a get() request through ScraperAPI, parse the HTML response using BeautifulSoup4, find all product containers on the page, and iterate through each product container to extract the product data.
Here’s how this logic looks like in code:
for page in range(1, 6):
url = f"{base_url}?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&searchText={search_query}&page={page}"
print(f"Currently scraping page {page}... \n")
payload = {"api_key": API_KEY, "url": url}
r = requests.get("http://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
product_containers = soup.find_all("div", class_="search-card-info__wrapper")
for product_container in product_containers:
product_name_element = product_container.select_one(".search-card-e-title a span")
product_name = product_name_element.text.strip() if product_name_element else "nil"
price_element = product_container.select_one(".search-card-e-price-main")
price = price_element.text.strip() if price_element else "nil"
description_element = product_container.select_one(".search-card-e-sell-point")
description = description_element.text.strip() if description_element else "nil"
moq_element = product_container.select_one(".search-card-m-sale-features__item")
moq = moq_element.text.strip() if moq_element else "nil"
rating_element = product_container.select_one(".search-card-e-review strong")
rating = rating_element.text.strip() if rating_element else "nil"
product_data = {
"Product Name": product_name,
"Price": price,
"Description": description,
"MOQ": moq,
"Rating": rating,
}
product_data_list.append(product_data)
A couple of nuances to be aware of:
- We used the
select_one()function to select the first element that matches the specified CSS selector - The
forloop iterates through each product container - We used the
text.strip()method extracts the element’s text content and removes any leading or trailing whitespace - The
product_datadictionary holds the product data for each product
Thanks to this logic, we can get all the product data (formatted) in a single variable we can now dump into a JSON file
Step 6: Save the Scraped Data to a JSON file
Finally, we save the scraped data to a JSON file using the json.dump() function:
output_file = "alibaba_results.json"
with open(output_file, "w", encoding="utf-8") as json_file:
json.dump(product_data_list, json_file, indent=2)
print(f"Scraped data has been saved to {output_file}")
Just to get some feedback at the end, let’s print() a message to the console indicating that the scraped data has been saved to the JSON file.
If you’ve follow along, running your script will output a alibaba_results.json file with the product data:
{
"Product Name": "Wholesales 20w fast charging usb type c for apple mobile phone wall charger adapter us eu uk plug surge protector",
"Price": "US$2.54 - US$2.85",
"Description": "nil",
"MOQ": "Min. order: 10 pieces",
"Rating": "5.0"
},
{
"Product Name": "Free Sample EU PD 20W Usb-c Power Adapter Phone Charger Usb C Fast Wall Travel for Apple Iphone 13 12 Mobile Phone TYPE-C PD 3.0",
"Price": "US$1.60 - US$2.50",
"Description": "Easy Return",
"MOQ": "Min. order: 50 pieces",
"Rating": "5.0"
},
{
"Product Name": "EU US UK Portable Fast Mobile Charging USB Travel Fast Charger Adapter 120W QC5.0 Wall Charger For Apple iphone 11 Charger",
"Price": "US$1.20 - US$1.90",
"Description": "Easy Return",
"MOQ": "Shipping per pieces: US$3.74",
"Rating": "4.9"
},
{
"Product Name": "New Watch Headset 4 in 1 Magnetic Wireless Charger Folding Fast Charge for Apple 13/14 Por Max",
"Price": "US$10.84 - US$11.16",
"Description": "Ready to Ship",
"MOQ": "Shipping per pieces: US$7.96",
"Rating": "nil"
},
{
"Product Name": "Original Fast PD 20W US EU UK Charger Type c Wall Charger 3pin Plug For apple charger fast char iphone 12 13 14 Pro Max",
"Price": "$2.50 - $3.50",
"Description": "Easy Return",
"MOQ": "Shipping per boxes: $5.00",
"Rating": "4.6"
},
{
"Product Name": "3 in 1 Wireless Charger Magnetic Foldable Charging Holder Travel Portable Charger For iphone Watch Adapter Caricatore senza fili",
"Price": "$6.00 - $6.40",
"Description": "New",
"MOQ": "Min. order: 20 pieces",
"Rating": "4.8"
},
{
"Product Name": "Portable 15W Fast Charing Magnetic Wireless Charger for Apple 12 13 14 15",
"Price": "$1.92 - $2.00",
"Description": "nil",
"MOQ": "Min. order: 10 pieces",
"Rating": "4.9"
},
{
"Product Name": "Accessories 3ft 6ft 10ft USB Data Cables Fast Chargers For IPhone Cable Sync Usb Cable For Apple 5 6 7 8",
"Price": "$0.19 - $0.26",
"Description": "Easy Return",
"MOQ": "Min. order: 10.0 pieces",
"Rating": "4.8"
},
{
"Product Name": "dongguan 35w gan pd mi type c chargers for apple android usb wall quick mobile phone charger for phone 12 13 14",
"Price": "US$3.70 - US$4.00",
"Description": "Easy Return",
"MOQ": "Min. order: 1000 pieces",
"Rating": "3.6"
},
{
"Product Name": "factory hot sell good quality OD3.0MM phone charger cable usb wire for apple iphone cable charger",
"Price": "US$0.20 - US$0.50",
"Description": "Ready to Ship",
"MOQ": "Shipping per pieces: US$0.50",
"Rating": "4.8"
}, ... more JSON data ...
Congratulations, you just built your first scalable Alibaba scraper!
Wrapping Up
Let’s summarize what you’ve learned about Alibaba scraping today:
- You created a prompt to get the product you want to scrape data from
- Send your requests through ScraperAPI to bypass any anti-scraping mechanism
- Built a loop to collect data from several product pages within the pagination
- Exported the web data into a JSON file
Note: Data can be exported into a CSV/ Excel file. This automation makes it easy to transfer saved data to workflow tools like Zapier for further analysis for further analysis.
Need to send more than 3M API credits? Contact sales to get a custom plan with premium support, an account manager, and a team of experts working to get you consistent, accurate data.
Until next time, happy scraping!