


A proxy (or proxy server) is an intermediary server that forwards your requests to the destination website, effectively hiding your IP and giving you access to otherwise restricted content. In web scraping, they’re used to avoid anti-scraping techniques, making your bots more resilient.
How Do Proxies Work?
Every device connected to the internet has its own IP address, which acts like a physical street address. When your computer connects to a website, the browser uses your IP address to establish the connection to the web server where the website you want to see is hosted. Through this connection, your machine knows where to find the data you want, and the web server knows where to send the data to.
However, when you use a proxy for web scraping:
- You send your get request to the proxy server
- The proxy server forwards the request to the target website using its own IP address
- The website responds with the requested data, usually in HTML or JSON format, without ever getting your real IP
- The proxy server sends you the response it got from the target server
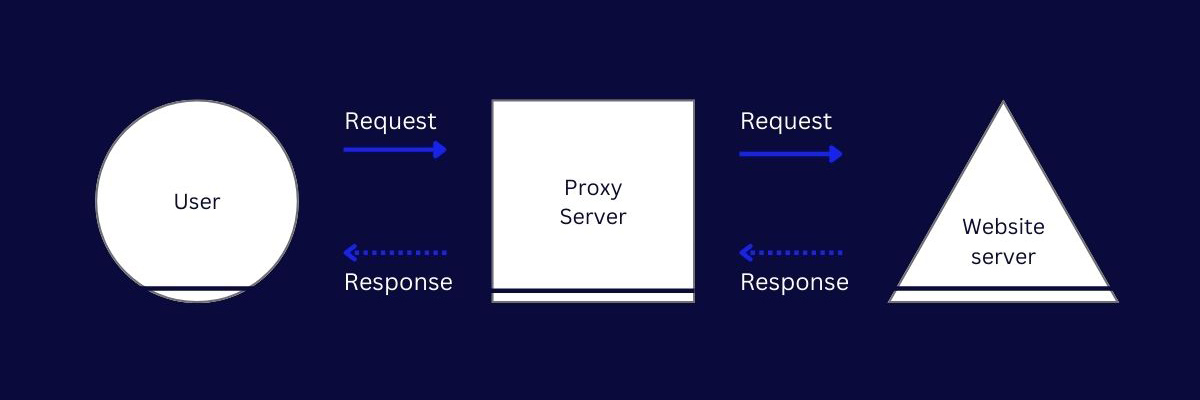
This way, your IP is secure, and your scrapers can access data without risks of IP based road-blocks.
When Do You Need to Use a Proxy?
There are three main reasons to use proxies in your web scraping project:
- Your IP is secure – because your scraper will send requests through your proxy server IP address, your IP won’t run the risk of getting temporarily or permanently banned for the target website.
- Get access to geo-specific data – many websites show different information based on geolocation (for example, eCommerce sites and search engines). Using a proxy with a German IP address will allow you to get data as a user from that country would.
- Scale (to a point) your data collection project – when your request rate grows, it’s easier for servers to identify your scraper and block its access. Setting and managing a proxy pool will help you circumvent this issue by rotating IP addresses between requests.
Proxies and Web Scraping
Proxies are an integral part of web scraping. They allow our scrapers and spiders to scrape the web without getting banned or blocked, which is indispensable to extracting data from millions of URLs.
However, it’s very hard, time-consuming, and expensive to set, manage and maintain a well-optimized proxy pool.
Public proxies are insecure and, most of the time, abused to the point that most websites will block any request coming from them. To have your own pool of proxies, you’ll need to manage browser farms and servers and curate your IP lists as they get blocked, keeping your pool as clean as possible. Then you will also need a healthy mix of residential, data center, and mobile proxies.
That’s where an off-the-shelf solution comes into play. These providers take care of the proxies and give you access on a subscription basis. This is a great way to take off the burden of maintaining the proxies and focusing on building your scrapers.
But remember we said earlier that proxies are an integral part of it? Emphasis on “part of it.” That’s because you’ll need more than just a high number of proxies to access all the data you’ll need.
ScraperAPI is an easy-to-use web scraping tool that gives you access to over 40M IPs in over 50 countries, renders dynamic content (JavaScript rendering), and handles CAPTCHAs, headers, IP rotation, retries and more for you, with just a simple API call.
const request = require('request-promise');
request('http://api.scraperapi.com/?api_key=APIKEY&url=http://httpbin.org/ip')
.then(response => {
console.log(response)
})
.catch(error => {
console.log(error)
})
Note: For sites like Amazon, Google Search, and Google Shopping, ScraperAPI provides JSON auto parsing to scrape data more accessible and faster.
Learn more about ScraperAPI with our documentation, or visit our blog to learn from real-life projects and access ready-to-use code snippets.
Learn more
- Build a Glassdoor scraper from scratch in Node.js
- Learn how to hide your IP effectively for web scraping
- Understand the difference between web scraping and web crawling
- More frequently asked questions about web scraping and data extraction
