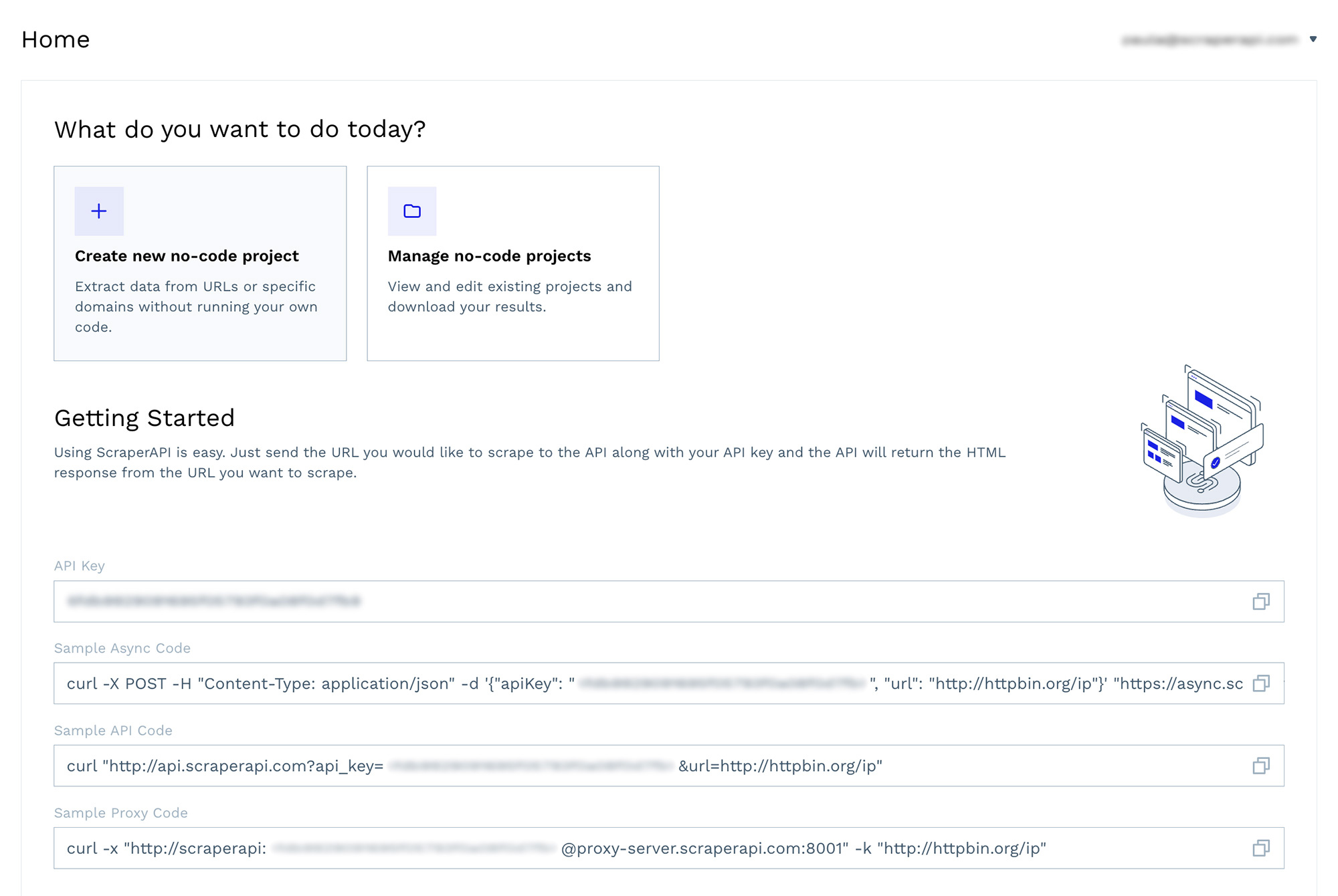
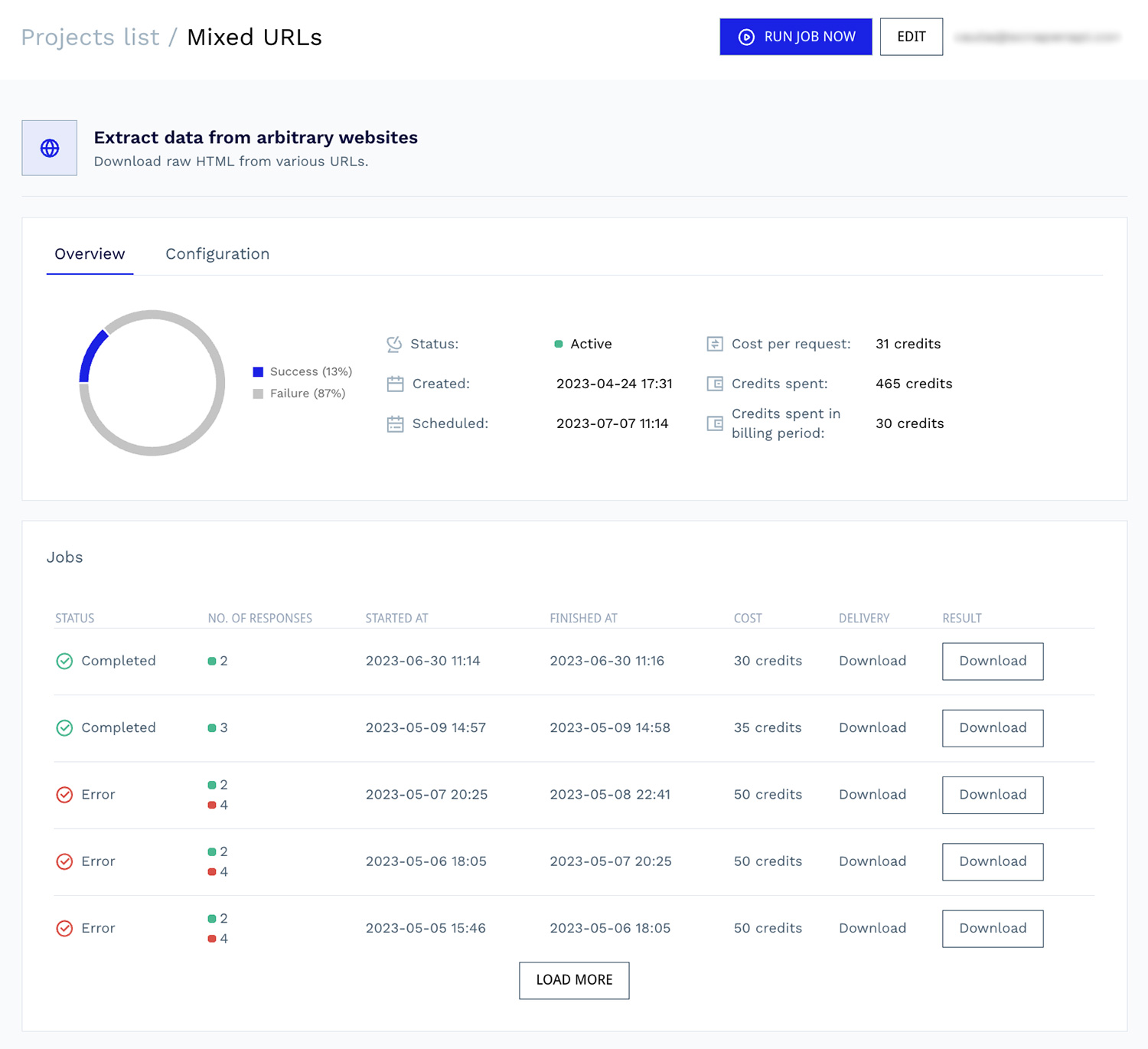
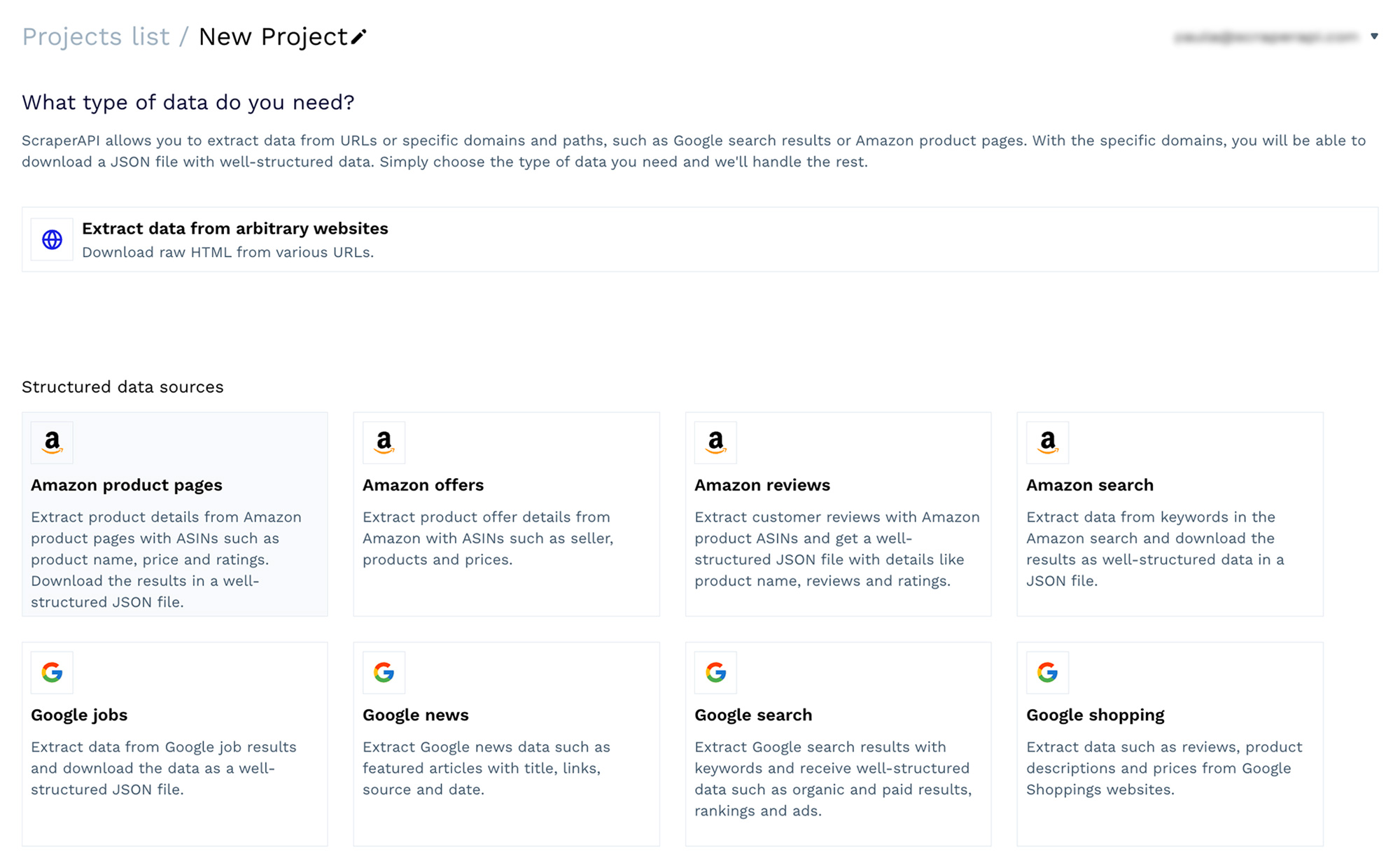
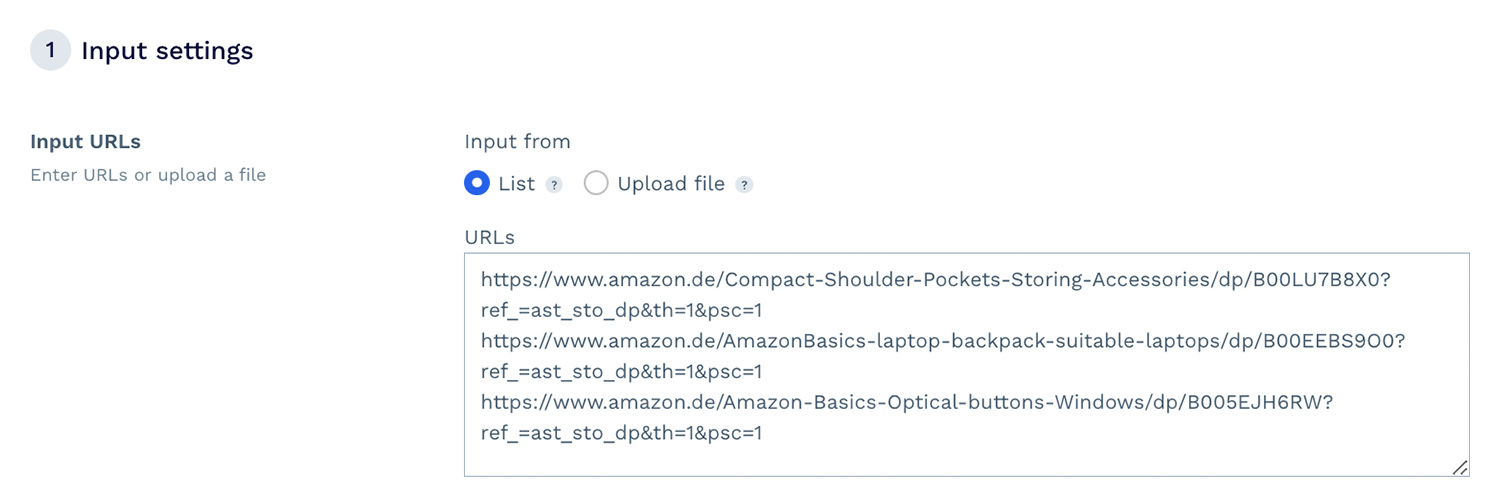
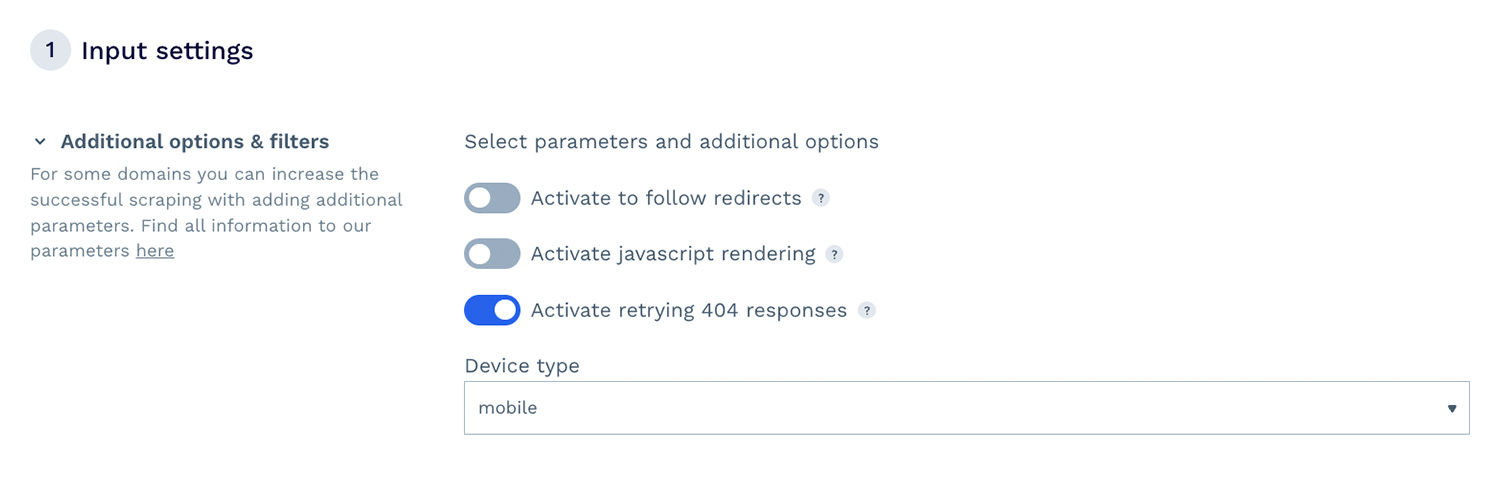
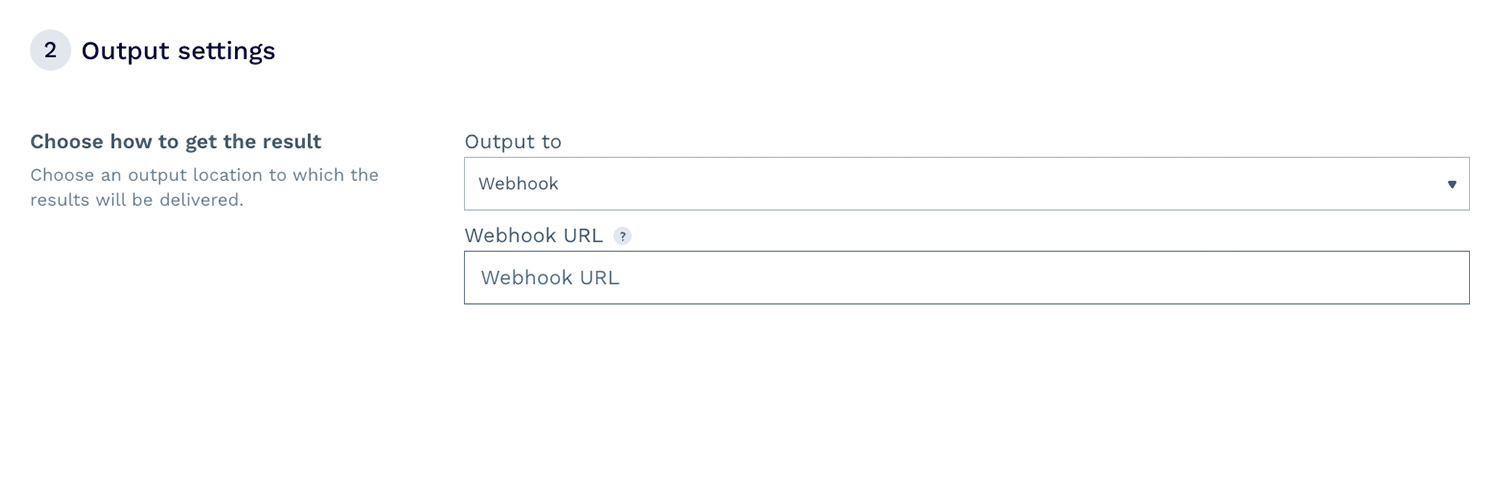
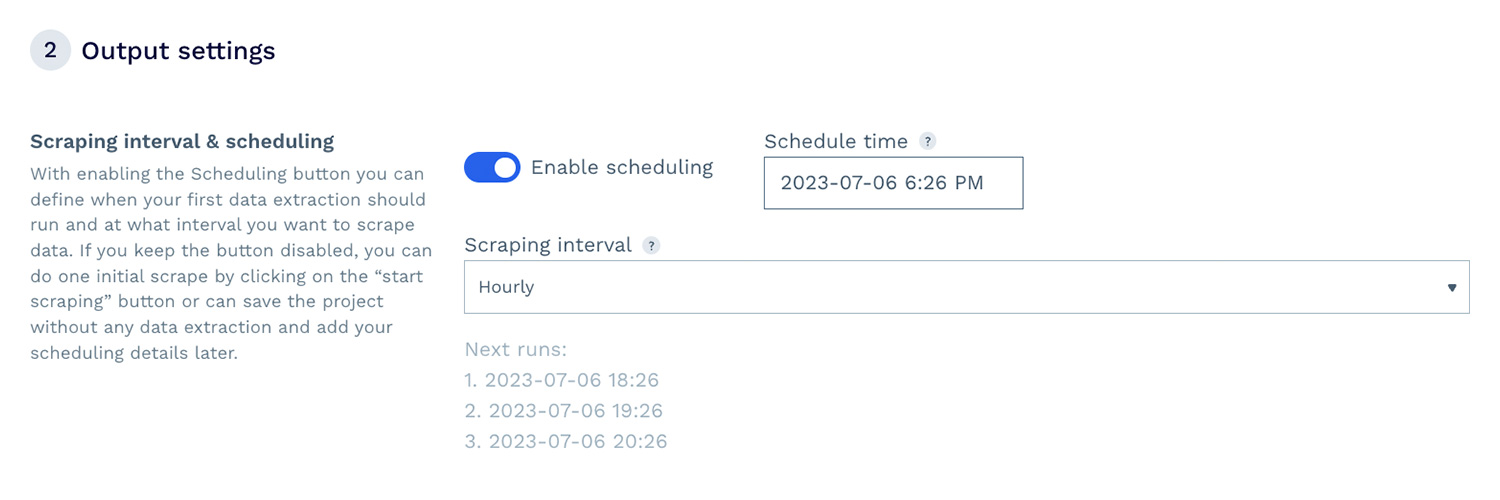
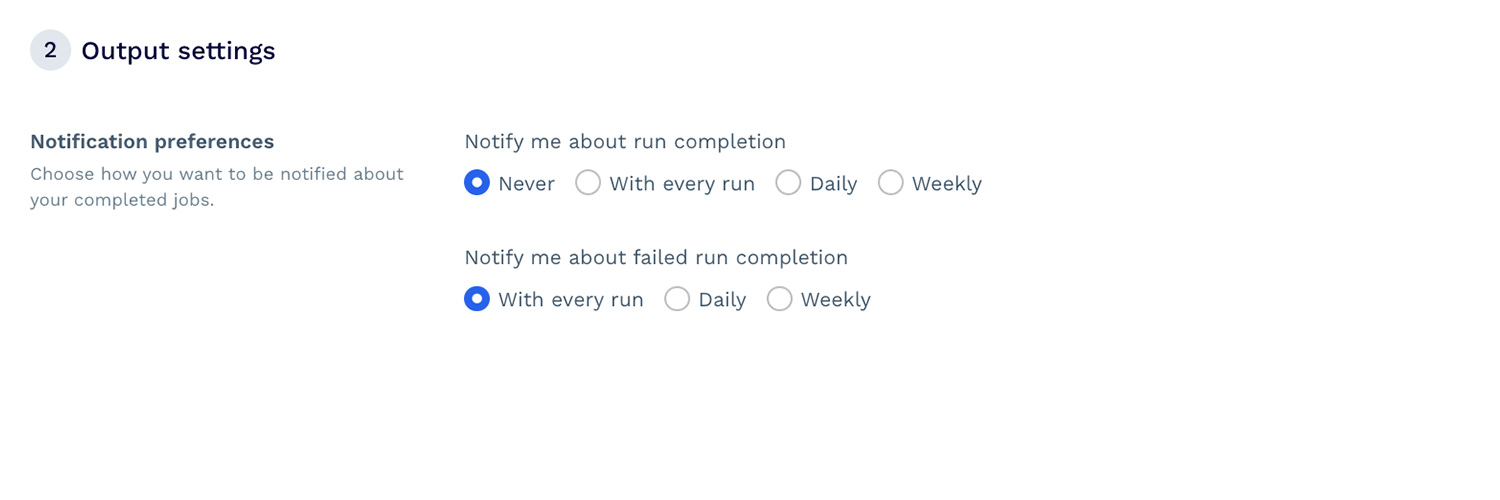
Setting up and launching a project with DataPipeline’s visual interface is simple. You don’t need to be a developer or data analyst to use it.
However, you will need to have some idea of how you’re going to process your data once you get it.
Not sure where to start? Read our guide on what is data parsing to learn the basics.