


Data Parsing in Web Scraping Explained
Data parsing is a critical step in web scraping, directly impacting the quality of extracted web data. By understanding the nuances of data parsing, you can select the most suitable web scraping tools and programming languages to achieve your web scraping goals.
In this guide, we’ll delve into the intricacies of data parsing for web data extraction. We’ll explore practical examples of data parsing in various parsing libraries and help you decide whether to build a custom parser or utilize a pre-built solution.
What is Data Parsing?
Data parsing is the process of transforming a sequence (unstructured data) into a tree or parse tree (structured data) that’s easier to read, understand and use. This process can be further divided into two steps or components: 1) lexical analysis and 2) syntactic analysis.
The lexical analysis takes a sequence of characters (unstructured data) and transforms it into a series of tokens. In other words, the Parser uses a lexer to “turn the meaningless string into a flat list of things like “number literal,” “string literal,” “identifier,” or “operator,” and can do things like recognizing reserved identifiers (“keywords”) and discarding whitespace.”
Finally, in the syntactic analysis, a parser takes these tokens and arranges them into a parse tree, establishing elements (nodes) and branches (the relationship between them).
To make the data parsing process easier to understand, let’s explore how data parsing works alongside web scraping to extract the information we need.
The Role of Data Parsing When Scraping Web Data
When writing a web scraper, no matter in which language, the first thing we need to do is gain access to a website’s information by sending a request to the server and downloading the raw HTML file. This HTML data is pretty much unreadable.
To use this data, we need to parse the HTML and transform it into a parse tree. We can then navigate to find the specific bits of information that are relevant to our business or goals.
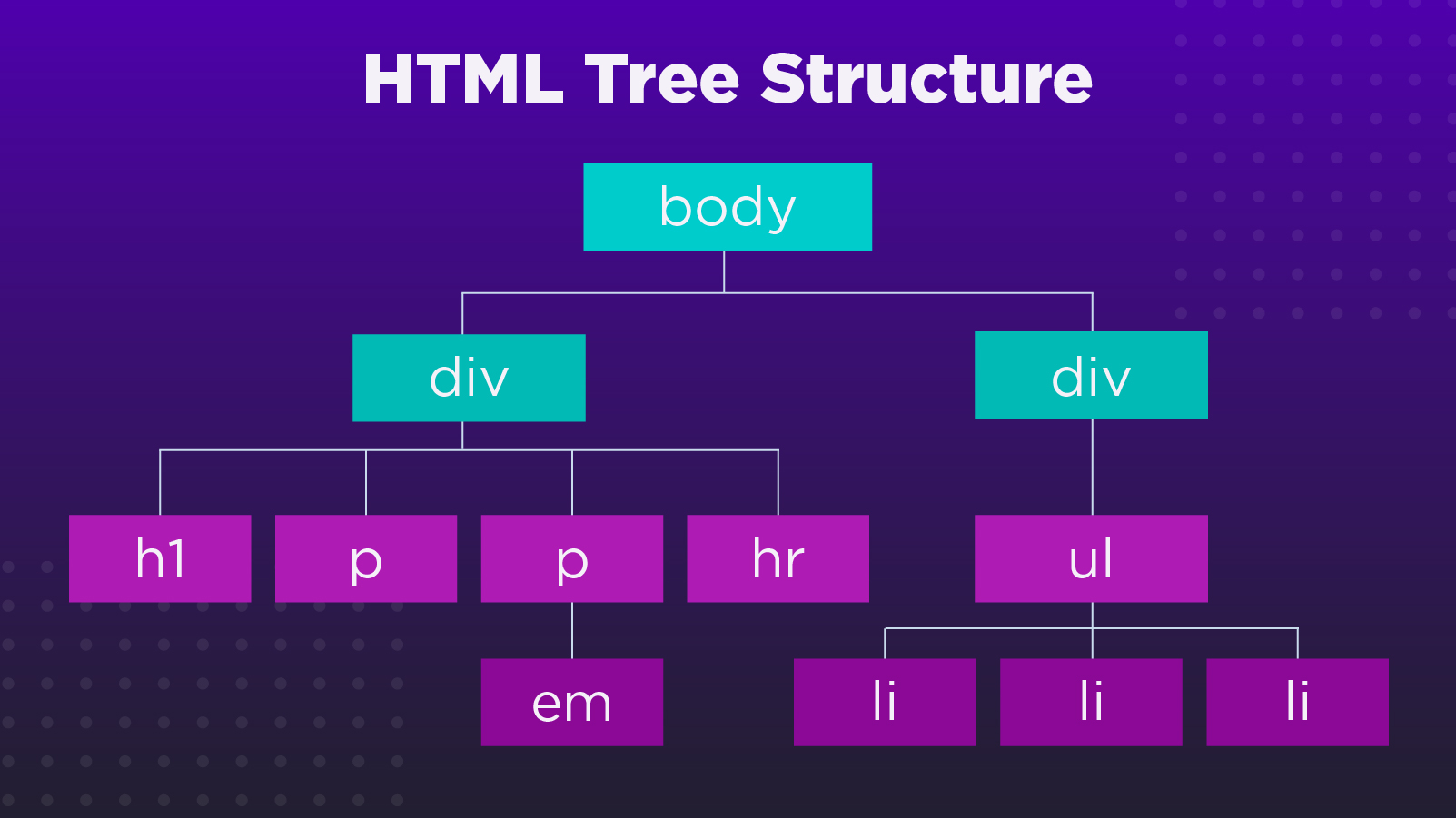
As you can see, every node represents a relevant HTML element and its content, and the branches are the relationships between them.
In other words, the parser will clean the data and arrange it in a structured format that only contains what we need and can now be exported in JSON, CSV, or any other format we define.
The best part is that a lot of the heavy lifting is already done for us. There are several parsers and tools at our disposal. In most cases, they’ll bring valuable features like navigating the parsed document using CSS or XPath selectors according to their position in the tree.
Best Parsing Libraries for Web Scraping
Most of the data we work with within web scraping will come in HTML. For that reason, there are many open-source HTML parsing libraries available for almost every language you can imagine, making web scraping faster and easier.
Here are some of the most popular parsing libraries you can use in your projects:
ScraperAPI
ScraperAPI, as you might have guessed, is a web scraping API developed to help you avoid IP blocks by handling a lot of the complexities of web scraping for you. Things like IP rotation, JavaScript rendering, and CAPTCHA handling are automated for you just by sending your requests through ScraperAPI’s servers.
However, something that is less known is that ScraperAPI also has an autoparse functionality. When setting autoparse=true in the request’s parameters, the API will parse the raw HTML and return the data in JSON format.
To make it more visual, here’s a snippet you can use right away:
</p>
<pre>curl "http://api.scraperapi.com/?api_key=APIKEY&url=https://www.amazon.com/dp/B07V1PHM66&autoparse=true"</pre>
<p>Currently, this functionality works with Amazon, Google Search, and Google Shopping.
To get 5000 free API credits and your own API key, signup for a free ScraperAPI account.
Cheerio and Puppeteer
For those proficient in JavaScript, Cheerio is a blazing fast Node-js library that can be used to parse almost any HTML and XML file and “provides an API for traversing/manipulating the resulting data structure.”
Here’s a sample snippet from our Node.js web scraper tutorial:
</p>
<pre>const axios = require('axios');
const cheerio = require('cheerio')
const url = 'https://www.turmerry.com/collections/organic-cotton-sheet-sets/products/percale-natural-color-organic-sheet-sets';
axios(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html)
const salePrice = $('.sale-price').text()
console.log(salePrice);
})
.catch(console.error);</pre>
<p>However, if you need to take screenshots or execute JavaScript, you might want to use Puppeteer, a browser automation tool, as Cheerio won’t apply any CSS, load external resources or execute JS.
Beautiful Soup
Python might be one of the most used languages in data science to date, and so many great libraries and frameworks are available for it. For web scraping, Beautiful Soup is an excellent parser for web scraping that can take pretty much any HTHML file and turn it into a parse tree.
The best part is that it handles encoding for you, so it “converts incoming documents to Unicode and outgoing documents to UTF-8.” Making exporting data into new formats even simpler.
Here’s an example of how to initiate Beautiful Soup:
</p>
<pre>import csv
import requests
from bs4 import BeautifulSoup
url = 'https://www.indeed.com/jobs?q=web+developer&l=New+York'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
results = soup.find(id='resultsCol')</pre>
<p>Snippet from our guide on building Indeed web scraper using Beautiful Soup
For more complex projects, Scrapy, an open-source framework written in Python designed explicitly for web scraping, will make it easier to implement a crawler or navigate pagination.
With Scrapy, you’ll be able to write complex spiders that crawl and extract structured data from almost any website.
The best part of this framework is that it comes with a Shell (called Scrapy Shell) to safely test XPath and CSS expressions without running your spiders every time.
Here’s an example of handling pagination with Scrapy for you to review.
Rvest
Inspired by libraries like Beautiful Soup, Rvest is a package designed to simplify web scraping tasks for R. It uses Magrittr to write easy-to-read expressions (>), speeding up development and debugging time.
To add even more functionally to your script, you can implement Dplyr to use a consistent set of verbs for data manipulation like select(), filter(), and summarise().
Here’s a quick sample code from our Rvest data scraping tutorial:
</p>
<pre>link = "https://www.imdb.com/search/title/?title_type=feature&num_votes=25000&genres=adventure"
page = read_html(link)
titles = page > html_nodes(".lister-item-header a") > html_text()</pre>
<p>In just three lines of code, we’ve already scraped all titles from an IMDB page, so you can imagine all the potential this package has for your web scraping needs.
Nokogiri
With over 300 million downloads, Nokogiri is one of the most used gems in Ruby web scraping; especially when parsing HTML and XML files. Thanks to Ruby’s popularity and active community, Nokogiri has a lot of support and tutorials, making it really accessible to newcomers.
Like other libraries in this list, when web scraping using Ruby, you can use CSS and XPath selectors to navigate the parse tree and access the data you need. That said, scraping multiple pages is quite simple with this gem as long as you understand how HTML is served.
Check our Nokogiri for beginners guide for a quick introduction to the gem. In the meantime, here’s a snippet to parse an eCommerce product listing page:
</p>
<pre>require 'httparty'
require 'nokogiri'
require 'byebug'
def scraper
url = "https://www.newchic.com/hoodies-c-12200/?newhead=0&mg_id=2&from=nav&country=223&NA=0"
unparsed_html = HTTParty.get(url)
page = Nokogiri::HTML(unparsed_html)
products = Array.new
product_listings = page.css('div.mb-lg-32')</pre>
<p>HTMLAgilityPack
For C# developers, HTMLAgilityPack is the go-to HTML and XML parser. It is fast and has all the functionality you’ll need for your projects. However, you might want to use it through ScrapySharp.
ScrapySharp is an open-source library written in c-sharp for web scraping. It includes a web client for mimicking a browser and an HTMLAgilityPack extension to use CSS selectors for traversing the node tree.
After setting up your file, you can parse your target URL with these two lines of code:
</p>
<pre>HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("https://blog.hubspot.com/topic-learning-path/customer-retention");</pre>
<p>For the complete code, check our tutorial on CSharp web scraping.
The Pros and Cons of Building Your Own Data Parser
We’ve seen many scraping projects developed with the tools listed above and have used them firsthand, so we can guarantee you can accomplish pretty much anything with the available libraries.
However, we also know that sometimes (and for specific industries), it’s essential to consider a more in-house option. If you are considering building your own data parser, keep in mind the following pros and cons to make an informed decision:
Advantages |
Disadvantages |
|
|
|
|
|
|
|
|
In most cases, you’ll be fine just using the existing data parsing technologies, but if it makes business sense to build your own data parser, then it might be a good idea to start here. That data parser guide is perfect for beginner web scraping enthusiasts.
Seamless Data Parsing Leads to Higher Quality Scraped Data
Parsing the data is crucial for web scraping as we can’t work on raw data – at least not effectively and efficiently.
That said, it’s even more critical to have an objective in mind and understand the website we’re trying to scrape. Every website is built differently, so we must research before writing any code or picking our tools.
JavaScript-heavy sites will require a different approach than static pages, and not every tool can handle pagination easily.
Remember, web scraping is about figuring out the structure of a website to extract the data we’ll need. It’s about problem-solving and not just tech stack.
To learn more about web scraping, check our blog for web scraping tutorials and cheat sheets, and take a look at our documentation to learn how ScraperAPI can help you build undetectable scrapers in minutes.
Until next time, happy scraping!





