



What’s the Use of a Proxy Server?
A proxy server acts as a location indicator and a gateway between your device and the Internet, they look like this: 161.77.55.119.
When you use a proxy server, internet traffic flows through the proxy server to the address you requested.
Proxy servers also mask your IP address, allowing you to browse the web anonymously or appear to be browsing from a different location. This can be very useful when accessing restricted content based on geographic location.
This brings us to how proxy pools can be useful. Since your proxy is tied to your IP and your IP is tied to where you live, proxy pools help you switch your location among different proxies so your true location won’t be detected.
But how can a proxy be “located” in another country? It all comes down to the server’s physical location and IP address. So a “US” proxy server is simply a server physically located in the United States and assigned a US-based IP address.
Note: To understand more about proxy servers and how they work, check out our detailed guide: What is a Proxy?
Why is Proxy Location Important?
Proxy location refers to the geographical location of the proxy server you are using. This aspect is crucial for web scraping for several reasons:
- Bypass geo-restrictions: Only those who live in some locations can access some websites there. By extension, those who live outside are left out. Once you have the proxies of these countries, you can access their local data easily.
- Security: You should use proxies if you want to use the internet without revealing your true location. This is helps to maintain anonymity and keeps your location details generally undetectable.
- Getting localized data: Some websites show different information based on your IP location. By rotating proxies, you can get data from a specific country as local users would. A good example of this is collecting search data from the UK vs. the US.
A practical example of the importance of proxy location is with Home Depot. If you try to access Home Depot’s US site from an IP address outside the US, you will find it’s content to be blocked. This can be frustrating for business owners and data analysts looking to compare prices in the US market.
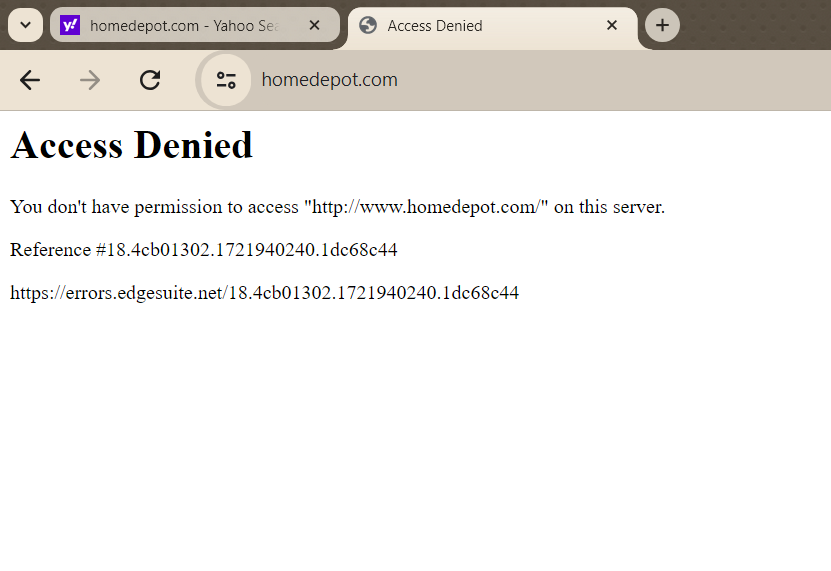
However, using a US-based proxy can easily solve this issue and allow you to gather data as if you were browsing from within the United States.
Note: To learn more about why your scraper might be getting blocked and how proxies can help, take a look at this article: Why Is My Scraper Getting Blocked?
Changing Your IP Location with Proxies for Web Scraping
Now that you understand how IP location can limit your web scraping attempts, it is important to know how you can simply change your location with proxies and bypass the blockade.
Before you can change your IP location to a specific country, you first need access to a pool of proxies located there. By sending your request through this proxy pool, your targeted website will detect the proxy IP location, giving you access to the data you need.
To make things easier (from both the development and business side), let’s use ScraperAPI to rotate our proxies and use its geotargetig feature to overcome three common challenges related to geo-sensitive data:
1. Scrape Geo-restricted Content
Let’s say you want to scrape HomeDepot’s website for product data.
import requests
from bs4 import BeautifulSoup
url = "https://www.homedepot.com/b/Furniture-Living-Room-Furniture-Sofas-Couches/N-5yc1vZc7oy?NCNI-5&searchRedirect=couch&semanticToken=k27r10r00f22000000000e_202407231926267546513699920_us-east4-wskn%20k27r10r00f22000000000e%20%3E%20st%3A%7Bcouch%7D%3Ast%20ml%3A%7B24%7D%3Aml%20nr%3A%7Bcouch%7D%3Anr%20nf%3A%7Bn%2Fa%7D%3Anf%20qu%3A%7Bcouch%7D%3Aqu%20ie%3A%7B0%7D%3Aie%20qr%3A%7Bcouch%7D%3Aqr"
response = requests.get(url)
# You will encounter an error or get blocked.
print(response.status_code)
However, without using US proxies, our request might fail or be blocked, resulting in an error code, such as 403 Forbidden – which is what happens with the code above. This happens because the website detects that the request is coming from an IP address that is not allowed to access the content.
To overcome this restriction, let’s use ScraperAPI to send our request through its US proxy pool.
To get started, create a free ScraperAPI account and copy your API key – you’ll need this key to send your request later. Then, ensure you have the necessary dependencies installed. You can install them using the following command:
pip install requests beautifulsoup4 lxml
Once everything is set up, we can use ScraperAPI’s country_code parameter to tell it to send all our requests using only US-based proxies, like so:
import requests
API_KEY = "Your_Api_key"
url = "https://www.homedepot.com/b/Furniture-Living-Room-Furniture-Sofas-Couches/N-5yc1vZc7oy?NCNI-5&searchRedirect=couch&semanticToken=k27r10r00f22000000000e_202407231926267546513699920_us-east4-wskn%20k27r10r00f22000000000e%20%3E%20st%3A%7Bcouch%7D%3Ast%20ml%3A%7B24%7D%3Aml%20nr%3A%7Bcouch%7D%3Anr%20nf%3A%7Bn%2Fa%7D%3Anf%20qu%3A%7Bcouch%7D%3Aqu%20ie%3A%7B0%7D%3Aie%20qr%3A%7Bcouch%7D%3Aqr"
payload = {"api_key": API_KEY, "url": url, "render": True, "country_code":"us" }
response = requests.get("http://api.scraperapi.com", params=payload)
print(response.status_code)
Note: Remember to replace Your_Api_key with your actual ScraperAPI API key.
By simply adding the country_code parameter to your ScraperAPI request, you can access HomeDepot as if you were browsing from within the United States. This is the new response code of this scraping script:
200
2. Scrape Localized Data
Another scenario to change your IP location with proxies is when the response you get changes depending on your location. A prime example of this are search engine results pages (SERPs).
To make it easy to see what I mean, we’ll use ScraperAPI’s Google Search endpoint to retrieve and compare search data from Google search results in the US and the UK. This endpoint transforms the data into usable JSON, making it easier to analyze regional trends and preferences.
US Search Results
Let’s start by retrieving search results for the keyword “Sofa” from the US:
import requests
import json
APIKEY= "Your_Api_key"
QUERY = "Sofa"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'us'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
# Parse the response text to a JSON object
data = r.json()
# Write the JSON object to a file
with open('Us_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in Us_google_results.json")
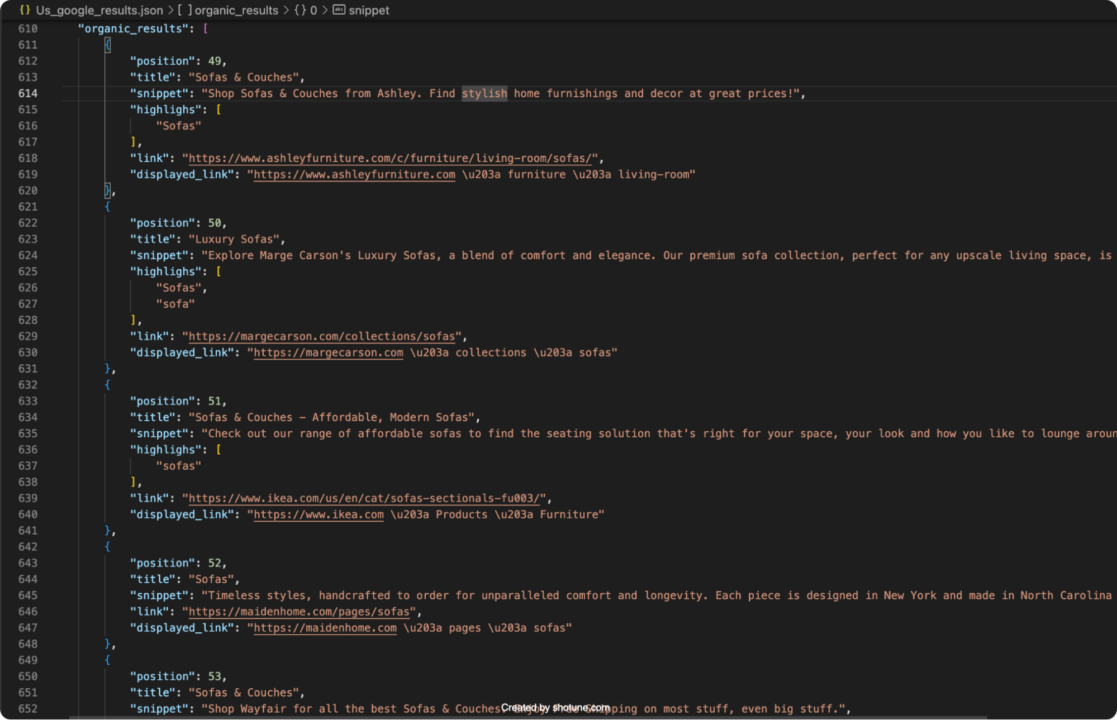
This code sends a request to ScraperAPI’s Google SERP endpoint, specifying the US as the target country. The response is then parsed and saved into a JSON file named Us_google_results.json. The results stored in this file will reflect the localized data from the US.
UK Search Results
Next, we’ll do the same for the UK:
import requests
import json
APIKEY= "Your_Api_key"
QUERY = "Sofa"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'uk'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
# Parse the response text to a JSON object
data = r.json()
# Write the JSON object to a file
with open('Uk_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in Uk_google_results.json")
Note: Replace <Your_Api_key> with your ScraperAPI’s API key before running the code. If you don’t have one, create a free ScraperAPI account to claim 5,000 API credits to test the tool.
This code retrieves Google search results for the keyword “Sofa,” but this time for the UK. The data is stored in Uk_google_results.json, showcasing the differences in search results between the two regions.
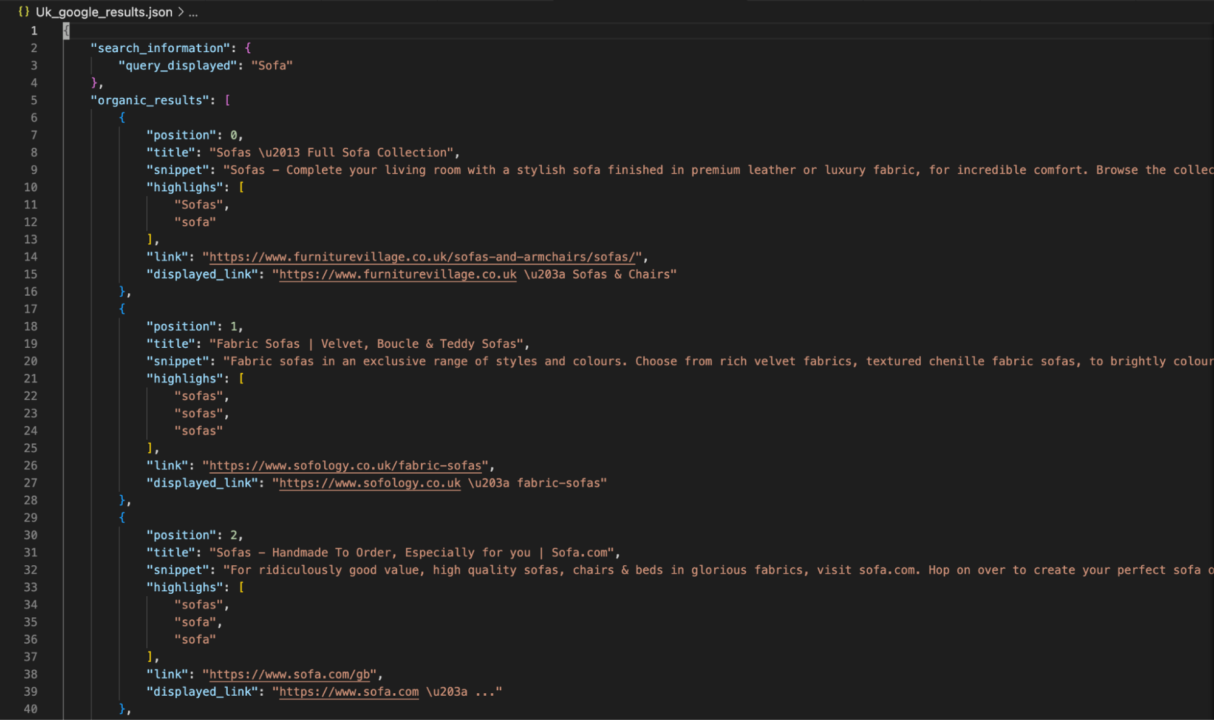
By modifying the country_code parameter, you can easily retrieve and compare search results tailored to each location, revealing regional trends and preferences.
This approach is invaluable for businesses looking to understand market differences, optimize their SEO strategies, or conduct competitor analysis across various regions. For more details on using ScraperAPI’s SDEs, visit the documentation.
Compare Data Across Several Regions
In many cases, you may need to scrape the same type of data from different regions to run comprehensive comparisons. For instance, if you’re analyzing pricing strategies for a competitor operating in multiple European countries.
Using geo targeting can help you gather all the data as local users would see it, allowing you to build a comprehensive dataset reflecting regional pricing variations and other localized information.
Here’s an example using ScraperAPI to collect data from Amazon’s country-specific domains:
import requests
API_KEY = "YOUR_SCRAPERAPI_KEY"
target_countries = ["fr", "de", "es", "it"] # France, Germany, Spain, Italy
base_url = "https://www.amazon"
for country_code in target_countries:
url = f"{base_url}.{country_code}/s?k=wireless+keyboard" # Modify URL structure as needed
payload = {"api_key": API_KEY, "url": url, "render": True, "country_code": country_code}
response = requests.get("http://api.scraperapi.com", params=payload)
# Extract and store product information for each country
if response.status_code == 200:
data = response.text
# Parse and extract relevant data here
print(f"Data from {country_code} has been successfully retrieved.")
else:
print(f"Failed to retrieve data from {country_code}. Status code: {response.status_code}")
This script uses ScraperAPI to send requests to Amazon’s French, German, Spanish, and Italian domains, simulating local access. The country_code parameter ensures that the data reflects what a local customer would see, including region-specific prices and product availability.
Collecting and analyzing data from different regions allows you to identify patterns and variations in pricing strategies, marketing tactics, and product offerings. This information can be invaluable for market analysis, competitive intelligence, and strategic planning.
For detailed data extraction and parsing, you may need to tailor your code further to handle specific HTML structures or data formats used by each region’s Amazon site.
Want to save time parsing and cleaning raw HTML data? Use our Amazon scraper to turn raw HTML into ready-to-use product data in JSON or CSV format.
Which Web Scraping Proxy Is The Best for You?
As always, selecting the best proxy provider for web scraping depends on your exact needs and objectives.
Before you choose, consider the following aspects:
- What’s your budget? Proxy services come in a wide range of pricing plans, from free tiers to enterprise-level subscriptions.
- How big are your data needs? How many concurrent requests do you need to run? Larger projects require more robust solutions that can handle high request volumes.
- Do you need a built-in analytics panel? Some providers offer dashboards to monitor your usage, success rates, and other helpful metrics.
- Do you just need proxies or will a scraping tool come in handy for your tasks? Read our guide on when to choose a scraping API over proxies to choose the right one.
- Will the tool you’re considering automate your work to a satisfactory level? How much time will you need to spend on maintenance and manual tasks? Look for features that simplify proxy management and reduce your workload.
- Does the provider have an API? APIs let you easily integrate the tool into your stack, which is essential for web scraping at scale.
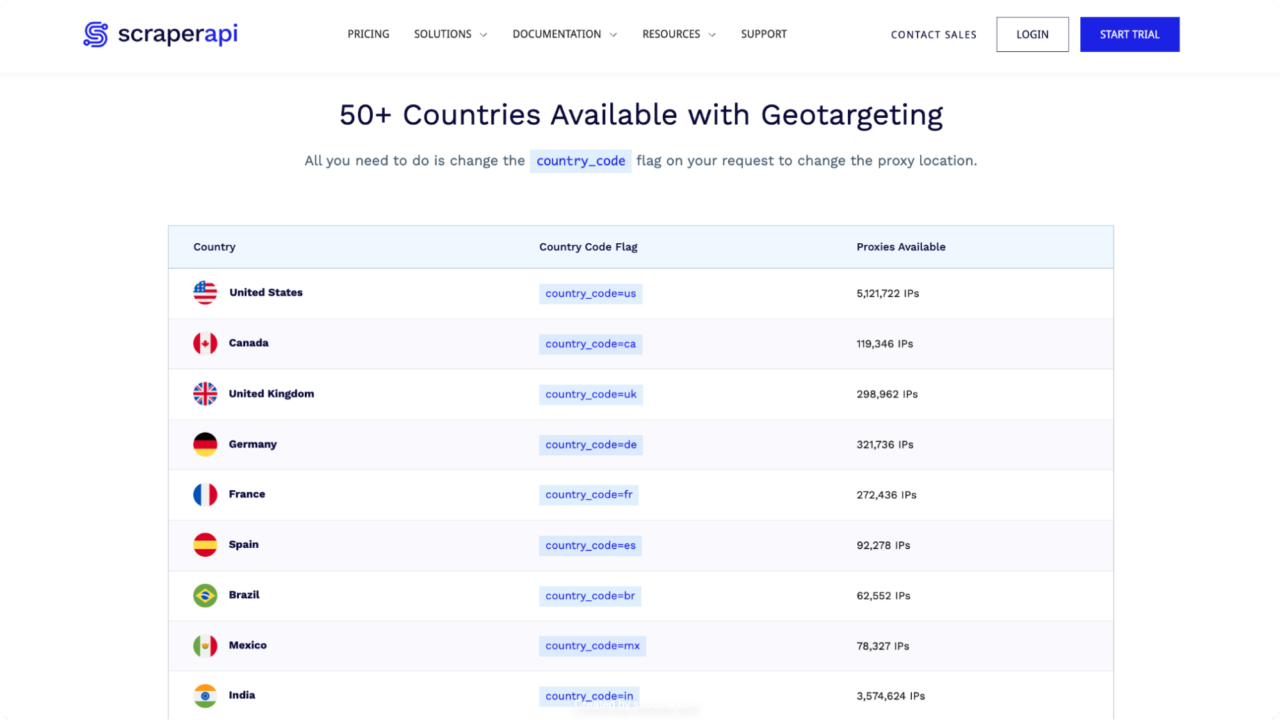
If you’re looking for a powerful and reliable web scraping solution that ticks all the boxes, as well as having a pool of proxies across over +50 countries, consider ScraperAPI.
Here’s why:
- Extensive IP pool: Access over 40M IPs across 50+ countries.
- High uptime: Maintains 99.99% uptime, optimizing request speeds and removing blacklisted IPs.
- Automation: Automates IP and HTTP header rotations using machine learning for efficiency.
- Advanced anti-bot bypassing: Handles CAPTCHAs, rate limiting, fingerprinting, and other defenses.
- Structured data endpoints: Offers endpoints to turn raw HTML into JSON or CSV data from big domains like Amazon, Walmart and Google.
Using these endpoints can significantly speed up your data collection, as ScraperAPI handles the entire process and provides all relevant data for you to target your customers based on their locations.
Wrapping Up: Web Scraping and Proxy Location
Proxies are an integral part of scraping the web. They let you hide your IP address, bypass rate limiting, and access geo-restricted content. By understanding how to leverage proxies effectively, you can:
- Overcome geographical restrictions
- Gather data from specific regions
- Reduce the risk of getting blocked
Ready to experience hassle-free web scraping? Sign up for a free ScraperAPI account today and get 5,000 free scraping credits to get started!
For more advanced techniques, check out these resources:




