



What is a Scraping API?
Scraping APIs are web-scraping service providers that help web scrapers avoid getting banned by circumventing various anti-scraping techniques put in place by websites. They use IP rotation, CAPTCHA solving, and other in-house techniques to ensure that the page you requested is downloaded for you.
Using a web scraping API is as simple as sending an API request, especially with ScraperAPI. They can handle large volumes of data quickly and efficiently, ensuring you receive the information you need without manual intervention.
Their flexibility also means they support various programming languages and can be easily integrated into existing workflows, making it easy to extract data from websites without disrupting your existing processes.
7 Use cases for Web Scraping in SEO
Obtaining up-to-date search engine data is imperative for SEO initiatives. It forms the basis for understanding rankings and improving brand visibility on search engines pragmatically and effectively.
Let’s explore some of the top use cases of SEO scraping:
1. Automating Keyword Research and Monitoring
Keyword research is the backbone of any SEO strategy, hence close attention must be paid to keyword selection and performance. With SEO scraping, businesses can automate the process of collecting keyword rankings and monitoring them over time. This saves time and provides real-time insights into keyword performance across different clients.
Beyond basic keyword tracking, web scraping can facilitate more advanced techniques like TF-IDF (Term Frequency-Inverse Document Frequency) analysis, which measures how frequently a word appears in a document relative to its rarity across a large dataset, helping identify important terms in a collection of content.
By integrating TF-IDF models with scraped data, companies can refine their keyword strategies beyond what standard tools offer, leading to more effective optimization.
If you don’t know where to start, here are some of our guides on keyword research using web scraping:
2. Collecting Competitors’ Ad Data
SEO web scraping enables gathering valuable data on competitors’ advertising strategies. This information can help you understand their SEO strategy and identify potential keywords to target, helping companies refine their strategies and identify new opportunities.
This can help you identify whether your competitors are buying ads for the keywords you are interested in or organically ranking higher – which means they receive more traffic over time or provide [more] quality content.
By collecting competitors’ ad data, businesses can:
- Estimate competitors’ PPC investment based on ad frequency in SERPs: This helps forecast budgets, plan competitive strategies, and justify proposed ad spending to clients or stakeholders.
- Identify and analyze competitors’ landing pages by following their ad links: By scraping ad information and following each ad link, you can analyze the landing page’s headings, content, meta descriptions, titles, images, and videos. This provides a comprehensive view of their PPC campaigns, helping you find gaps in their marketing, generate content ideas, and develop effective funnels for your campaigns.
- Find out who your main competitors are for specific keywords: Your known competitors aren’t the only ones investing in PPC. Scraping ad data at scale allows you to quickly identify other companies competing for the same keywords. This is especially useful when entering new geographical markets.
SEO data empowers startups to make informed decisions about keyword targeting, ad budgeting, and overall PPC strategy, ultimately leading to more effective campaigns for their clients.
To help you get started, check our guide on scraping competitors’ ad and content data from Google Search.
3. Monitor SERP Snippets
SERP features are unique elements on Google’s search engine results page that go beyond traditional organic listings. These features can significantly impact a website’s visibility and click-through rates. Hence, you can optimize your content for better visibility and engagement by monitoring SERP snippets.
Key SERP features to monitor include:
- Featured Snippets: Concise answers displayed at the top of organic results (position 0). These are pulled from relevant web pages and can drive significant traffic.
- People Also Ask: Related questions and answers are displayed below the main search result.
- Knowledge Panels: Informative boxes about entities like people, places, and things.
- Video Carousels: Rotating collections of video results relevant to the search query.
- Local Pack: Map and listings for local businesses relevant to the search query.
- Image Packs: Grids of thumbnails showcasing visually relevant images.
- Rich Snippets: Enhanced information like reviews, ratings, and recipe ingredients directly in search results.
Scraping APIs can help you extract this data and monitor competitors’ success in capturing them. By tracking these snippets, businesses can identify opportunities to optimize their clients’ content for enhanced visibility and click-through rates.
Pro Tip:
ScraperAPI’s Google Search endpoint returns all of these elements in JSON or CSV format, allowing you to monitor SERP snippets (or rich results) by submitting a list of keywords through the API. Learn more by visiting the Google Search structured endpoint documentation.
4. Aggregate Localized SERP Data
Web scrapers with geotargeting capabilities enable the collection and analysis of localized SERP data. By adjusting country codes or geolocation parameters, businesses can observe how rankings and search results differ across regions; this also enables them to:
- Collect SERP data from multiple countries and regions
- Compare search results across different locations
- Identify local ranking factors and trends
- Optimize content for specific geographic targets
ScraperAPI offers pre-configured endpoints designed for specific popular websites, including Google Search. These Google scrapers are built from the ground up for SEO and development teams that want to aggregate SERP data from all major Google domains. They provide uninterrupted data streams perfect for near real-time keyword monitoring.
With ScraperAPI’s Structured Data Endpoints, you can:
- Gather structured data in a JSON format
- Customize your datasets with rich parameters
- Work with clean data for faster workflow
Let’s quickly demo using ScraperAPI’s Google SDE to collect localized SERP data. We’ll compare search results for the query “Sofa” in the United States and the United Kingdom.
If you’re already familiar with ScraperAPI, copy and run this code. Otherwise, create a free ScraperAPI account to access your API key and use the code snippet below.
First, let’s fetch the results for the US:
<pre class="wp-block-syntaxhighlighter-code">import requests
import json
APIKEY = "YOUR_API_KEY"
QUERY = "Sofa"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'us'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
data = r.json()
with open('us_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in us_google_results.json")</pre
>
Output:
{
"position": 9,
"title": "Lifestyle Solutions Watford Sofa",
"thumbnail": "data:image/webp;base64,UklGRrIsAABXRUJQVlA4IKYsAACQow...",
"price": "$305.11",
"seller": "Home Depot",
"stars": 3.1,
"rating_num": 401
},
{
"position": 10,
"title": "Article Timber Olio Sofa",
"thumbnail": "data:image/webp;base64,UklGRtY1AABXRUJQVlA4IMo1AABwpI...",
"price": "$1,299.00",
"seller": "Article",
"stars": 4.3,
"rating_num": 280
},...
Now, simply change the country_code parameter from 'us' to 'uk' to fetch UK results:
</pre>
<pre class="wp-block-syntaxhighlighter-code">payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'uk'}
r = requests.get('https://api.scraperapi.com/structured/google/search', params=payload)
data = r.json()
with open('uk_google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in uk_google_results.json")</pre
>
Output:
</pre>
{
"position": 11,
"title": "Sofas \u2013 Full Sofa Collection",
"snippet": "Sofas - Complete your living room with a stylish sofa finished in premium leather or luxury fabric, for incredible comfort. Browse the collection online.",
"highlighs": [
"Sofas",
"sofa"
],
"link": "https://www.furniturevillage.co.uk/sofas-and-armchairs/sofas/",
"displayed_link": "https://www.furniturevillage.co.uk \u203a Sofas & Chairs"
},
{
"position": 12,
"title": "Sofa Club | Order Today, Delivered Tomorrow.",
"snippet": "Welcome to Sofa Club, the UK's number one destination for statement neutral sofas. \u00b7 NEXT DAY DELIVERY \u00b7 FREE RETURNS \u00b7 RECYCLE YOUR SOFA \u00b7 0% FINANCE.",
"highlighs": [
"Sofa",
"sofas",
"SOFA"
],
"link": "https://sofaclub.co.uk/",
"displayed_link": "https://sofaclub.co.uk"
}, …
Note: We’re only showing a portion of the response due to space constraints.
By comparing the us_google_results.json and uk_google_results.json files, you’ll notice differences in the search results, such as:
- Different top-ranking websites
- Currency differences in shopping results (USD vs GBP)
- Region-specific product names or descriptions
- Localized ad content
These differences highlight the importance of geo-targeting in SEO strategies. Startups can gain valuable insights into how search results vary across regions, which allows them to tailor their strategies to specific geographic markets and improve their clients’ global SEO performance.
5. Feed Custom Dashboards
Web scrapers can be used to collect large amounts of data that feed into custom dashboards, providing an interactive platform for analysis. By integrating real-time data into these dashboards, businesses can present complex information in an accessible and visually appealing way.
Concisely, these are the benefits of feeding custom dashboards with scraped data:
- Real-Time Ranking Updates: SEO businesses can track keyword rankings as they fluctuate, allowing immediate strategy adjustments. Real-time data ensures that you and your clients are always informed about current positions in search results.
- Competitive Analysis Charts: Dashboards make it easier to visualize how your clients stack up against competitors across various SEO metrics. Charts and graphs can highlight areas where your clients excel or need improvement.
- Keyword Performance Trends: You can monitor the performance of specific keywords over time. Trend lines and historical data help identify which keywords drive traffic and which may require optimization.
6. Build Custom Tools
Your website should aim to rank among the top five results. SEO tools play an important role in this process by helping optimize your web content to meet search engine requirements, automate tasks, and enhance efficiency.
There are three common categories of SEO tools:
- Keyword Tools: Keyword tools like generators, analyzers, and monitors help you discover new keyword ideas, analyze their competitiveness, and track their performance over time.
- Backlink Tools: Backlink tools allow you to search for opportunities by examining top-ranking websites’ backlink profiles. They also help you monitor your existing backlinks to ensure they remain valuable and don’t harm your site’s ranking.
- Domain Audit Tools: Also known as site audit tools, these ensure your website is technically sound. They help optimize elements like site speed, loading time, responsiveness, security certificates (SSL), and more.
An easy but efficient way to build custom SEO tools is to use APIs from existing services like ScraperAPI. By customizing the API to meet your specific needs, you can develop tools without starting from scratch. While building a custom SEO tool from an API still requires technical knowledge, it’s less complex than building one entirely on your own.
7. Automating Google Trends Research
Google Trends is a tool that represents trends. It doesn’t show search volume for keywords but instead displays these trends in a graph scaled based on the highest peak of interest over the time period you specify.
So why complicate the process by building a script? Like most things in web scraping, it comes down to time and scalability. You can enter each keyword individually and track different timeframes, which is fine until you have a list of hundreds of keywords.
Checking each one manually results in a lot of wasted time. Instead, using a scraping API, you can easily automate the reports for a list of keywords in a few seconds or minutes.
By using a scraping API to automate Google Trends data collection, businesses can:
- Track trending topics in their clients’ industries
- Identify seasonal trends for content planning
- Compare search interest across multiple keywords
- Discover related queries and topics
Read more: How To Scrape Google Trends
Using ScraperAPI to Scrape Google Search at Scale
ScraperAPI is a proxy management API and web scraping solution that handles everything from rotating and managing proxies to handling CAPTCHAs and browsers, retries, and data cleaning so our requests don’t get banned. This is great for a difficult site to scrape, like Google.
However, what makes ScraperAPI extra useful for sites like Google is that it provides auto-parsing functionality free of charge, so you don’t need to write and maintain your own parsers.
Now, let’s see how we can use ScraperAPI to collect data from 10 different keywords using ScraperAPI’s Google Search structured data endpoint (SDE).
Prerequisites
- Python v3.8 or above installed
- The requests library installed (you can install it using
pip install requests) - Your ScraperAPI API key. You can sign up for a free account here if you don’t have one
Step 1: Setting up the script and defining keywords
We begin by importing the necessary libraries, setting up our API key, and defining the list of keywords we want to search for.
import requests
import json
# Replace with your ScraperAPI key
api_key = 'Your_ScraperAPI_KEY'
# List of keywords to search
keywords = ['SEO tools', 'content marketing', 'link building', 'local SEO',
'technical SEO', 'keyword research', 'on-page SEO',
'off-page SEO', 'mobile SEO', 'voice search optimization']
base_url = 'https://api.scraperapi.com/structured/google/search'
Here, we import the required requests and JSON libraries, set up our ScraperAPI key (which you should replace with your actual key), and define a list of SEO-related keywords. The base_url variable contains the endpoint for ScraperAPI’s Google Search data extraction feature.
Step 2: Fetching data for each keyword
Now, we’ll iterate through our list of keywords, send a request to ScraperAPI for each one, and store the results.
results = []
for keyword in keywords:
params = {
'api_key': api_key,
'query': keyword,
'country': 'us'
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
print(f"fetching data for '{keyword}'")
data = response.json()
results.append({
'keyword': keyword,
'organic_results': data.get('organic_results', [])
})
else:
print(f"Error fetching data for '{keyword}': {response.status_code}
This code loops through each keyword in our list and sends a GET request to the ScraperAPI endpoint.
If the request is successful (status code 200), it prints a message indicating that data is being fetched for the keyword. Then, it extracts the 'organic_results' from the JSON response and adds it to our results list along with the keyword. If there’s an error, it prints an error message with the status code.
Step 3: Saving the results to a JSON file
Finally, we’ll save all the collected data to a JSON file for easy analysis and use in other applications.
</pre>
# Save results to a JSON file
with open('seo_search_results.json', 'w') as f:
json.dump(results, f, indent=2)
print("Search results saved to 'seo_search_results.json'")
This code opens a new file named 'seo_search_results.json' in write mode and writes our results list in JSON format, with an indent of 2 spaces for readability. Finally, it prints a message confirming that the results have been saved to the file.
Complete Script
Here’s the entire script combined for easy copying and pasting:
import requests
import json
# Replace with your ScraperAPI key
api_key = 'Your_ScraperAPI_KEY'
# List of keywords to search
keywords = ['SEO tools', 'content marketing', 'link building', 'local SEO',
'technical SEO', 'keyword research', 'on-page SEO',
'off-page SEO', 'mobile SEO', 'voice search optimization']
base_url = 'https://api.scraperapi.com/structured/google/search'
# Initialize a list to store results
results = []
for keyword in keywords:
params = {
'api_key': api_key,
'query': keyword,
'country': 'us'
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
print(f"Fetching data for '{keyword}'")
data = response.json()
results.append({
'keyword': keyword,
'organic_results': data.get('organic_results', [])
})
else:
print(f"Error fetching data for '{keyword}': {response.status_code}")
# Save results to a JSON file
with open('seo_search_results.json', 'w') as f:
json.dump(results, f, indent=2)
print("Search results saved to 'seo_search_results.json'")
Using DataPipeline Visual Interface (Low-Code)
For those who prefer a low-code solution, ScraperAPI’s DataPipeline offers a visual interface for setting up scraping tasks without writing code.
DataPipeline is ScraperAPI’s built-in scraping scheduler. It allows you to automate the entire scraping process from beginning to end. This tool’s integration with ScraperAPI’s Google SDEs is even better. Using these tools, businesses can set recurrent Google keyword scraping jobs to monitor search results, build tools, and feed dashboards with first-party SERP data without spending hundreds of hours building or maintaining complex infrastructures and parsers.
The extracted data can be accessed in various formats, including JSON, CSV, or Webhooks, making it easy to integrate into your existing projects and workflows.
Let’s use Datapipeline to perform the same task with more efficiency and less code:
- Log in to your ScraperAPI account and click “Create new DataPipeline project“. This is your central hub for managing all your scraping tasks.
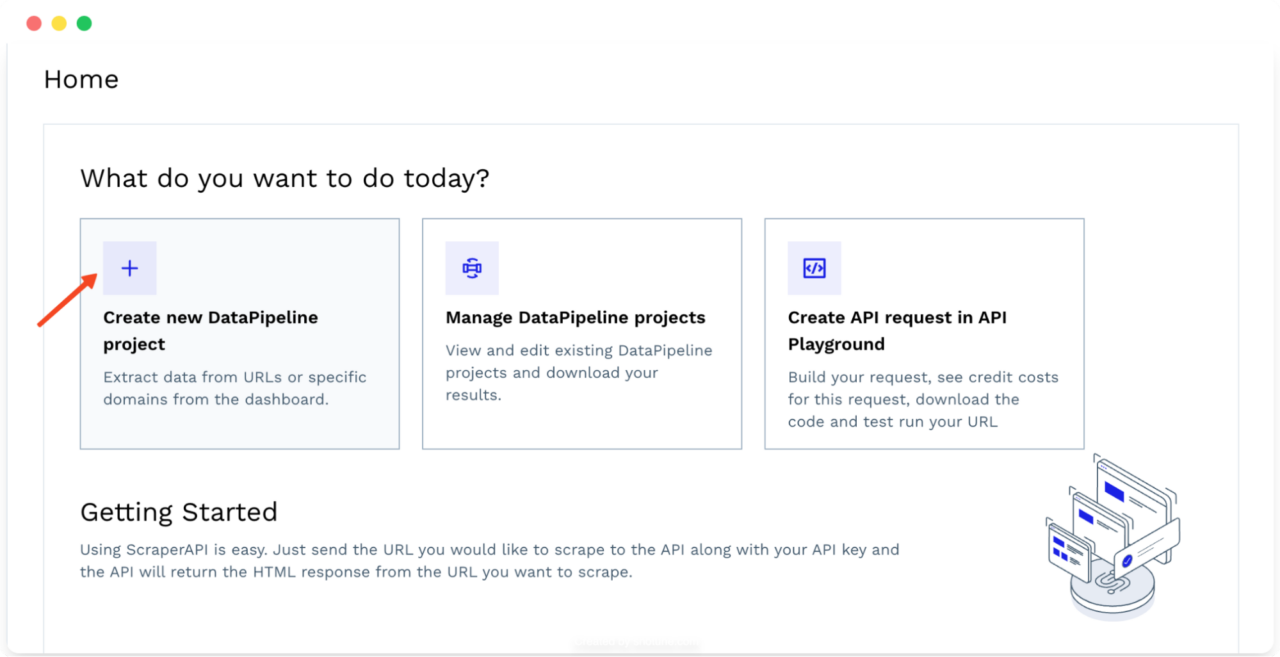
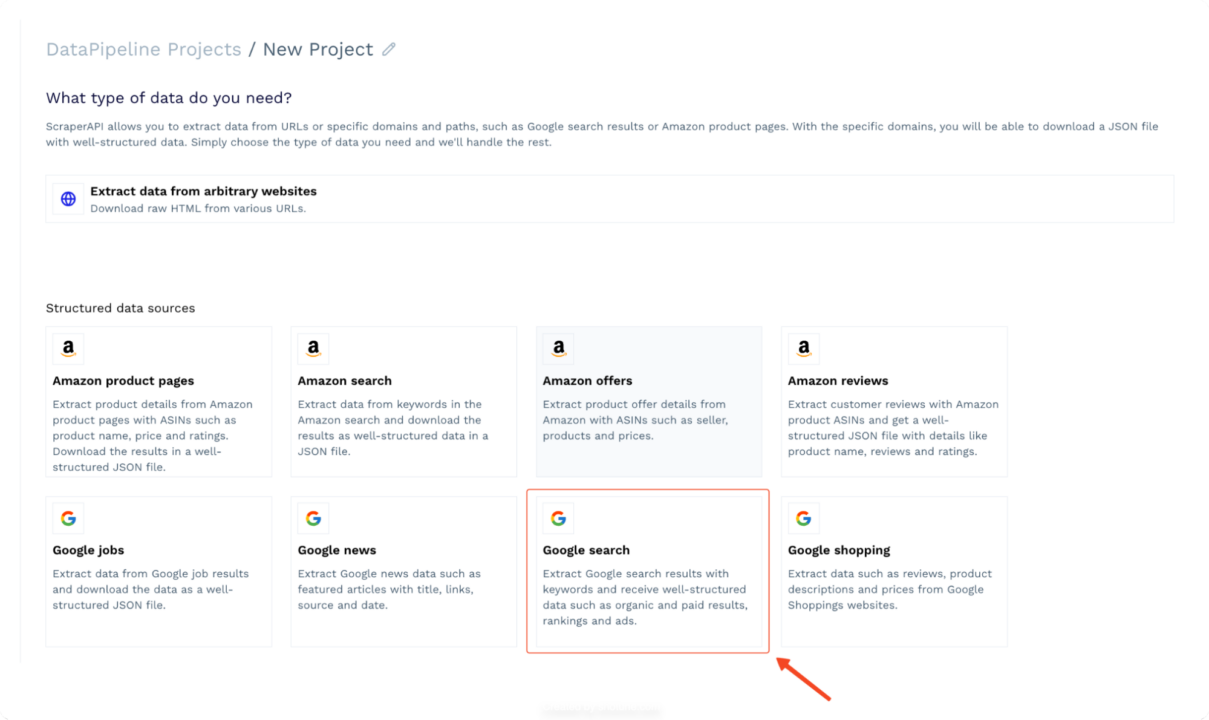
- Select the “Google Search” Extractor from the list of available extractors. This extractor is designed specifically for scraping Google Search results with keywords.
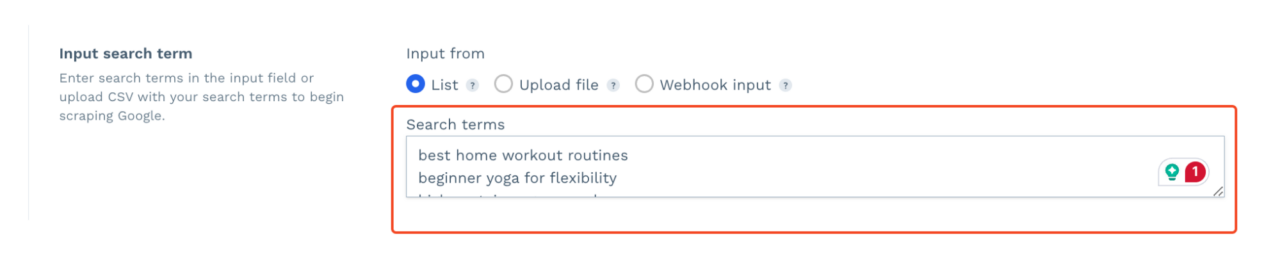
- Input your list of keywords that you wish to scrape. You can upload a CSV file, add a dynamic list via Webhook, or enter it manually.
- Choose your target location for geotargeting, select the domain, and set other preferences.
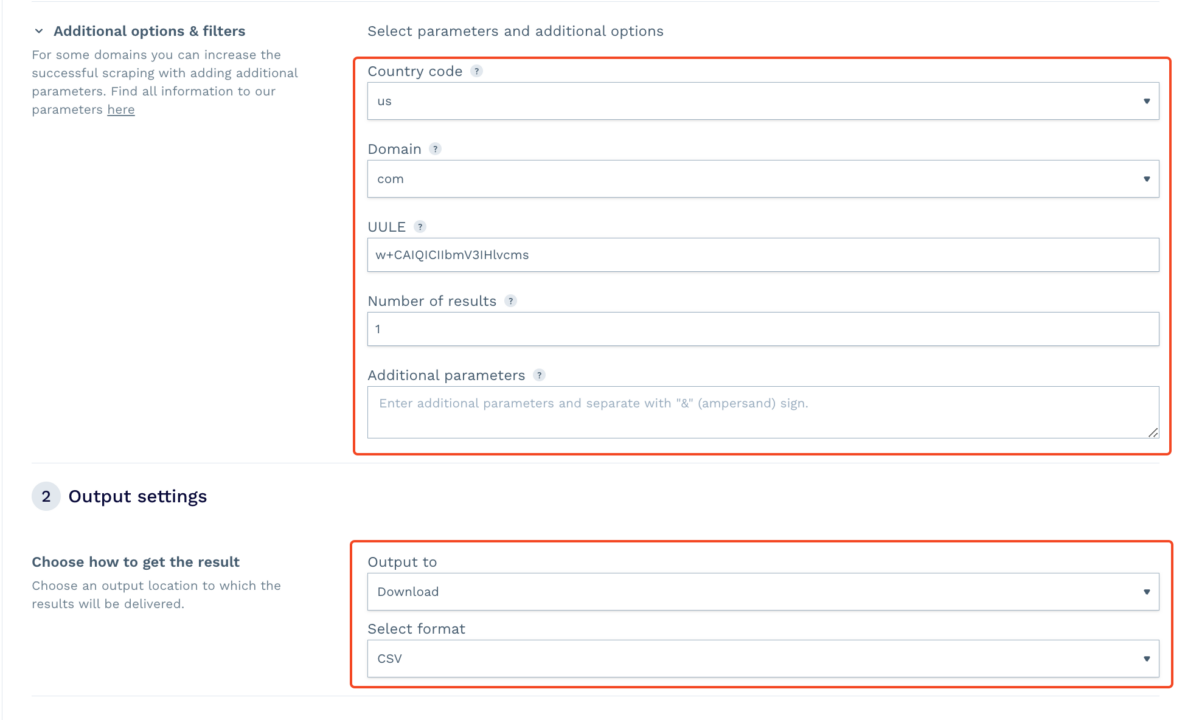
- Start the scraping task. DataPipeline will handle the rest. Once completed, you can download the resulting CSV or JSON file containing the scraped data. If you add a Webhook, you’ll receive the data directly in the folder or app you specified.
Pro Tip:
For more technical users who want to take advantage of DataPipeline’s scheduling capabilities, you can access the same functionalities via dedicated endpoints.
These will allow you to create and manage hundreds of projects directly from your codebase, adding an extra layer of automation to your workflows.
Wrapping Up
Scraping APIs have become indispensable tools for both global and local businesses looking to gain a competitive edge in today’s crowded market. By integrating these tools into your workflows, you can save time, reduce manual effort, and focus on delivering exceptional results for your clients.
Are you in need of large-scale SERP data? Contact our sales team to get started with a custom plan that includes all premium features, dedicated support Slack channels, and a dedicated account manager.




