



In this guide, you will learn how to:
- Set up and install Selenium for web scraping
- Perform tasks such as taking screenshots, scrolling, and clicking on elements
- Use Selenium in conjunction with BeautifulSoup for more efficient data extraction
- Handle dynamic content loading and infinite scrolling
- Identify and navigate around honeypots and other scraping obstacles
- Implement proxies to avoid IP bans and improve scraping performance
- Render JavaScript-heavy sites without relying solely on Selenium
Now, let’s dive into Selenium web scraping and unlock the full potential of automated data collection!
Project Requirements
Before starting with Selenium web scraping, ensure you have the following:
- Python installed on your machine (version 3.10 or newer)
pip(Python package installer)- A web driver for your chosen browser (e.g., ChromeDriver for Google Chrome)
Installation
First, you need to install Selenium. You can do this using pip:
pip install selenium
Next, download the web driver for your browser. For example, download ChromeDriver for Google Chrome and ensure it’s accessible from your system’s PATH.
Importing Selenium
Begin by importing the necessary modules:
-
webdriver: This is the main module of Selenium that provides all the WebDriver implementations. It allows you to initiate a browser instance and control its behavior programmatically.
from selenium import webdriver -
By: The
Byclass is used to specify the mechanism to locate elements within a webpage. It provides various methods like ID, name, class name, CSS selector, XPath, etc., which are crucial for finding elements on a webpage.from selenium.webdriver.common.by import By -
Keys: The
Keysclass provides special keys that can be sent to elements, such as Enter, Arrow keys, Escape, etc. It is useful for simulating keyboard interactions in automated tests or web scraping.from selenium.webdriver.common.keys import Keys -
WebDriverWait: This class is part of Selenium’s support UI module (
selenium.webdriver.support.ui) and allows you to wait for a certain condition to occur before proceeding further in the code. It helps in handling dynamic web elements that may take time to load.from selenium.webdriver.support.ui import WebDriverWait -
expected_conditions as EC: The
expected_conditionsmodule within Selenium provides a set of predefined conditions thatWebDriverWaitcan use. These conditions include checking for an element’s presence, visibility, clickable state, etc.from selenium.webdriver.support import expected_conditions as EC
These imports are essential for setting up a Selenium automation script. They provide access to necessary classes and methods to interact with web elements, wait for conditions, and simulate user actions on web pages effectively.
Setting Up the Web Driver
Initialize the web driver for your browser and configure options if needed:
chrome_options = webdriver.ChromeOptions()
# Add any desired options here, for example, headless mode:
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
This setup allows you to customize the Chrome browser’s behavior through chrome_options.
For example, you can run the browser in headless mode by uncommenting the --headless option. This means everything happens in the background, and you don’t see the browser window pop up.
Now, let’s get into scraping!
TL;DR: Selenium Scraping Basics
Here’s a quick cheat sheet to get you started with Selenium web scraping. Here, you’ll find essential steps and code snippets for common tasks, making it easy to jump straight into scraping.
Visiting a Site
To open a website, use the get() function:
driver.get("https://www.google.com")
Taking a Screenshot
To take a screenshot of the current page, use the save_screenshot() function:
driver.save_screenshot('screenshot.png')
Scrolling the Page
To scroll down the page, use the execute_script() function to scroll down to entire height of the page:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Clicking an Element
To click on an element (e.g., a button), use the find_element() function to locate the element, then call the click() function on the element:
button = driver.find_element(By.ID, "button_id")
button.click()
Waiting for an Element
To wait for an element to become visible:
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, "element_id"))
)
Handling Infinite Scrolling
To handle infinite scrolling, you can repeatedly scroll to the bottom of the page until no new content loads:
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for new content to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
Combining Selenium with BeautifulSoup
For more efficient data extraction, you can use BeautifulSoup alongside Selenium:
from bs4 import BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Now you can use BeautifulSoup to parse the HTML content like normal
By following these steps, you can handle most common web scraping tasks using Selenium.
If you want to dive deeper into web scraping with selenium, keep reading!
How to Use Selenium for Web Scraping
Step 1: Configuring ChromeOptions
To customize how Selenium interacts with the Chrome browser, start by configuring ChromeOptions:
chrome_options = webdriver.ChromeOptions()
This sets up chrome_options using webdriver.ChromeOptions(), allowing us to tailor Chrome’s behavior when controlled by Selenium.
Optional: Customizing ChromeOptions
You can further customize ChromeOptions. For instance, add the line below to enable headless mode:
chrome_options.add_argument("--headless")
Enabling headless mode (--headless) runs Chrome without a visible user interface, which is perfect for automated tasks where you don’t need to see the browser.
Step 2: Initializing WebDriver with ChromeOptions
Next, initialize the Chrome WebDriver with the configured ChromeOptions:
driver = webdriver.Chrome(options=chrome_options)
This line prepares Selenium to control Chrome based on the specified options, setting the stage for automated interactions with web pages.
Step 3: Navigating to a Website
To direct the WebDriver to the desired URL, use the get() function. This command tells Selenium to open and load the webpage, allowing you to start interacting with the site.
driver.get("https://google.com/")
After you’re done with your interactions, use the quit() method to close the browser and end the WebDriver session.
driver.quit()
In summary, get() loads the specified webpage, while quit() closes the browser and terminates the session, ensuring a clean exit from your scraping tasks.
Step 4: Taking a Screenshot
To screenshot the current page, use the save_screenshot() function. This can be useful for debugging or saving the state of a page.
driver.save_screenshot('screenshot.png')
This takes a screenshot of the page and saves it in an image called screenshot.png.
Step 5: Scrolling the Page
Scrolling is essential for interacting with dynamic websites that load additional content as you scroll. Selenium provides the execute_script() function to run JavaScript code within the browser context, enabling you to control the page’s scrolling behavior.
Scrolling to the Bottom of the Page
To scroll down to the bottom of the page, you can use the following script. This is particularly useful for loading additional content on dynamic websites.
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
This JavaScript code scrolls the browser window to the height of the document body, effectively moving to the bottom of the page.
Scrolling to a Specific Element
If you want to scroll to a specific element on the page, you can use the scrollIntoView() method. This is useful when interacting with elements not visible in the current viewport.
element = driver.find_element(By.ID, "element_id")
driver.execute_script("arguments[0].scrollIntoView(true);", element)
This code finds an element by its ID and scrolls the page until the element is in view.
Handling Infinite Scrolling
For pages that continuously load content as you scroll, you can implement a loop to scroll down repeatedly until no more new content is loaded. Here’s an example of how to handle infinite scrolling:
import time
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # Wait for new content to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
This loop scrolls to the bottom of the page, waits for new content to load, and checks if the scroll height has increased. If the height remains the same, it breaks out of the loop, indicating that no more content is loading.
Scrolling Horizontally
In some cases, you might need to scroll horizontally, for example, to interact with elements in a wide table. Use the following script to scroll horizontally:
driver.execute_script("window.scrollBy(1000, 0);")
This code scrolls the page 1000 pixels to the right. Adjust the value as needed for your specific use case.
These scrolling techniques with Selenium ensure all necessary content is loaded and accessible for interaction or scraping. These methods are essential for effectively navigating and extracting data from dynamic websites.
Step 6: Interacting with Elements
Interacting with web page elements often involves clicking buttons or links and inputting text into fields before scraping their content.
Selenium provides various strategies to locate elements on a page using the By class and the find_element() and find_elements() methods.
Here’s how you can use these locator strategies to interact with elements:
Locating Elements
Selenium offers multiple ways to locate elements on a webpage using the find_element() method for a single element and the find_elements() method for various elements:
-
By ID: Locate an element by its unique ID attribute.
driver.find_element(By.ID, "element_id") -
By Name: Locate an element by its name attribute.
driver.find_element(By.NAME, "element_name") -
By Class Name: Locate elements by their CSS class name.
driver.find_element(By.CLASS_NAME, "element_class") -
By Tag Name: Locate elements by their HTML tag name.
driver.find_element(By.TAG_NAME, "element_tag") -
By Link Text: Find hyperlinks by their exact visible text.
driver.find_element(By.LINK_TEXT, "visible_text") -
By Partial Link Text: Locate hyperlinks by a partial match of their visible text.
driver.find_element(By.PARTIAL_LINK_TEXT, "partial_text") -
By CSS Selector: Use CSS selectors to locate elements based on CSS rules.
driver.find_element(By.CSS_SELECTOR, "css_selector") -
By XPath: Locate elements using their XPATH. XPath is a powerful way to locate elements using path expressions.
driver.find_element(By.XPATH, "xpath_expression")
Clicking an Element
To click on an element, locate it using one of the strategies above and then use the click() method.
# Example: Clicking a button by ID
button = driver.find_element(By.ID, "button_id")
button.click()
# Example: Clicking a link by Link Text
link = driver.find_element(By.LINK_TEXT, "Click Here")
link.click()
Typing into a Textbox
To input text into a field, locate the element and use the send_keys() method.
# Example: Typing into a textbox by Name
textbox = driver.find_element(By.NAME, "username")
textbox.send_keys("your_username")
# Example: Typing into a textbox by XPath
textbox = driver.find_element(By.XPATH, "//input[@name='username']")
textbox.send_keys("your_username")
Retrieving Text from an Element
Locate the element’s text content and use the text attribute to get the text content.
# Example: Retrieving text by Class Name
element = driver.find_element(By.CLASS_NAME, "content")
print(element.text)
# Example: Retrieving text by Tag Name
element = driver.find_element(By.TAG_NAME, "p")
print(element.text)
Getting Attribute Values
After locating the element, use the get_attribute() method to retrieve attribute values, such as URLs, from anchor tags.
# Example: Getting the href attribute from a link by Tag Name
link = driver.find_element(By.TAG_NAME, "a")
print(link.get_attribute("href"))
# Example: Getting src attribute from an image by CSS Selector
img = driver.find_element(By.CSS_SELECTOR, "img")
print(img.get_attribute("src"))
You can effectively interact with various elements on a webpage using these locator strategies provided by Selenium’s By class. Whether you need to click a button, enter text into a form, retrieve text, or get attribute values, these methods will help you efficiently automate your web scraping tasks.
Step 7: Identifying Honeypots
Honeypots are elements deliberately hidden from regular users but visible to bots. They are designed to detect and block automated activities like web scraping. Selenium allows you to detect and avoid interacting with these elements effectively.
You can use CSS selectors to identify elements hidden from view using styles like display: none; or visibility: hidden;. Selenium’s find_elements method with By.CSS_SELECTOR is handy for this purpose:
elements = driver.find_elements(By.CSS_SELECTOR, '[style*="display:none"], [style*="visibility:hidden"]')
for element in elements:
if not element.is_displayed():
continue # Skip interacting with honeypot elements
Here, we check if the element is not displayed on the webpage using the is_displayed() method. This ensures that interactions are only performed with elements intended for user interaction, thus bypassing potential honeypots.
A common form of honeypot is a disguised button element. These buttons are visually hidden from users but exist within the HTML structure of the page:
<pre class="wp-block-syntaxhighlighter-code"> <button id="fakeButton" style="display: none;">Click Me</button>
</pre>
In this scenario, the button is intentionally hidden. An automated bot programmed to click all buttons on a page might interact with this hidden button, triggering security measures on the website. Legitimate users, however, would never encounter or engage with such hidden elements.
Using Selenium, you can effectively navigate around these traps by verifying the visibility of elements before interacting with them. As previously mentioned, the is_displayed() method confirms whether an element is visible to users. Here’s how you can implement this safeguard in your Selenium script:
from selenium import webdriver
# Set your WebDriver options
chrome_options = webdriver.ChromeOptions()
# Initialize the WebDriver
driver = webdriver.Chrome(options=chrome_options)
# Navigate to a sample website
driver.get("https://example.com")
# Locate the hidden button element
button_element = driver.find_element_by_id("fakeButton")
# Check if the element is displayed
if button_element.is_displayed():
# Element is visible; proceed with interaction
button_element.click()
else:
# Element is likely a honeypot, skip interaction
print("Detected a honeypot element, skipping interaction")
# Close the WebDriver session
driver.quit()
Things to note when identifying and avoiding honeypots:
- Always use
is_displayed()to check if an element is visible before interacting with it, distinguishing between real UI elements and hidden traps like honeypots - When automating interactions (like clicks or form submissions), ensure your script avoids accidentally interacting with hidden or non-visible elements
- Follow website rules and legal guidelines when scraping data to stay ethical and avoid getting flagged by website security measures
By integrating these practices into your Selenium scripts, you enhance their reliability and ethical compliance, safeguarding your automation efforts while respecting the intended use of web resources.
Step 8: Waiting for Elements to Load
Dynamic websites often load content asynchronously, which means elements may appear on the page after the initial page load.
To avoid errors in your web scraping process, it’s crucial to wait for these elements to appear before interacting with them. Selenium’s WebDriverWait and expected_conditions allow us to wait for specific conditions to be met before proceeding.
In this example, I’ll show you how to wait for the search bar to load on Amazon’s homepage, perform a search, and then extract the ASINs of Amazon products in the search results.
To begin, we’ll locate the search bar element on the homepage. Navigate to Amazon, right-click on the search bar, and select “Inspect” to open the developer tools.
We can see that the search bar element has the id of twotabsearchtextbox.
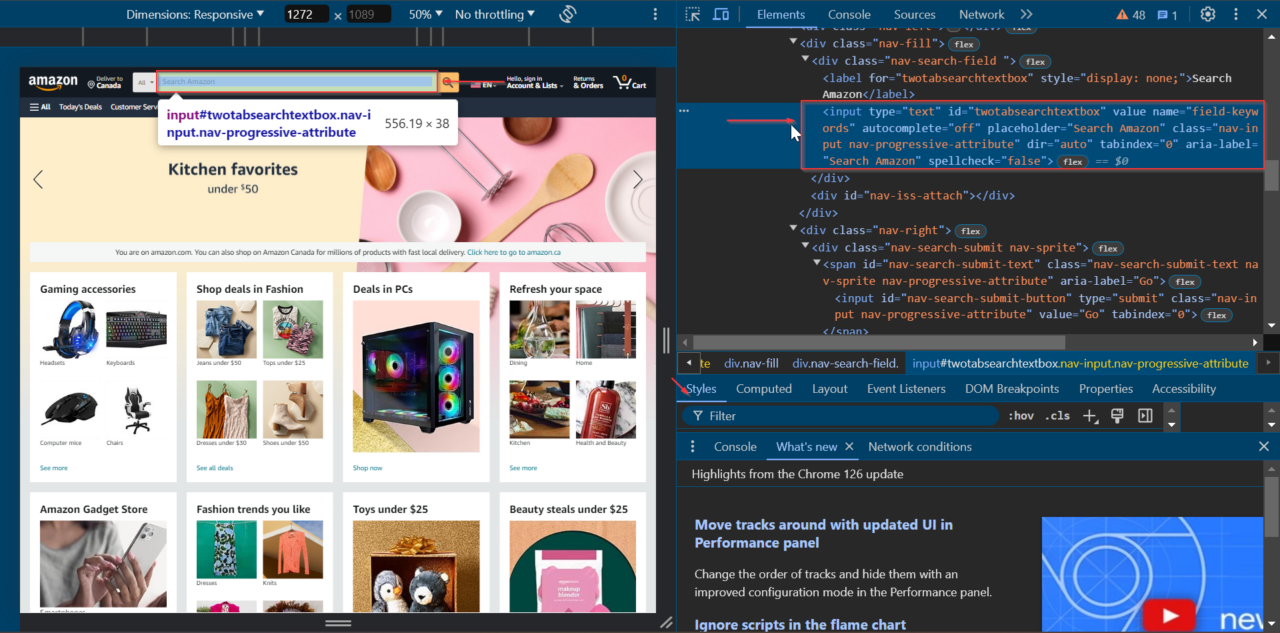
Let’s start by setting up our Selenium WebDriver and navigating to Amazon’s homepage.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Set up the web driver
chrome_options = webdriver.ChromeOptions()
# Uncomment the line below to run Chrome in headless mode
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# Open Amazon's homepage
driver.get("https://amazon.com/")
Next, use WebDriverWait to wait for the search bar element to be present before interacting with it. This ensures that the element is fully loaded and ready for interaction.
# Wait for the search bar to be present
search_bar = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "twotabsearchtextbox"))
)
Next, enter your search term into the search bar using the send_keys() method and submit the form using the submit() method. In this example, we’ll search for headphones.
# Perform a search for "headphones"
search_bar.send_keys("headphones")
# Submit the search form (press Enter)
search_bar.submit()
Include a short wait using the time.sleep() method to ensure that the search results page has enough time to load.
# Wait for the search results to load
time.sleep(10)
After the search results have loaded, extract the ASINs of the products in the search results. We’ll use BeautifulSoup to parse the page source and extract the data.
from bs4 import BeautifulSoup
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
products = []
# Extract product ASINs
productsHTML = soup.select('div[data-asin]')
for product in productsHTML:
if product.attrs.get('data-asin'):
products.append(product.attrs['data-asin'])
print(products)
Finally, close the browser and end the WebDriver session.
# Quit the WebDriver
driver.quit()
Putting it all together, the complete code looks like this:
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Set up the web driver
chrome_options = webdriver.ChromeOptions()
# Uncomment the line below to run Chrome in headless mode
# chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# Open Amazon's homepage
driver.get("https://amazon.com/")
# Wait for the search bar to be present
search_bar = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "twotabsearchtextbox"))
)
# Perform a search for "headphones"
search_bar.send_keys("headphones")
# Submit the search form (press Enter)
search_bar.submit()
# Wait for the search results to load
time.sleep(10)
# Extract product ASINs
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
products = []
productsHTML = soup.select('div[data-asin]')
for product in productsHTML:
if product.attrs.get('data-asin'):
products.append(product.attrs['data-asin'])
print(products)
# Quit the WebDriver
driver.quit()
Now, you can effectively use WebDriverWait to handle dynamic elements and ensure they are loaded before interacting with them. This approach makes your web scraping scripts more reliable and effective.




