



In this article, you’ll learn how to:
- Use Python and BeautifulSoup to extract data from TechCrunch
- Export this vital information into a CSV file
- Use ScraperAPI to bypass TechCrunch’s anti-scraping measures effectively
Ready to dive into tech industry news scraping? Let’s get started!
TL;DR: Full TechCrunch Scraper
Here’s the completed code for those in a hurry:
from bs4 import BeautifulSoup
import requests
import csv
# Define the TechCrunch URL
news_url = "https://techcrunch.com"
# Set up Scraper API parameters
payload = {'api_key': 'YOUR_API_KEY', 'url': news_url, 'render': 'true'}
# Request via Scraper API
response = requests.get('https://api.scraperapi.com', params=payload)
# Parse HTML with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
articles = soup.find_all('article', {"class": "post-block post-block--image post-block--unread"})
# Open CSV file
with open('techcrunch_news.csv', 'a', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(['Title', 'Author', 'Publication Date', 'Summary', "URL", "Category"])
if articles:
# Iterate over articles
for article in articles:
title = article.find("a", attrs={"class": "post-block__title__link"}).text
url = article.find("a", attrs={"class": "post-block__title__link"})['href']
complete_url = news_url + url
summary = article.find("div", attrs={"class": "post-block__content"}).text
date = article.find("time", attrs={"class": "river-byline__full-date-time"}).text
author_span = article.find("span", attrs={"class": "river-byline__authors"})
author = author_span.find("a").text if author_span else None
category = article.find("a", attrs={"class":"article__primary-category__link gradient-text gradient-text--green-gradient"}).text
# Write row to CSV
csv_writer.writerow([title, author, date, summary, complete_url, category])
else:
print("No article information found!")
Before running the code, add your API key to the api_key parameter within the payload.
Note: Don’t have an API key? Create a free ScraperAPI account to get 5,000 API credits to try all our tools for 7 days.
Want to see how we built it? Keep reading and join us on this exciting scraping journey!
Why Should You Scrape Tech News?
Scraping tech news, especially from sources like TechCrunch, is important for several reasons:
- Stay Updated with Trends: It’s essential to keep up with the latest developments in technology and startups.
- Market Research: Gain insights into emerging markets, technologies, and competitive landscapes.
- Content Strategy: Helps align your content with current tech trends for better engagement.
- Find Investment Opportunities: Understanding the state of a company can help you make more accurate investment decisions.
However, achieving this requires the right tools.
TechCrunch, with its advanced site structure, requires sophisticated scraping methods to avoid access issues.
Using services like ScraperAPI is crucial here; it skillfully navigates through potential roadblocks like CAPTCHAs and anti-scraping technologies. This ensures uninterrupted access to global tech news, making your market analysis and strategy more robust and informed.
In this tutorial, we’ll utilize a free ScraperAPI account to simplify our scraping process. This will enable us to extract tech news data from TechCrunch efficiently, streamlining our task and allowing us to start gathering valuable insights within minutes.
Scraping TechCrunch with Python
For this tutorial, we’ll target the latest articles on TechCrunch’s homepage. We’ll use a loop in our script to go through these articles, extracting the data we need from them. This method allows us to efficiently scrape multiple articles in a single automated process, capturing TechCrunch’s most recent and relevant news.
Requirements
To scrape TechCrunch news using Python, you must prepare your environment with essential tools and libraries.
Here’s a step-by-step guide to get you started:
- Python Installation: Make sure you have Python installed, preferably version 3.8 or later.
- Library Installations: Open your terminal or command prompt and run the following command to install the necessary libraries:
pip install requests bs4
- Create a new directory and Python file: Open your terminal or command prompt and run the following commands:
$ mkdir techcrunch_scraper $ touch techcrunch_scraper/app.py
Now that you’ve set up your environment and project structure, you’re ready to proceed with the next part of the tutorial.
Understanding TechCrunch’s Website Layout
A clear understanding of TechCrunch’s website layout is key for efficient data scraping. It enables us to pinpoint the specific elements we need and understand how to access them.
In our case, we’re looking at the latest articles on TechCrunch, highlighted in the image below:
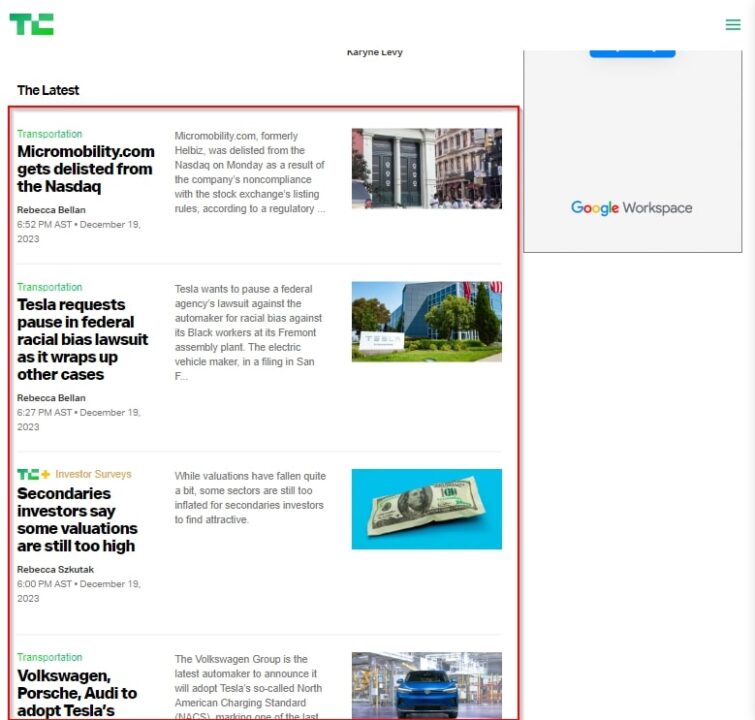
Our goal is to scrape the title, URL, a brief content snippet, the author, category, and the date it was published.
To do this, we’ll use the developer tools (right-click on the webpage and select ‘inspect’) to examine the HTML structure.
This article tag holds all the information of each individual article: .post-block post-block--image post-block--unread.
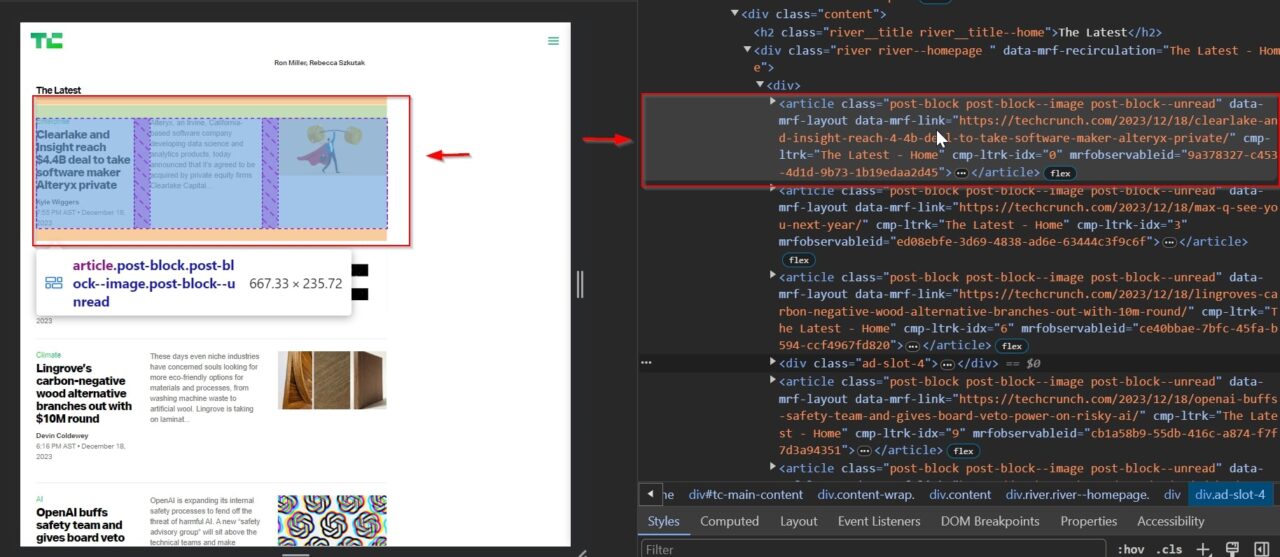
This a tag contains the article title and the URL: .post-block__title__link.
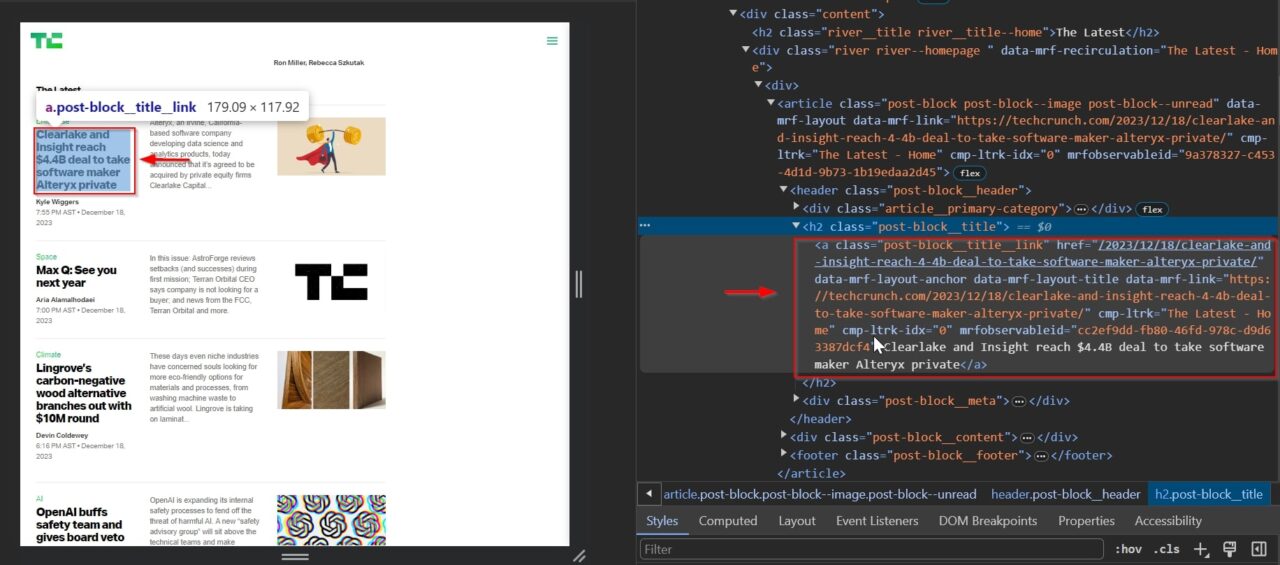
This span tag contains the article’s author within an a tag: .river-byline__authors.
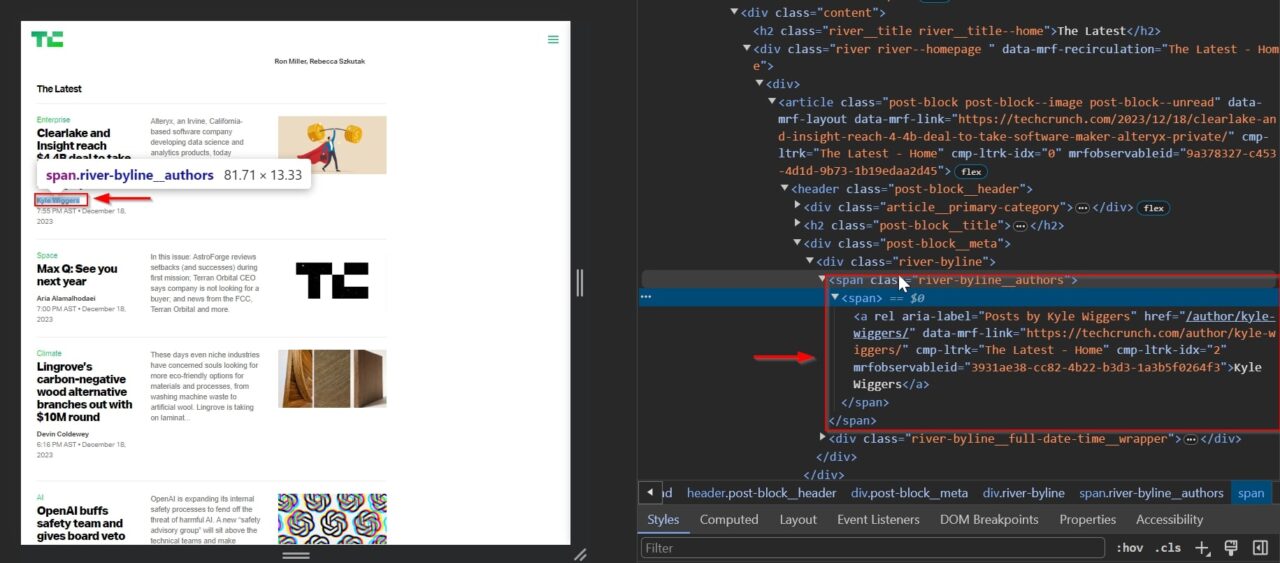
The article content summary is essential for understanding the full context and depth of the subject matter discussed in the article.
This div tag contains the summary: .post-block__content.
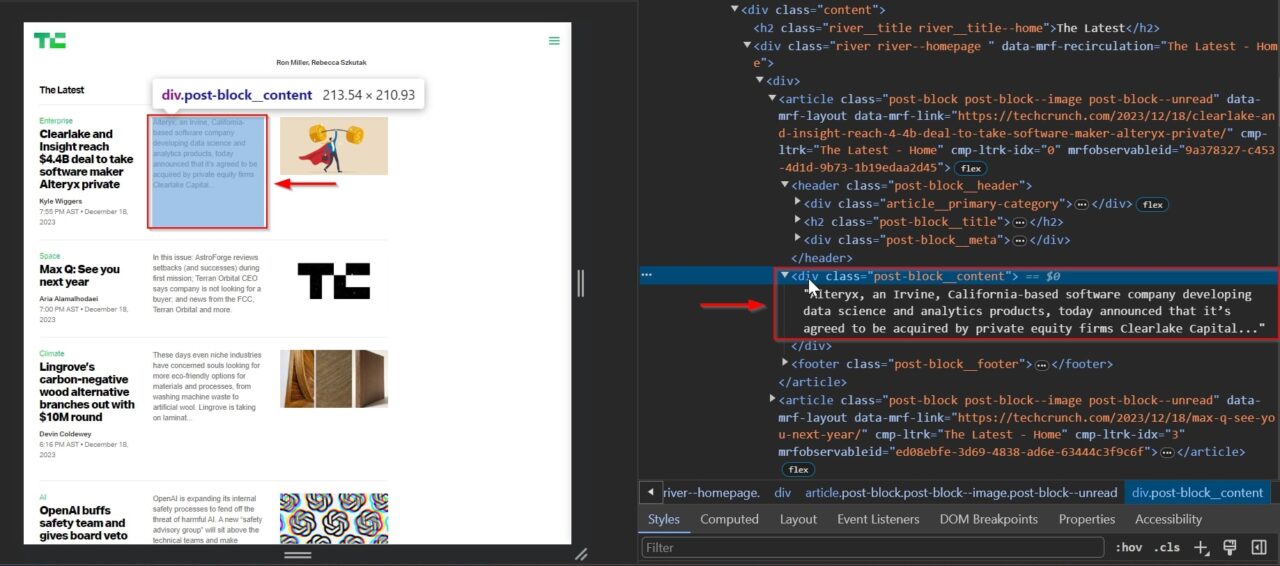
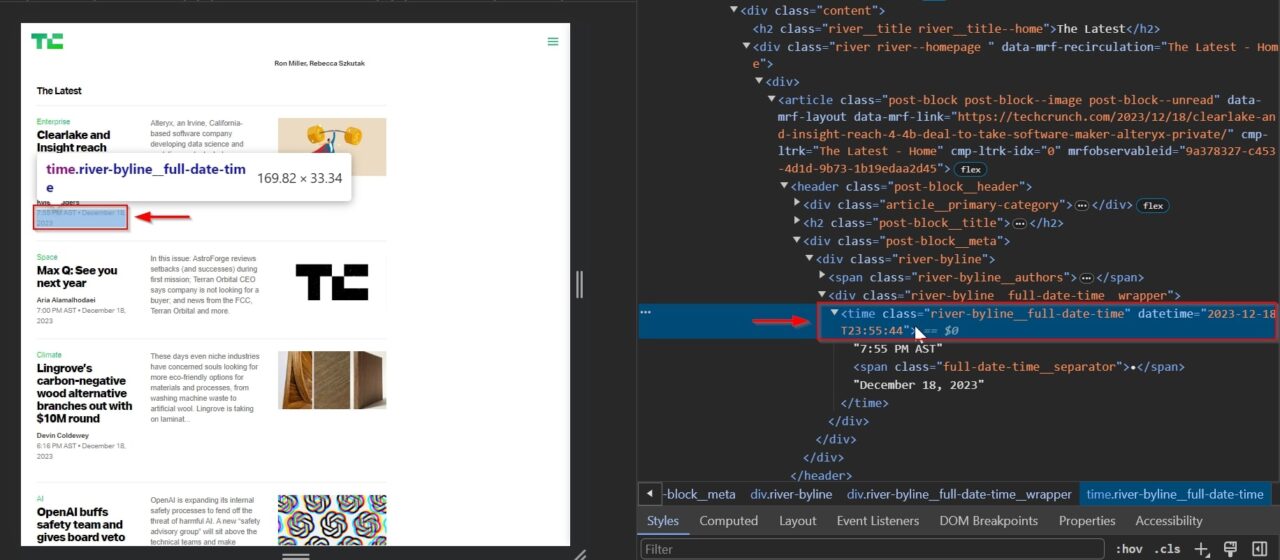
The date the article was published helps in analyzing how current the information is or tracking trends over time.
This time tag contains the date: .river-byline__full-date-time.
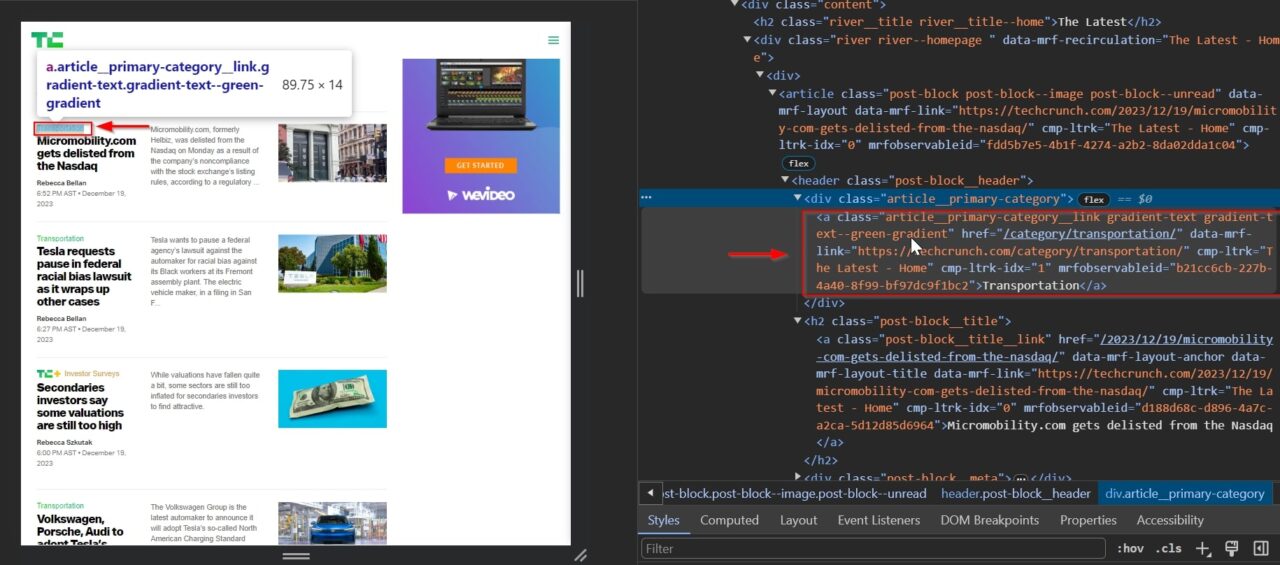
The category the article is in can indicate the broader subject area or specific interests, like startups, AI, etc.
This a tag contains the category: .article__primary-category__link gradient-text gradient-text--green-gradient.
Now that we have this knowledge let’s start scraping!
Step 1: Import Libraries
First, we need to import the necessary libraries for our scraper, and we also define the URL of TechCrunch as our target for scraping news articles.
from bs4 import BeautifulSoup
import requests
import csv
news_url = "https://techcrunch.com"
Step 2: Sending Request Via ScraperAPI
To scrape TechCrunch without getting blocked, we utilize ScraperAPI. It deals with potential anti-bot measures like IP rotation and CAPTCHA handling.
Note: It will also rotate our proxies and headers using machine learning and statistical analysis to find the best combination.
We’ll send our target URL within a payload, which contains our ScraperAPI key, the TechCrunch URL, and instructions to render JavaScript content. This setup ensures our scraper can access and retrieve data from TechCrunch efficiently.
payload = {'api_key': 'YOUR_API_KEY', 'url': news_url, 'render': 'true'}
Next, we send the setup (payload) to ScraperAPI. We are essentially instructing the API to visit TechCrunch on our behalf, render the page, and collect the news.
response = requests.get('https://api.scraperapi.com', params=payload)
💡 Pro Tip
If you don’t set
rendertotrue, the resulting HTML is different from the one you see in your browser.In the case you don’t want to render the page, you can still get most of the data. The only thing you won’t be getting is the article’s category, and you’ll have to change a couple of CSS selectors.
Step 3: Parsing HTML Content with BeautifulSoup
Next, we create a soup object, telling it to parse the HTML using html.parser. This helps us focus on specific parts of the TechCrunch page where articles are listed.
To do so, we look for the article tags we identified earlier that contain the data we are looking for.
soup = BeautifulSoup(response.content, 'html.parser')
articles = soup.find_all('article', {"class": "post-block post-block--image post-block--unread"})
Step 4: Opening a CSV File for Data Storage
To create our CSV file, we will:
- Open a CSV file named techcrunch_news.csv to store the article information
- Prepare the file to append each article’s details as a new row
- Set up the CSV writer and define our column headers: ‘Title’, ‘Author’, ‘Publication Date’, ‘Summary’, ‘URL’, and ‘Category’
with open('techcrunch_news.csv', 'a', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(['Title', 'Author', 'Publication Date', 'Summary', "URL", "Category"])
This step organizes our file, so it’s all set to receive the data we’re about to collect from each TechCrunch article.
Step 5: Extracting Article Information
All the articles’ containers are inside the articles variable, so we can create a loop to grab the title, URL, summary, author, publication date, and category of each article and write it into our CSV file.
Additionally, we’ll include an if statement in our script to handle situations where no articles are found. This helps prevent errors and ensures our scraper runs smoothly, only capturing data when articles are available.
if articles:
for article in articles:
title = article.find("a", attrs={"class": "post-block__title__link"}).text
url = article.find("a", attrs={"class": "post-block__title__link"})['href']
complete_url = news_url + url
summary = article.find("div", attrs={"class": "post-block__content"}).text
date = article.find("time", attrs={"class": "river-byline__full-date-time"}).text
author_span = article.find("span", attrs={"class": "river-byline__authors"})
author = author_span.find("a").text if author_span else None
category = article.find("a", attrs={"class":"article__primary-category__link gradient-text gradient-text--green-gradient"}).text
csv_writer.writerow([title, author, date, summary, complete_url, category])
Error Handling
The else statement handles the scenario where no articles are found on the page.
else:
print("No article information found!")
Fantastic, you’ve successfully scraped TechCrunch!




