



TL;DR: Product Price Scraper
If you’re already comfortable with web scraping and just want a quick solution, here’s the Python code I used to scrape product prices from Zara using Scrapy and Beautifulsoup:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scraperapi_url(url):
APIKEY = "YOUR_SCRAPERAPI_KEY"
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = [
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
]
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Before running the script, make sure you have Scrapy installed (pip install scrapy). Also,
create a free ScraperAPI account
and replace “YOUR_SCRAPERAPI_KEY” with your actual API key – this
way, we’ll successfully bypass any challenges when scraping Zara’s product
prices.
Why Scrape Prices?
Keeping tabs on competitor pricing is vital to business success. By automating the process of collecting and analyzing pricing data, you can stay informed about your competitors’ strategies and make better decisions for your own business.
Here are three big use cases for pricing data:
- Dynamic Pricing: Having access to real-time competitor pricing data empowers you to implement dynamic pricing strategies. You’ll be able to adjust your prices based on market fluctuations, demand trends, and competitor actions, maximizing your profits.
- Market Research and Insights: Price scraping goes beyond knowing what your competitors charge. It can help you identify pricing trends within your industry, understand cost structures, and gain insights into buyer behavior.
- Agility and Adaptability: Market dynamics can shift quickly, and price changes often follow suit. By scraping prices regularly, you can stay updated about these changes and react swiftly, whether by adjusting your own prices or adapting your marketing messaging.
Of course, there are many other use cases for product price data. However, you’ll need to build a dataset to analyze before you can do anything.
Scraping Product Prices with Python
For this project, let’s build a web scraper to extract price data from Zara’s men’s shirt collection. While we’re focusing on Zara, the concepts in this guide can be applied to any e-commerce site.
Let’s begin!
Project Requirements
These are the tools and libraries you’ll need for this project:
- Python version 3.8 or newer
-
Virtual Environments: Create a virtual environment to isolate your project dependencies. This step isn’t mandatory but can help you manage dependencies effectively.
python3 -m venv .venv # On Windows .venv\Scripts\activate # On macOS/Linux source .venv/bin/activate - Scrapy and BeautifulSoup libraries installed
You can install them using pip:
pip install scrapy beautifulsoup4
Scrapy is an all-in-one suite for crawling the web, downloading documents, processing them, and storing the resulting data in an accessible format. It works with spiders, which are Python classes that define how to navigate a website.
BeautifulSoup is a Python library that simplifies the parsing of HTML content from web pages. It’s an indispensable tool for extracting data.
-
A ScraperAPI account – sign up and get 5,000 free API credits to get started.

Note: If you need to install everything from scratch, follow our tutorial on the basics of Scrapy in Python. I’ll use the same setup, so get that done and come back.
Step 1: Setting Up Scrapy
First, let’s set up Scrapy. Start by creating a new Scrapy project:
scrapy startproject price_scraper
This command creates a new price_scraper directory with the necessary files for a Scrapy project.
Now, if you list the contents of this directory, you should see the following structure:
$ cd price_scraper
$ tree
.
├── price_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
└── scrapy.cfg
Our Scrapy project setup is complete!
Step 2: Overview of Zara’s Website Structure
Before starting to code the spider, it’s crucial to understand the structure of the website you’re about to scrape.
Open the men’s shirts section of Zara’s website in your browser, right-click, and select “Inspect” to open the Developer Tools.
Look through the HTML source code to identify the necessary HTML selectors. Specifically, look for the elements that contain the product name and price.
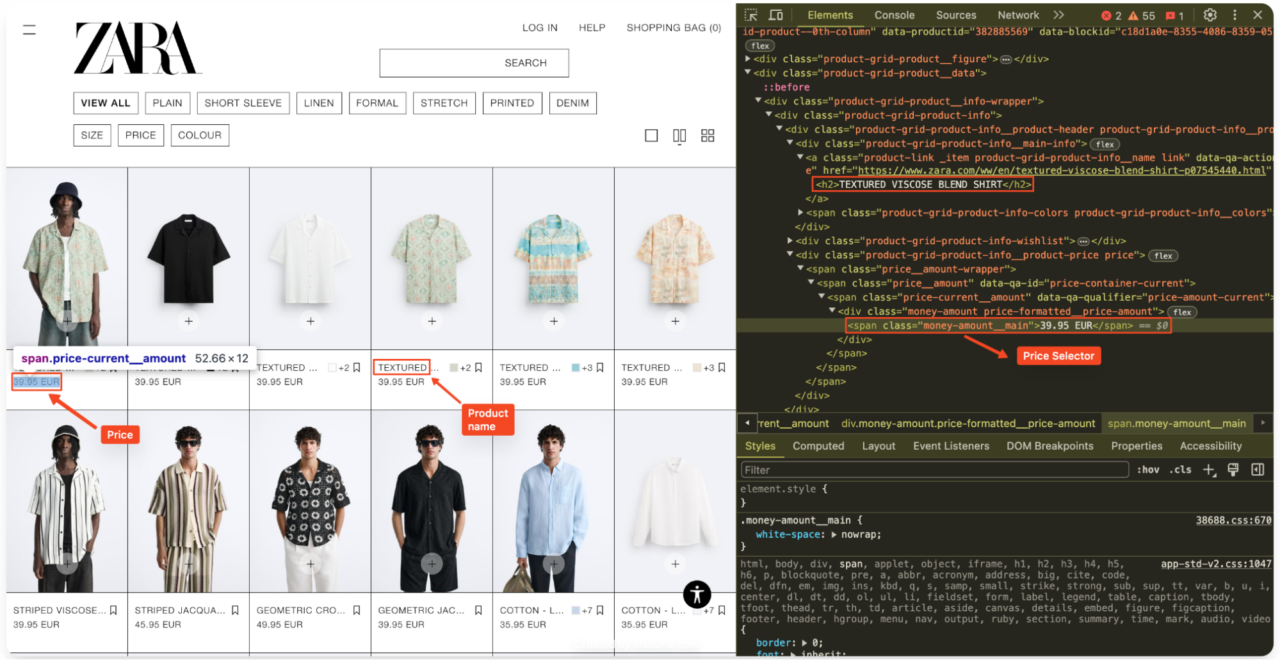
For Zara, the product information is generally enclosed within a
<div> tag with the class
product-grid-product-info. The product name is usually within an
<h2> tag, and the price is within a
<span> tag with the class money-amount__main.
Step 3: Creating the Spider
Now, I’ll navigate to the spiders directory within my project and
create a new file called zara_spider.py. This file will contain the logic for
scraping Zara’s website.
cd spiders
touch zara_spider.py
Step 4: Defining the ScraperAPI Method
I’ll use ScraperAPI to handle potential blocking and JavaScript rendering
issues. I will send my request through ScraperAPI’s server by appending my
query URL to the proxy URL provided by ScraperAPI using
payload and urlencode.
At the top of zara_spider.py, import the required libraries:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
Here’s the code for the ScraperAPI integration:
APIKEY = "YOUR_SCRAPERAPI_KEY"
def get_scraperapi_url(url):
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
This get_scraperapi_url() function takes a URL as input, adds my
ScraperAPI key to it, and returns a modified URL. This modified URL routes our
requests through ScraperAPI, making detecting and blocking our scraping
activity harder for websites.
Important: Don’t forget to replace
“YOUR_SCRAPERAPI_KEY” with your actual API key from ScraperAPI.
Step 5: Writing the Main Spider Class
In Scrapy, I can create different classes, called spiders, to scrape specific pages or groups of sites. With ScraperAPI set up, I can start writing the main spider class. This class outlines how our scraper will interact with Zara’s website.
Here’s the code for our ZaraProductSpider class:
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = [
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
]
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
In this code, I defined a class called ZaraProductSpider, which
inherits properties from Scrapy’s base Spider class. This
inheritance is what makes our class a ‘Scrapy spider’.
Inside the class, name = "zara_products" defines the name of our
spider. We’ll use this name later to run the spider from our terminal. The
start_requests method defines the spider’s starting point by
specifying the URLs we want to scrape. In this case, I’m targeting the first
three pages of the men’s shirts section on Zara’s website.
The code then iterates through each URL in the urls list and uses
Scrapy’s Request object to fetch the HTML content of each page. The
callback=self.parse argument instructs Scrapy to call the
parse method (which we’ll define next) to handle the downloaded
content.
Step 6: Parsing the HTML Response
It’s time to define the parse method, which will process the HTML
content I downloaded from Zara.
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
The parse method receives the downloaded HTML content as a response object. I
then create a BeautifulSoup object named soup to parse this HTML
response.
The code then iterates through all the <div> elements with
the class product-grid-product-info, which I identified earlier
as containers for product information.
For each product, I extract the product’s name from the
<h2> tag and the price from the
<span> tag with the class money-amount__main.
I used get_text(strip=True) to remove extra spaces from the
extracted text. If a tag isn’t found, I set the corresponding value (product
name or price) to None.
Finally, I yield a dictionary containing the extracted product
name and price for each product. This allows Scrapy
to collect and process the data further, such as saving it to a file.
Step 7: Running the Spider
With my spider fully coded, I can run it using the command:
scrapy crawl zara_products
This command tells Scrapy to execute the zara_products spider. Scrapy will now send the requests to Zara’s website, process the downloaded HTML, extract the product data based on my defined logic, and output the data to the console.
Step 8: Saving the Price Data
While viewing the extracted data in the console is helpful for debugging, I prefer saving the data for later use. Scrapy simplifies this process with built-in support for exporting data to various formats, including CSV.
To save my extracted data to a CSV file, I’ll use the following command:
scrapy crawl zara_products -o zara_mens_prices.csv
This command executes the zara_products spider and saves the
extracted data to a file named zara_mens_prices.csv. The
-o option specifies that I want to output a file. It creates a
new file and inserts the scraped data into it.
Step 9: Full Code and Results.
Here’s the complete code for my spider:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scraperapi_url(url):
APIKEY = "YOUR_SCRAPERAPI_KEY"
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = [
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
]
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Important: Remember to replace
YOUR_SCRAPERAPI_KEY with your actual API key from Scraper API.
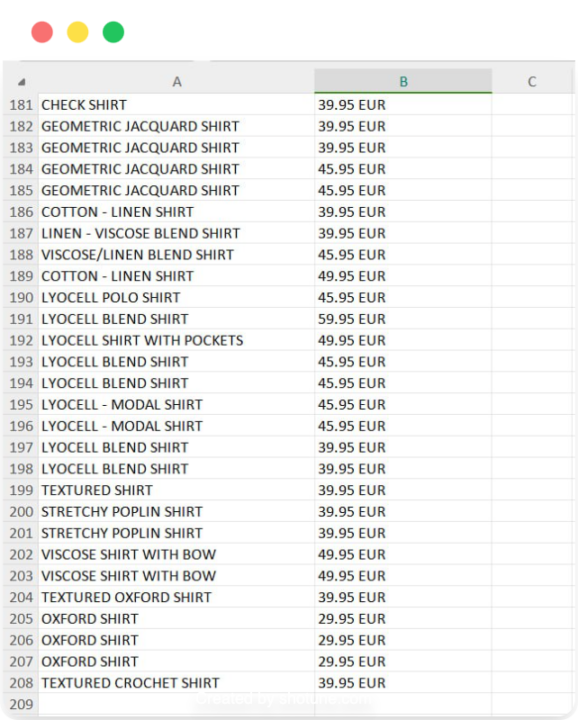
And there you have it! You now have a CSV file containing product names and prices from the first three pages of Zara’s men’s shirts section, ready for further analysis or use in other applications.
Scraping Prices with ScraperAPI SDEs
ScraperAPI’s Structured Data Endpoints (SDEs) simplify the process of scraping product prices by providing structured data in JSON format. Instead of dealing with intricate HTML parsing and website changes, SDEs provide structured data, often in a convenient JSON or CSV format, making data extraction faster and less prone to errors.
Note: Check SDE documentation.
Let’s explore how to use ScraperAPI SDEs to scrape product prices from major e-commerce platforms:
Amazon Product Prices
It is no small feat to bypass Amazon’s anti-bot mechanisms when scraping product data at scale. Some of the challenges you might encounter include IP blocking, CAPTCHAs, and frequent changes to their product pages.
Fortunately, ScraperAPI’s Amazon SDEs are designed to handle these challenges, providing clean product data, including those often sought-after prices.

Scraping product prices from Amazon using the Amazon search API is remarkably straightforward. You can gather structured data in JSON format by making a simple API request:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Sauvage Dior"
payload = {'api_key': APIKEY, 'query': QUERY, 'country': 'us'}
r = requests.get('https://api.scraperapi.com/structured/amazon/search', params=payload)
# Parse the response text to a JSON object
data = r.json()
with open('amazon_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in amazon_results.json")
In this code, we first define our API key and the search query. We then
construct the payload with the api_key, query, and,
optionally, country_code parameters.
Note: You can also set specific TLDs to get more localized data.
The request is sent to the ScraperAPI endpoint, and if successful, the response is parsed into a JSON object. This JSON object will contain all the product information, including product prices. Lastly, the data is saved in a file named amazon_results.json.
{
"results": [
{
"type": "search_product",
"position": 1,
"asin": "B014MTG78S",
"name": "Christian Dior Sauvage Eau de Toilette for Men, 2 Ounce",
"image": "https://m.media-amazon.com/images/I/4140FetAgkL.jpg",
"has_prime": true,
"is_best_seller": false,
"is_amazon_choice": false,
"is_limited_deal": false,
"purchase_history_message": "800+ bought in past month",
"stars": 4.6,
"total_reviews": 19210,
"url": "https://www.amazon.com/Sauvage-Christian-Dior-Toilette-Ounce/dp/B014MTG78S/ref=sr_1_1?dib=eyJ2IjoiMSJ9.Fx8LrOyO3CO4VY3zYWkqSe6-HzohovLm08Mkg8Nhgv3folygQwBLui6jDIIPKugSKh4IuQoglcYFl-hTDoa_asMO1TR0AmgUv4w_kLY2WzF8Hf3XuPzIOe97F9kk71M75FofVmcOnoN7U_XYoAw4fddsl9uF8aFAOxfIP0O4Q_GU-BJbRZ7bZrwKqJb_dFHYzNxp-OYwpQBcWStRkJnHiLPgqqG1H4Nh9y8mngo4tnE-5ZWlz3AfcCWueqdASDLKB0ec3OhGATmQ70-yJILtXRjJ6OBuuyChX7HNIEBzEcg.i29lFhcRatBkMJ6pkTgb33fotRSWWjCUhV87WGhB1Wo&dib_tag=se&keywords=Sauvage+Dior&qid=1718868400&sr=8-1",
"availability_quantity": 1,
"spec": {},
"price_string": "$86.86",
"price_symbol": "$",
"price": 86.86,
"original_price": {
"price_string": "$92.99",
"price_symbol": "$",
"price": 92.99
}
}, //TRUNCATED
}
You can customize your data gathering by using additional parameters in the
API request, such as specifying the country for the Amazon domain
(country), setting the output format
(output_format), and implementing pagination (page)
to retrieve results from multiple pages.
The Amazon search API documentation provides a complete list of available parameters and more advanced use cases.
Pro Tip
If you want to get only product prices, you can use the JSON keys to pick specific values. For this example, let’s get the name, price, currency, and URL for each product:
First, let’s create an empty list at the top of our file:
product_prices = []Next, we’ll store all organic product results (within the
resultskey) into anall_productsvariable:all_products = data['results']Now, we can iterate through each product and extract the specific information we’re interested in.
One thing, though. On the Amazon search result page, some products don’t have prices, so ScraperAPI won’t return the
pricekey. To avoid issues, let’s check if thepricekey is inside the product information before appending its value to our empty list.for product in all_products: product_name = product['name'] product_url = product['url'] #checking if the product has the price key if 'price' in product: product_price = product['price'] product_currency = product['price_symbol'] #appeding the product information to our list product_prices.append({ 'name': product_name, 'price': product_price, 'currency': product_currency, 'url': product_url }) else: product_prices.append({ 'name': product_name, 'price': 'not found', 'url': product_url })Using JSON key-value pairs makes it easy to get specific data points from the response. Now, all we need to do is to
dump()theproduct_priceslist into a JSON file as we did before:with open('amazon_results.json', 'w') as json_file: json.dump(product_prices, json_file, indent=4) print("Results have been stored in amazon_results.json")You can use a similar process for the other SDEs.
Resource: Learn how to scrape Amazon product data using Python and ScraperAPI.
Walmart Product Prices
Like Amazon, Walmart presents challenges for traditional scraping methods due to its bot detection measures and ever-changing website structure. ScraperAPI’s Walmart API bypasses these obstacles, directly delivering structured product data, including prices, to you.
Here’s a basic example demonstrating how to scrape product prices from Walmart:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Sauvage Dior"
payload = {'api_key': APIKEY, 'query': QUERY, 'page': '2'}
r = requests.get('https://api.scraperapi.com/structured/walmart/search', params=payload)
data = r.json()
# Write the JSON object to a file
with open('walmart_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in walmart_results.json")
In this code, we define our api_key and the
query and specify the page number for pagination.
The request is sent to the Walmart Search API endpoint, and upon success, the
response is parsed into a JSON object and saved to
walmart_results.json.
{
"items": [
{
"availability": "In stock",
"id": "52HDEPYCF0WO",
"image": "https://i5.walmartimages.com/seo/Dior-Sauvage-Eau-de-Parfum-300ml_3bb963cb-2769-4c61-b2b7-9bc5fc35e864.119f0ebb7fea31368d709ea899cbe13f.jpeg?odnHeight=180&odnWidth=180&odnBg=FFFFFF",
"sponsored": true,
"name": "Dior Sauvage Eau de Parfum 300ml",
"price": 245.95,
"price_currency": "$",
"rating": {
"average_rating": 0,
"number_of_reviews": 0
},
"seller": "Ultimate Beauty SLU",
"url": "https://www.walmart.com/ip/Dior-Sauvage-Eau-de-Parfum-300ml/2932396976"
}, //TRUNCATED
],
"meta": {
"page": 2,
"pages": 25
}
}
You can refine your data extraction using parameters like
output_format to specify CSV or JSON output. A comprehensive list
of parameters and their usage can be found in the
Walmart Search API
documentation.
Resource: Learn how to scrape Walmart product data using Python and ScraperAPI.
Google Shopping Product Prices
With its dynamic content loading and anti-scraping mechanisms, Google Shopping can be tricky to scrape effectively using traditional methods. The Google Shopping API from ScraperAPI greatly simplifies this process by delivering clean, structured product data, including prices.
Here’s a simple example demonstrating how to extract product data from Google Shopping:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Chop sticks"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'jp'}
r = requests.get('https://api.scraperapi.com/structured/google/shopping', params=payload)
# Parse the response text to a JSON object
data = r.json()
# Write the JSON object to a file
with open('google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in google_results.json")
Here, I define my API key and the search query. After constructing my payload, The request is sent to the Google Shopping SDE.
Upon a successful response, the data is parsed into a JSON object and saved to google_results.json.
{
"search_information": {},
"ads": [],
"shopping_results": [
{
"position": 1,
"docid": "9651870852817516154",
"link": "https://www.google.co.jp/url?url=https://www.amazon.co.jp/GLAMFIELDS-Fiberglass-Chopsticks-Reusable-Dishwasher/dp/B08346GNS5%3Fsource%3Dps-sl-shoppingads-lpcontext%26ref_%3Dfplfs%26ref_%3Dfplfs%26psc%3D1%26smid%3DA1IXFONC0DTBL5&rct=j&q=&esrc=s&opi=95576897&sa=U&ved=0ahUKEwjjwoXJ2-mGAxXonYQIHebrDoAQ2SkIxQg&usg=AOvVaw0dYnZyMtnWgRJvjmYNuAx0",
"title": "GLAMFIELDS 10 Pairs Fiberglass Chopsticks, Reusable Japanese Chinese Chop Sticks ...",
"source": "Amazon\u516c\u5f0f\u30b5\u30a4\u30c8",
"price": "\uffe52,240",
"extracted_price": 22.4,
"thumbnail": "https://encrypted-tbn0.gstatic.com/shopping?q=tbn:ANd9GcTMdg46wyytkT3p9bvEKBZwtpdyRI97OGHmJBLQIyDjX1JC6Hm3WPEZUrGzJLqnB3Y3tKA6cFbq0gYUJF0XcBlh77VPy7xWVY79HyTtujQdohmytfoKZWnm&usqp=CAE",
"delivery_options": "\u9001\u6599 \uffe5642",
"delivery_options_extracted_price": 6.42
}, //TRUNCATED
}
For a detailed explanation of all available parameters, check out the Google Shopping API documentation.
Automate Price Scraping with DataPipeline
ScraperAPI offers a hosted scraper designed to build entire scraping projects with a visual interface called DataPipeline. With it, you can automate the whole scraping process without writing or maintaining any code.
For this example, let’s automate an Amazon product scraper using DataPipeline.
Create a New Amazon Project
Log in to your ScraperAPI account to access your dashboard and click on the Create a new DataPipeline project option at the top of the page.
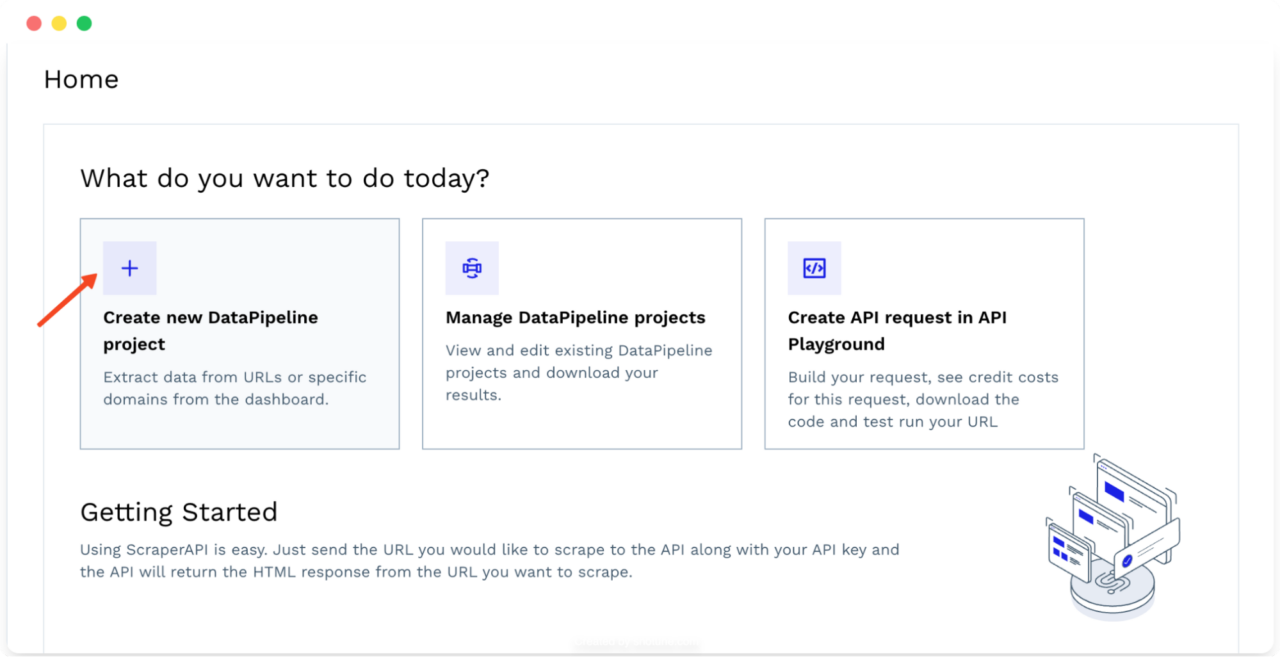
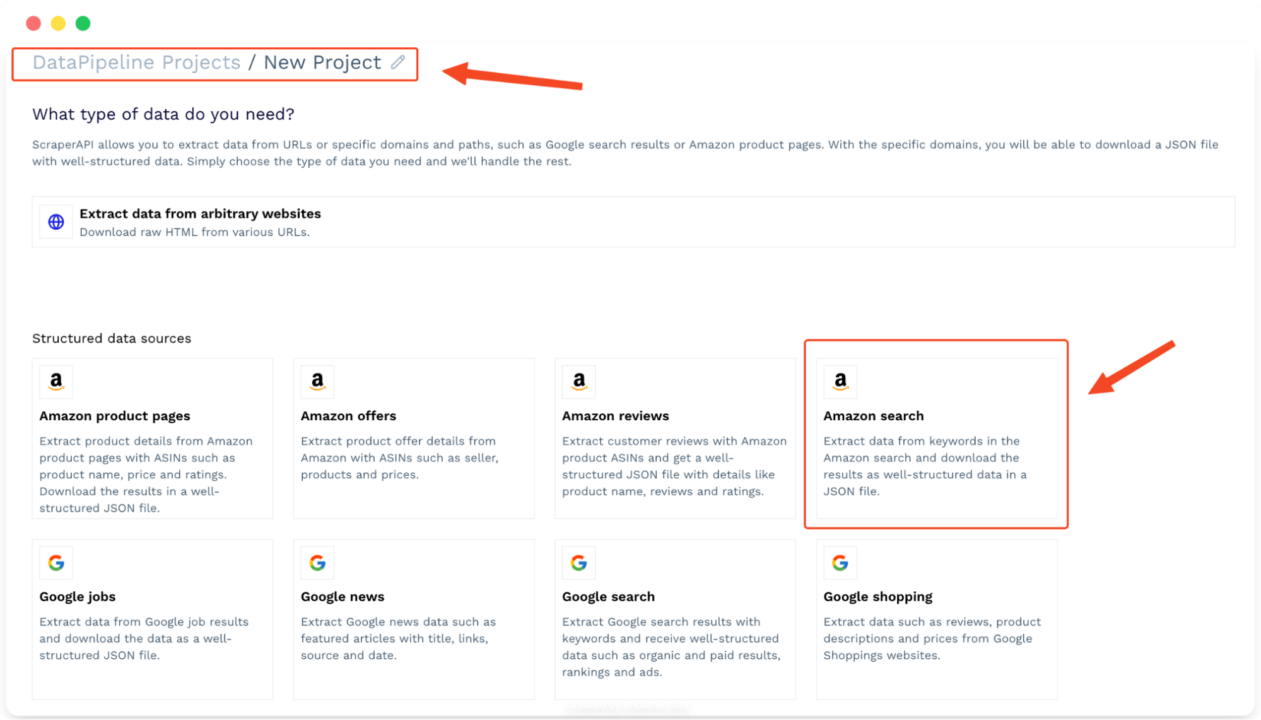
It’ll open a new window where you can edit the name of your project and choose between several ready-to-use templates. Click on Amazon Search to get started.
Set Up Your Scraping Project
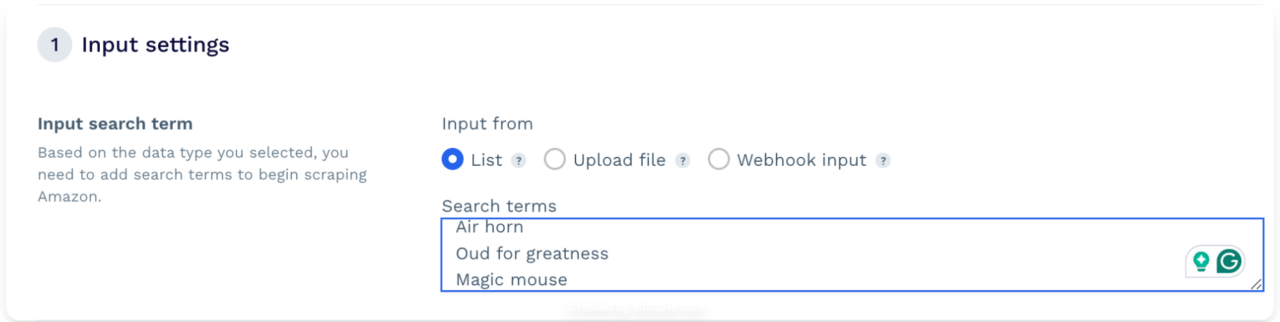
The first step is to provide a list of search terms for which to scrape data. You can scrape or monitor up to 10,000 search terms per project.
You can enter the terms directly into the text box (one per line), upload a text file containing the terms, or use a Webhook link for a more dynamic list of terms.
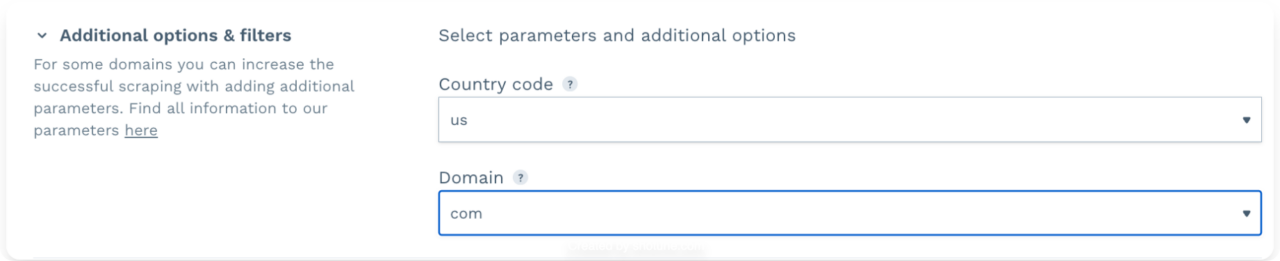
You can customize your project by enabling different parameters to make the returned data more accurate and fit your needs.
Next, choose your preferred data delivery option, including downloading or sending the data via Webhook and receiving it in JSON or CSV format.

Note: You can download the results regardless of whether you choose Webhook as a delivery option.
Lastly, specify the scraping frequency (it can be a one-time scraping job or set custom intervals) and your notification preferences.
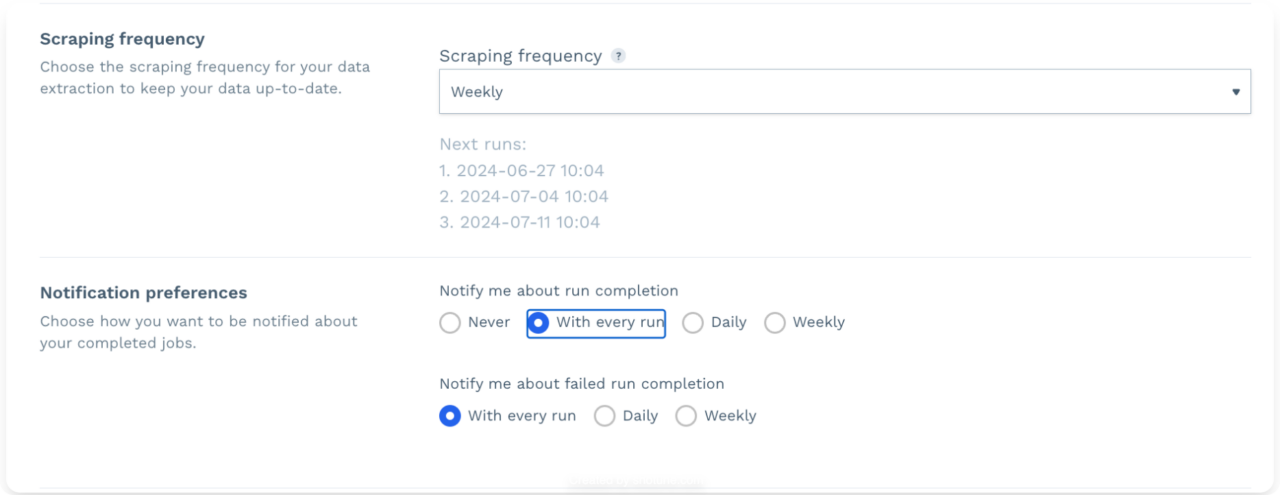
Run Your Amazon Scraper
Once everything is set up, click Review & Start Scraping at the bottom of the page.
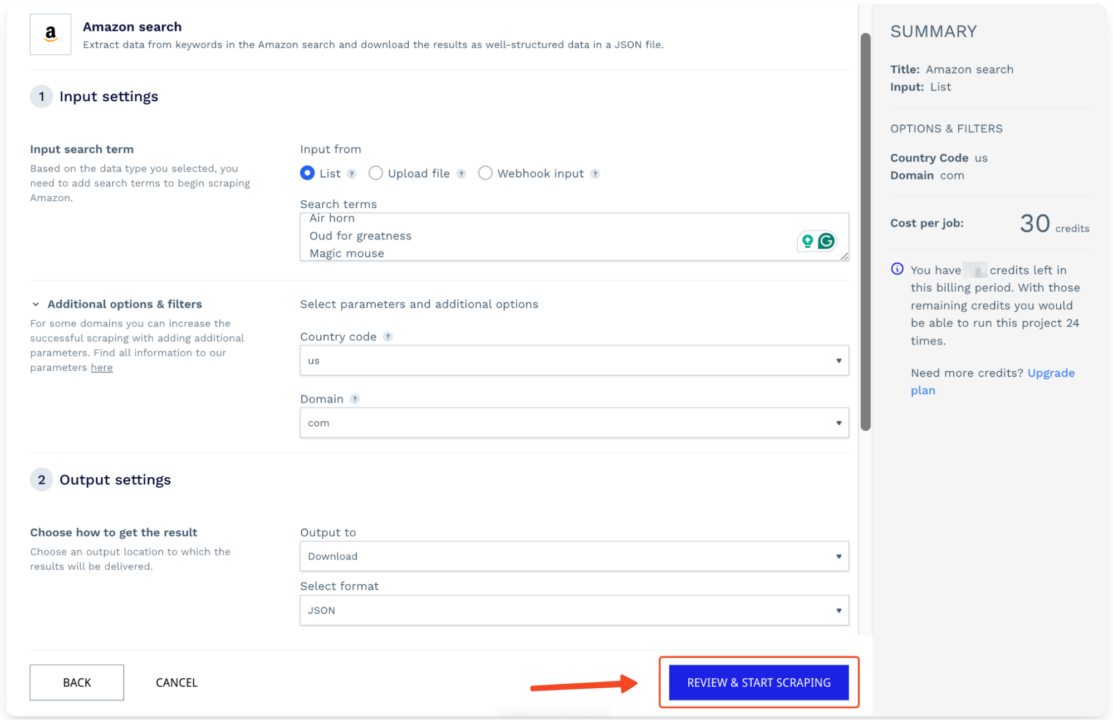
This will also show you the estimated number of credits used per run, ensuring transparency in pricing.
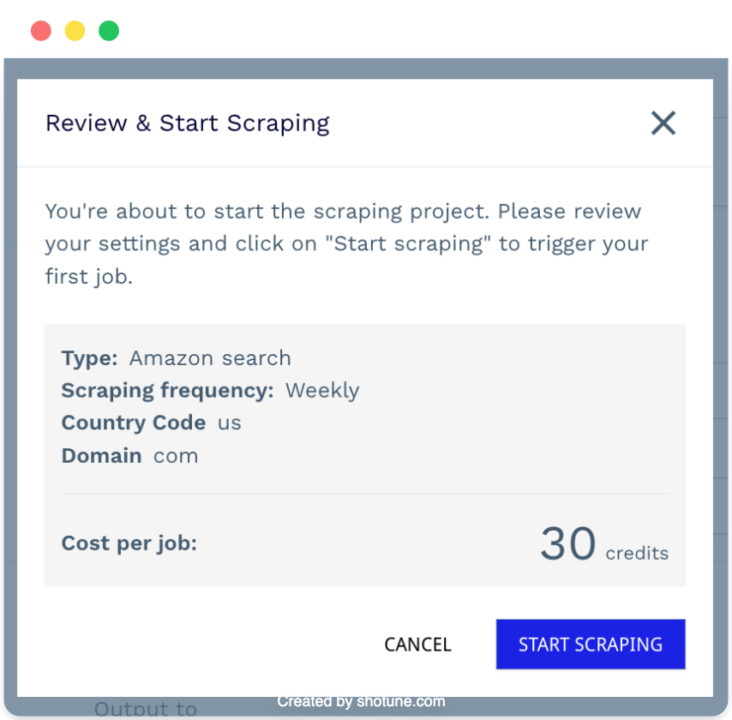
After clicking Start Scraping, the tool will take you to the project’s dashboard, where you can monitor performance, cancel running jobs, and review your configurations.
You’ll also be able to download the results after every run, so as more jobs are completed, you can always come back and download the data from previous ones.
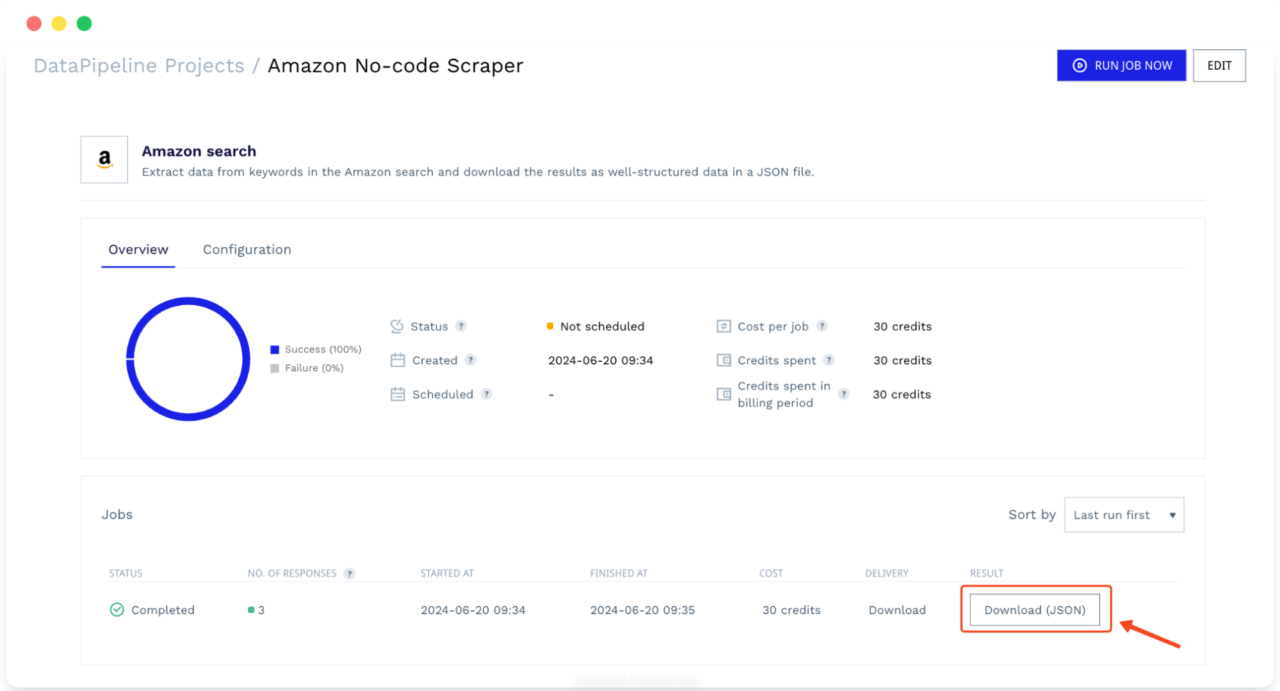
Note: Check DataPipeline’s documentation to learn the full features of the tool
That’s it. You are now ready to scrape thousands of product prices using DataPipelines!
Wrapping Up
Throughout this article, you’ve learned how to scrape product prices from various e-commerce sites using ScraperAPI.
- We started by setting up Scrapy and creating a spider to scrape data from Zara
- Then, we explored how to use ScraperAPI’s Structured Data Endpoints (SDEs) to simplify scraping product prices from Amazon and Walmart
- Finally, we looked at how to automate the entire scraping process with DataPipelines, allowing you to efficiently manage and extract data without writing extensive code.
Ready to try it yourself? Discover our scraping solutions to find the right tool for your project, or follow one of our advanced tutorials to try ScraperAPI’s features:
- How to Scrape Walmart Reviews
- Amazon Competitive Analysis: Step-by-Step Guide
- How to Scrape Amazon ASINs at Scale
Keep exploring, and happy scraping!




