



In this article, we’ll show you how to scrape Walmart product reviews and build a historical dataset to help you make better marketing and business decisions.
To make our scraper scalable, allowing us to handle millions of requests a month, we’ll use ScraperAPI’s Async Scraper to automate:
- Concurrency management
- Retries management
- Ati-bot detection bypassing
Scraping Walmart Product Reviews in Node.js
Building a Web scraper for Walmart product reviews at scale requires two scripts:
- The first will build the list of product reviews pages and send each URL to the async scraper service
- Then, the webhook server that will receive the response from the Async API will extract the content from the raw HTML and save it in a JSON file
Important Update
Now you can scrape Walmart product reviews using ScraperAPI’s Walmart Products endpoint to turn product pages into easy-to-navigate JSON data.
https://api.scraperapi.com/structured/walmart/productJust send your requests to the endpoint alongside your API key and product ID within a
payload. Then, you can target the"reviews"key to access the top reviews for your target product."reviews": [ { "title": "Walmart pickup order", "text": "Make sure they scan your item right I received my order thru the delivery but when I finished activating my phone it still says SOS mode only so I'll be making a trip to Walmart sucks too have a locked phone after spending the money for it", "author": "TrustedCusto", "date_published": "2/8/2024", "rating": 5 }, { "title": "Very satisfied.", "text": "I'm very satisfied with my purchase and product. Thank you. Definitely will recommend when I get the chance. Keep up the good work. I appreciate you.", "author": "BLVCKSNVCK", "date_published": "10/7/2023", "rating": 5 }, [More Data]See the full Walmart Product endpoint sample response.
Explore Walmart Product SDE
To get started, let’s take a look at how product reviews are organized on the site.
Understanding Walmart Product Reviews Structure
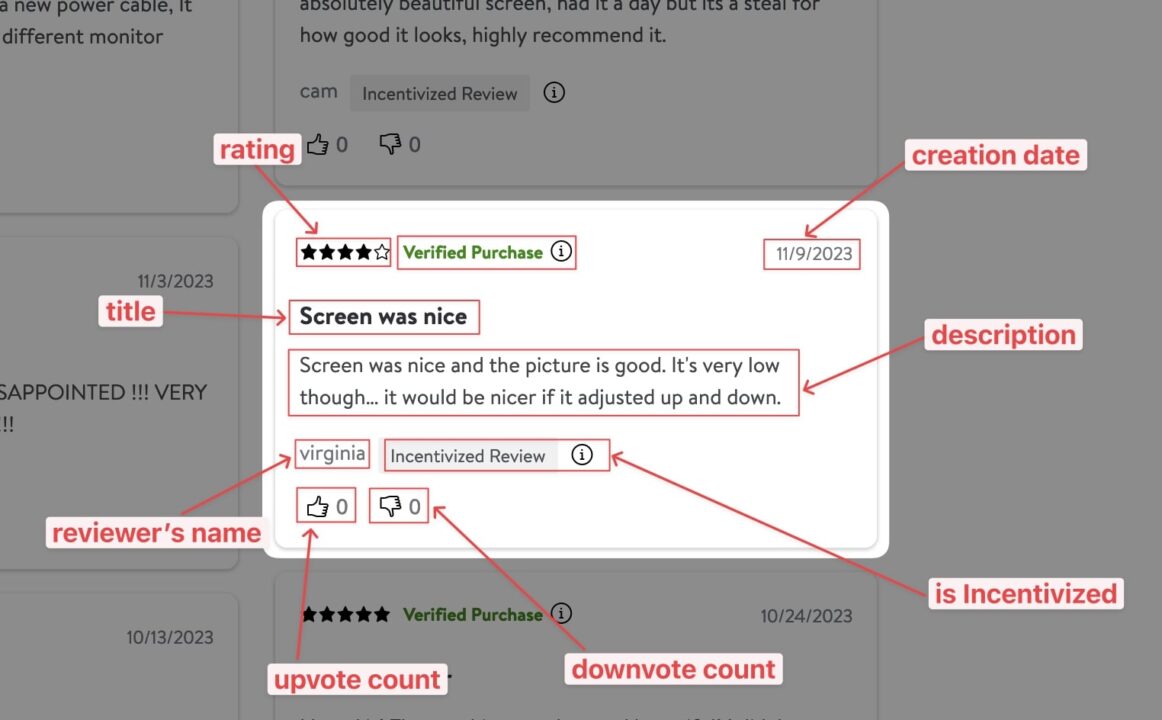
By examining Walmart’s product reviews page, we can identify the following elements we can extract:
The picture below describes the system architecture of the scraper we’ll need to build to get this data efficiently and at scale.
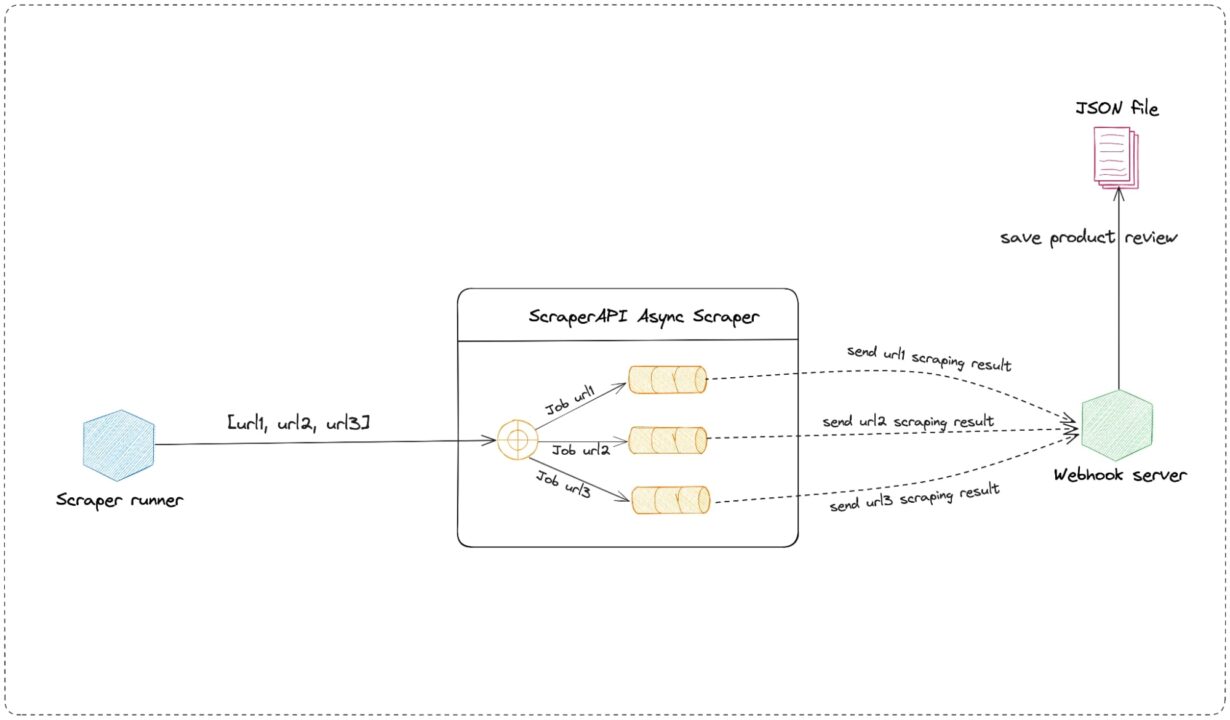
Note: To make our system more efficient, storing reviews in a JSON file should not be done synchronously but instead through a message broker, which will prevent the Webhook server from being overwhelmed by the number of requests to proceed synchronously.
For the sake of simplicity, we will use JSON, but feel free to upgrade the implementation to take this caveat into account.
Prerequisites
You must have these tools installed on your computer to follow this tutorial.
- Node.js 18+ and NPM – Download link
- Knowledge of JavaScript and Node.js API
- A ScraperAPI account – Create an account and get 5,000 free API credits to get started
Step 1: Set up the project
Let’s create the folder that will hold our source code and initialize a new Node.js project:
</p>
mkdir walmart-async-scraper
cd walmart-async-scraper
npm init -y
<p>The above last command will create a package.json file in the folder.
Step 2: Build the asynchronous scraper
The picture below shows a Walmart product review page:
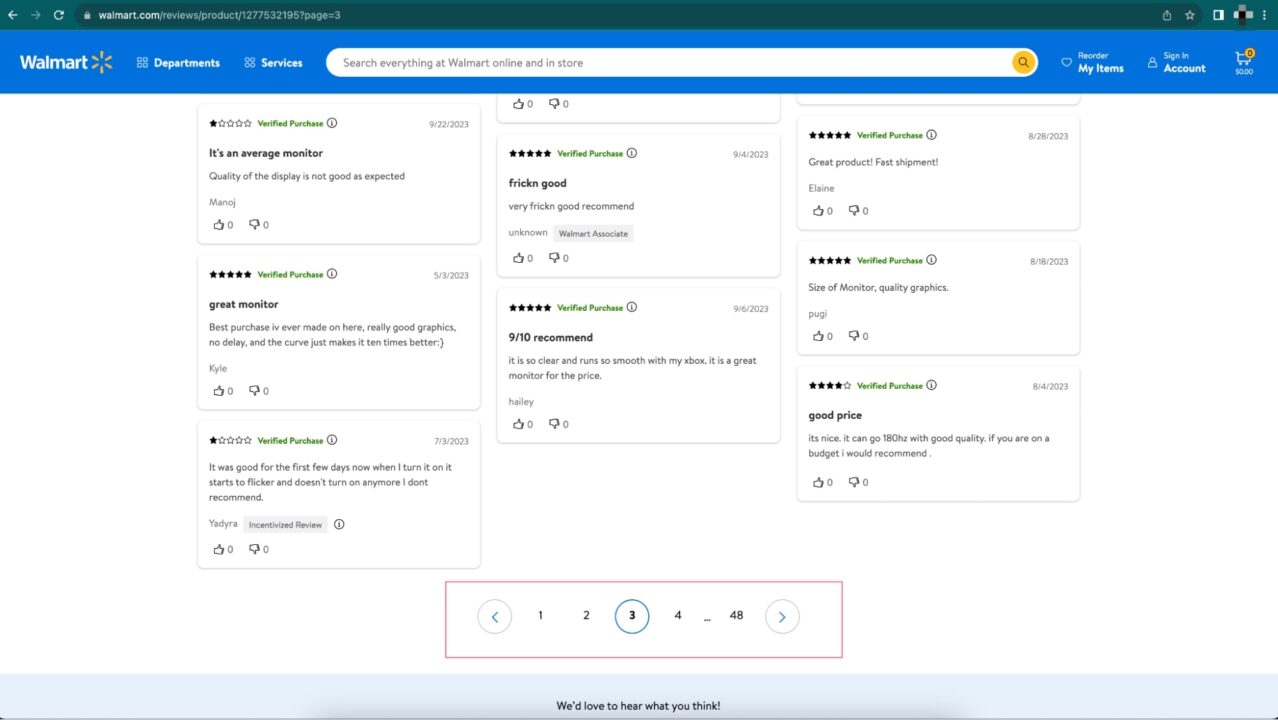
The interesting part is the pagination section, where the reviews go from page 1 to page 48, and we are currently on page 3.
The URL looks like this: https://www.walmart.com/reviews/product/1277532195?page=3
By analogy, we must generate 48 URLs where the page number differs.
This list of URLs will be sent to the Async Scraper to perform the Web scraping asynchronously.
Behind the scenes, it will also handle most of the challenges related to web scraping at scale, such as IP rotation, CAPTCHA solving, rate limiting, etc.
We will send 48 URLs, but the Async Scraper service can scrap millions of URLs asynchronously.
To send the request through ScraperAPI’s servers, we will use an HTTP client for Node.js, such as Axios, so let’s install it:
</p>
npm install axios
<p>Create the file run-scraper.js and add the code below:
</p>
<pre class="wp-block-syntaxhighlighter-code"> const axios = require('axios');
const apiKey = '<api_key>'; // <-- Enter your API_Key here
const apiUrl = 'https://async.scraperapi.com/batchjobs';
const callbackUrl = '<webhook_url>'; // <-- enter your webhook URL here const runScraper = () => {
const PAGE_URL = 'https://www.walmart.com/reviews/product/1277532195'
const PAGE_NUMBER = 5;
const pageURLs = [];
for (let i = 1; i <= PAGE_NUMBER; i++) { pageURLs.push(`${PAGE_URL}?page=${i}`); } const requestData = { apiKey: apiKey, urls: pageURLs, callback: { type: 'webhook', url: callbackUrl, }, }; axios.post(apiUrl, requestData) .then(response => {
console.log(response.data);
})
.catch(error => {
console.error(error);
});
};
void runScraper();
</webhook_url></api_key></pre>
<p>The variable callbackUrl stores the webhook’s URL to send the response to. We limited the page number to 5 for now; we will update it later to 48 for the final demo.
I used the online webhook service webhook.site to generate one.
Note: Remember to add your API key. You can find it in your ScraperAPI dashboard.
Run the command node run-scraper.js to launch the service. You will get the following response.
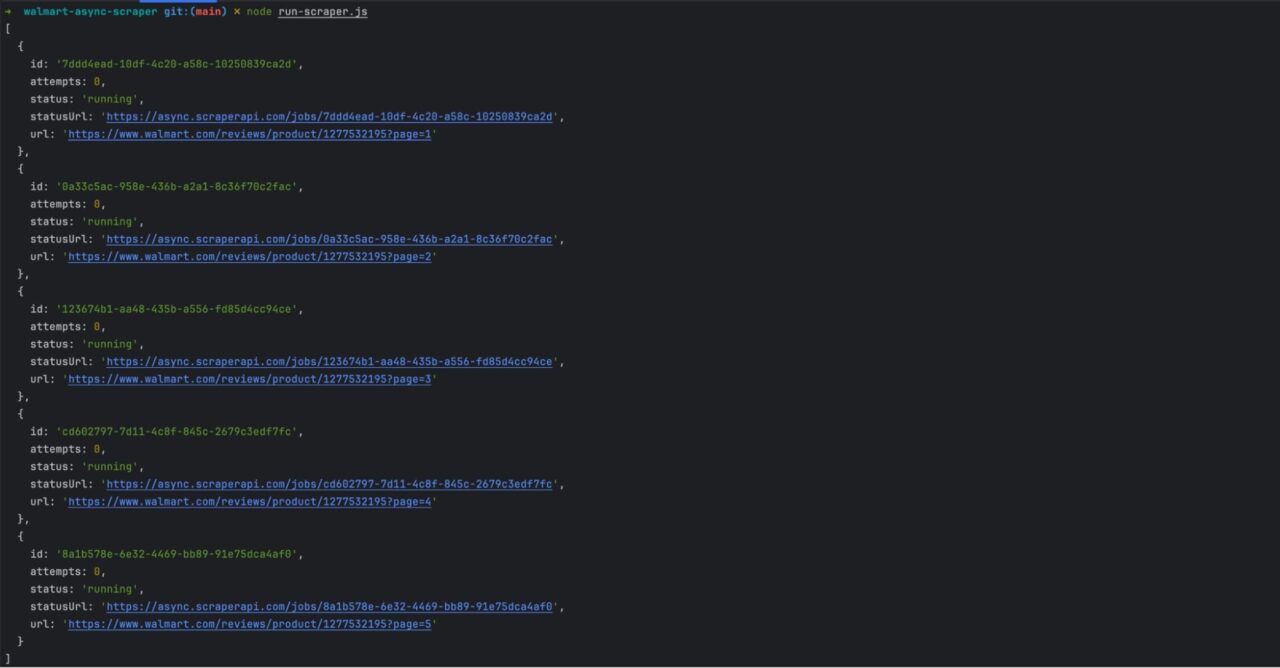
The API returns an array of five jobs, one job per product review page URL.
Wait for a few seconds and browse your online webhook page; you can see you received five API calls.
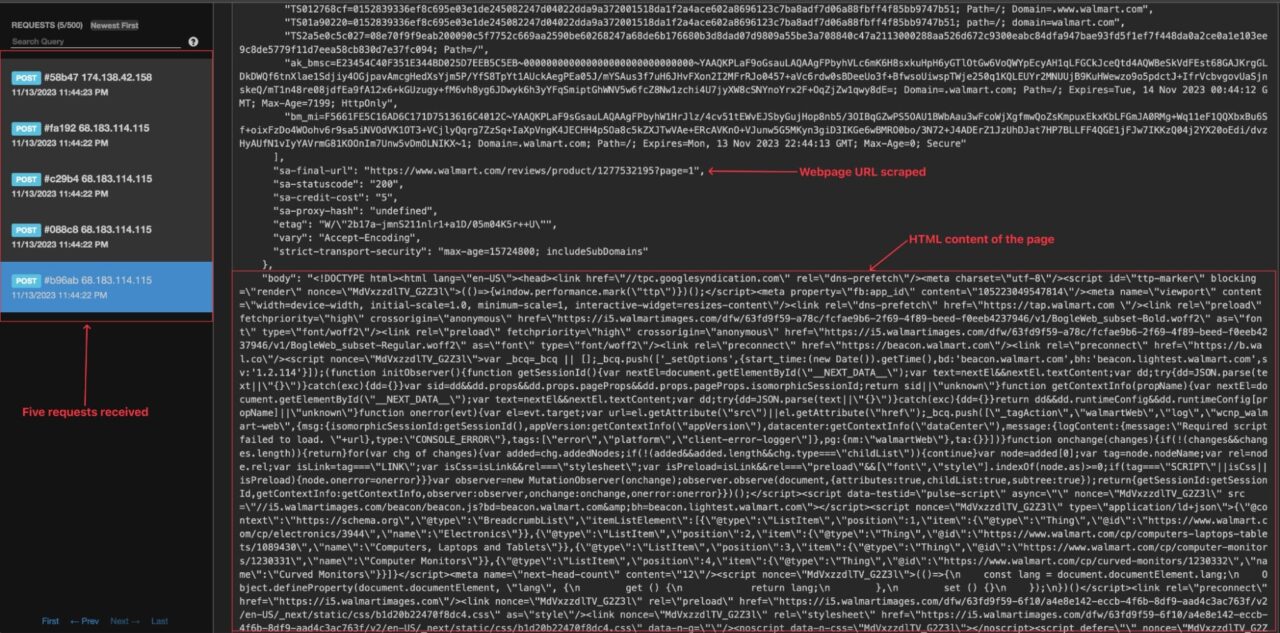
Now that we can see the webhook is triggered, let’s build our webhook server to receive the job result and proceed to extract and store the data in a JSON file.
Step 3: Write a Utilities Function to Manipulate the JSON File
We need three utility methods:
- Create the product reviews JSON file if it doesn’t exist
- Update the JSON file with new reviews
- Extract the product ID from the product review URL
Create a file utils.js and add the code below:
</p>
const fs = require("fs");
const path = require("path");
const extractProductIdFromURL = (url) => {
const parsedUrl = new URL(url);
const pathnameParts = parsedUrl.pathname.split("/");
if (pathnameParts.length === 0) {
return url;
}
return pathnameParts[pathnameParts.length - 1];
};
const createStorageFile = (filename) => {
const filePath = path.resolve(__dirname, filename);
if (fs.existsSync(filePath)) {
return;
}
fs.writeFileSync(filePath, JSON.stringify([], null, 2), { encoding: "utf-8" });
};
const saveDataInFile = (filename, items) => {
// TODO perform fields validation in data
const filePath = path.resolve(__dirname, filename);
const fileContent = fs.readFileSync(filePath, { encoding: "utf-8" });
const dataParsed = JSON.parse(fileContent);
const dataUpdated = dataParsed.concat(items);
fs.writeFileSync(filePath, JSON.stringify(dataUpdated, null, 2), { encoding: "utf-8" });
};
module.exports = {
createStorageFile,
extractProductIdFromURL,
saveDataInFile,
};
<p>Step 4: Identify the Information to Retrieve on the Walmart Product Review page
To extract the product’s review information, we must identify which DOM selector we can use to target its HTML tag. The picture below shows the location of each piece of information in the DOM.
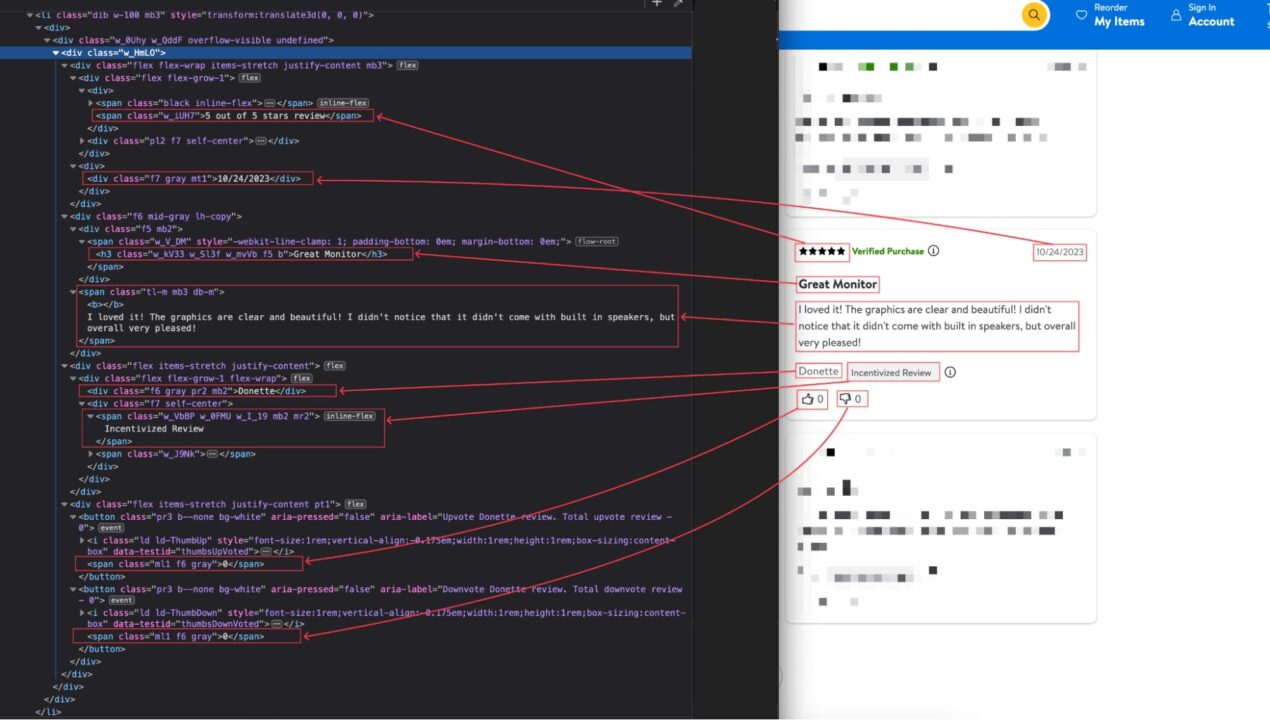
Here’s a table that enumerates the DOM selectors for each product information:
| Information | DOM selector |
| Review’s title | ul .w_HmLO div:nth-child(2) h3 |
| Review’s description | ul .w_HmLO div:nth-child(2) div + span |
| Name of the reviewer | ul .w_HmLO div:nth-child(3) > div > div:first-child |
| Date of creation | ul .w_HmLO div:first-child div:nth-child(2) > div.f7 |
| Rating | ul .w_HmLO span.w_iUH7 |
| Upvote count | ul .w_HmLO div:last-child button:first-child span |
| Downvote count | ul .w_HmLO div:last-child button:last-child span |
| Incensitized review | ul .w_HmLO div:nth-child(3) > div > div:first-child + div |
To extract the information above, we’ll use Cheerio, which allows us to parse the raw HTML and traverse the DOM using CSS selectors. Let’s install it:
</p>
npm install cheerio
<p>Step 5: Build the Webhook Server
This application runs a web server, exposing the endpoint that the Async Scraper will trigger. To set up the Node.js Web server, we will use Express, so let’s install it:
</p>
npm install express
<p>Create a file webhook-server.js and add the code below:
</p>
const crypto = require('crypto');
const cheerio = require('cheerio');
const express = require('express');
const { createStorageFile, extractProductIdFromURL, saveDataInFile } = require('./utils');
const PORT = 5001;
const STORAGE_FILENAME = 'products-reviews.json';
const app = express();
app.use(express.urlencoded({ extended: true }));
app.use(express.json({ limit: "10mb", extended: true }));
app.post('/product-review', async (req, res) => {
console.log('New request received!', req.body.id);
if (req.body.response?.body) {
console.log("Extract review information!");
const $ = cheerio.load(req.body.response.body);
const productId = extractProductIdFromURL(req.body.url);
const currentDate = new Date();
const reviewsList = [];
$("ul .w_HmLO").each((_, el) => {
const rating = $(el).find('span.w_iUH7').text();
const creationDate = $(el).find('div:first-child div:nth-child(2) > div.f7').text();
const title = $(el).find('div:nth-child(2) h3').text();
const description = $(el).find('div:nth-child(2) div + span').text();
const reviewer = $(el).find('div:nth-child(3) > div > div:first-child').text();
const incentivizedReview = $(el).find('div:nth-child(3) > div > div:first-child + div').text();
const upVoteCount = $(el).find('div:last-child button:first-child span').text();
const downVoteCount = $(el).find('div:last-child button:last-child span').text();
const review = {
id: crypto.randomUUID(),
productId,
title: title.length > 0 ? title : null,
description,
rating: +rating.replace(' out of 5 stars review', ''),
reviewer,
upVoteCount: parseInt(upVoteCount.length > 0 ? upVoteCount : 0),
downVoteCount: parseInt(downVoteCount.length > 0 ? downVoteCount : 0),
isIncentivized: incentivizedReview.toLowerCase() === "incentivized review",
creationDate,
date: `${currentDate.getMonth() + 1}/${currentDate.getDate()}/${currentDate.getFullYear()}`
};
reviewsList.push(review);
});
saveDataInFile(STORAGE_FILENAME, reviewsList);
console.log(`${reviewsList.length} review(s) added in the database successfully!`);
return res.json({ data: reviewsList });
}
return res.json({ data: {} });
});
app.listen(PORT, async () => {
createStorageFile(STORAGE_FILENAME);
console.log(`Application started on URL http://localhost:${PORT} 🎉`);
});
<p>At the application launch, an empty JSON file is created if it doesn’t exist.
When the server receives a POST request on the route /product-review, this is what happens:
- Load the HTML content of the page scraped with Cheerio
- For each product review, the information is extracted from the HTML content and added to an array.
- Once all the reviews are extracted, we save the data in the JSON file by calling the function
saveDataInFile()
Step 6: Test the Implementation
Launch the Webhook server with the command below:
</p>
node webhook-server.js
<p>The application will start on port 5001.
To make it accessible through the internet so that the Async Scraper can call it, we will use a tunneling service like Ngrok.
Run the command below to install Ngrok and create a tunnel to port 5001
</p>
npm install -g ngrok
ngrok http 5001
<p>- Copy the Ngrok URL
- Open the file run-scraper.js
- Update the variable
callbackUrl - Lastly, append the route
/product-review
Once that’s done, run the command below to start the product review scraper:
</p>
node run-scraper.js
<p>Wait for a few seconds and open the JSON file generated; you will see one hundred lines representing the first hundred reviews scraped on the product.
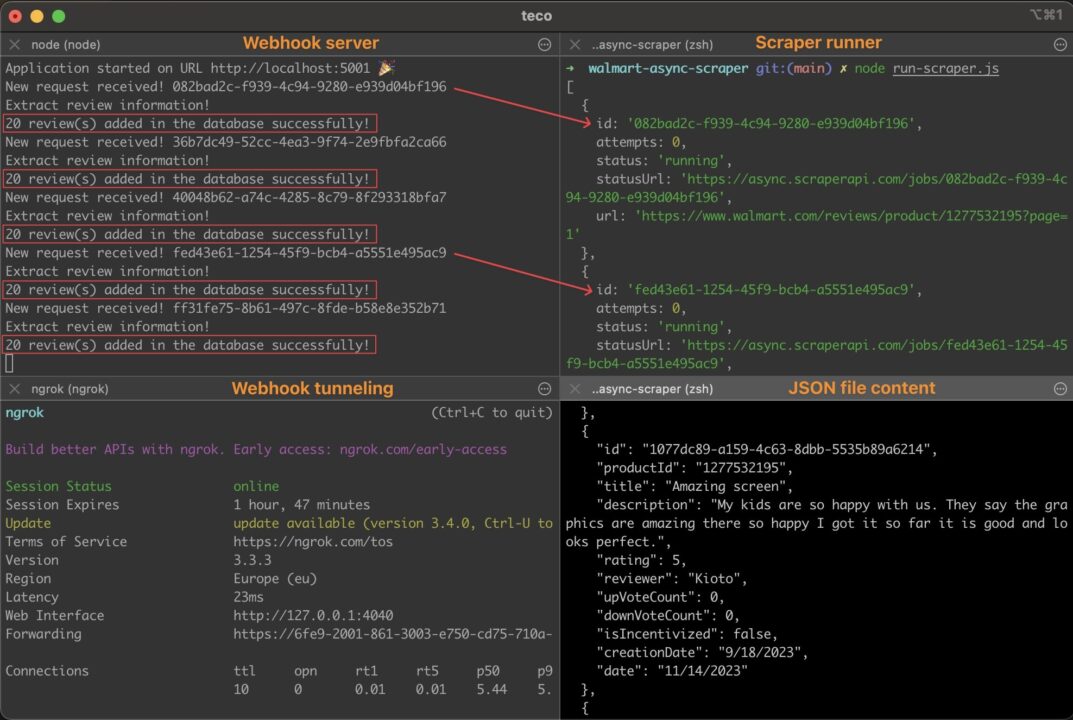
Note: The function saveDataInFile() is not concurrency-prone at scale, and handling it in this tutorial wasn’t relevant. Remember to rewrite this function to avoid inconsistent data in the JSON file. As suggested earlier, using a message broker is a good way to improve this implementation.
🎉 Congratulations, you just built your first review scraper!
Wrapping Up
To summarize, here are the steps to build a Walmart product reviews scraper:
- Preparing a list of URLs to scrape and store them into an array
- Send the request to the Async Scraper service
- Create a Webhook server exposing a route to be triggered by the async service
- Store all the product reviews scraped in a JSON file
The information stored in the JSON file can be used in Machine learning to perform sentiment analysis and NLP, helping you understand what your target audience likes or dislike from your competitors (and your) products.
To learn more about the Async Scraper, check out ScraperAPI’s documentation for Node.js. For easy access, here’s this project’s GitHub repository.
Until next time, happy scraping!





