



In this tutorial, we’ll show you how to build a web scraper using Puppeteer and ScraperAPI’s standard API to help scale our scraper without getting blocked.
TL;DR: Full Target.com Scraper
For those in a hurry, here’s the complete script we’ll build in this tutorial:
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const Excel = require("exceljs");
const path = require("path");
const TARGET_DOT_COM_PAGE_URL = 'https://www.target.com/s?searchTerm=headphones&tref=typeahead%7Cterm%7Cheadphones%7C%7C%7Chistory';
const EXPORT_FILENAME = 'products.xlsx';
// ScraperAPI proxy configuration
PROXY_USERNAME = 'scraperapi';
PROXY_PASSWORD = ''; // <-- enter your API_Key here
PROXY_SERVER = 'proxy-server.scraperapi.com';
PROXY_SERVER_PORT = '8001';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = [
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
];
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+(\.\d+)?)/;
const reviewCountRegex = /(\d+) ratings/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch[0]) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch[1]) : null;
return { rating, reviewCount };
};
const webScraper = async () => {
const browser = await puppeteer.launch({
ignoreHTTPSErrors: true,
args: [
`--proxy-server=http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`
]
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto(TARGET_DOT_COM_PAGE_URL, { timeout: 60000});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(3000);
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
const $ = cheerio.load(html);
const productList = [];
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span[data-test='current-price'] span").text();
const regularPrice = $(el).find("span[data-test='comparison-price'] span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
await exportProductsInExcelFile(productList);
console.log('The products has been successfully exported in the Excel file!');
};
void webScraper();
Want to understand each line of code of this web scraper? Let’s build it from scratch!
Scraping Target.com Product Data
As a use case for scraping Target.com products, we will write a web scraper in Node.js that finds Headphones and extracts the following information for each product:
- Description
- Price
- Average rating
- Total reviews
- Delivery estimation
- Product link
The web scraper will export the data extracted in an Excel file for further usage or analysis.
Prerequisites
You must have these tools installed on your computer to follow this tutorial:
- Node.js 18+ and NPM
- Basic knowledge of JavaScript and Node.js API
- A ScraperAPI account; sign up and get 5,000 free API credits to get started
Step 1: Set Up the Project
Let’s create a folder containing the source code of the Target.com scraper
mkdir target-dot-com-scraper
Enter the folder and initialize a new Node.js project
cd target-dot-com-scraper
npm init -y
The second command above will create a package.json file in the folder.
Next, create a file index.js in which we will write our scraper; keep it empty for now.
touch index.js
Step 2: Install the Dependencies
To build the Target.com web scraper, we need these three Node.js packages:
- Puppeteer – to load the website, perform product searches, scroll the page to load more results, and download the HTML content.
- Cheerio – to extract the information from the HTML downloaded from the Axios request.
- ExcelJS – to write the extracted data in an Excel workbook.
Run the command below to install these packages:
npm install puppeteer cheerio exceljs
Step 3: Identify the DOM Selectors to Target
Navigate to https://www.target.com; type “headphones” in the search bar and press enter.
When the search result appears, inspect the page to display the HTML structure and identify the DOM selector associated with the HTML tag wrapping the information we want to extract.
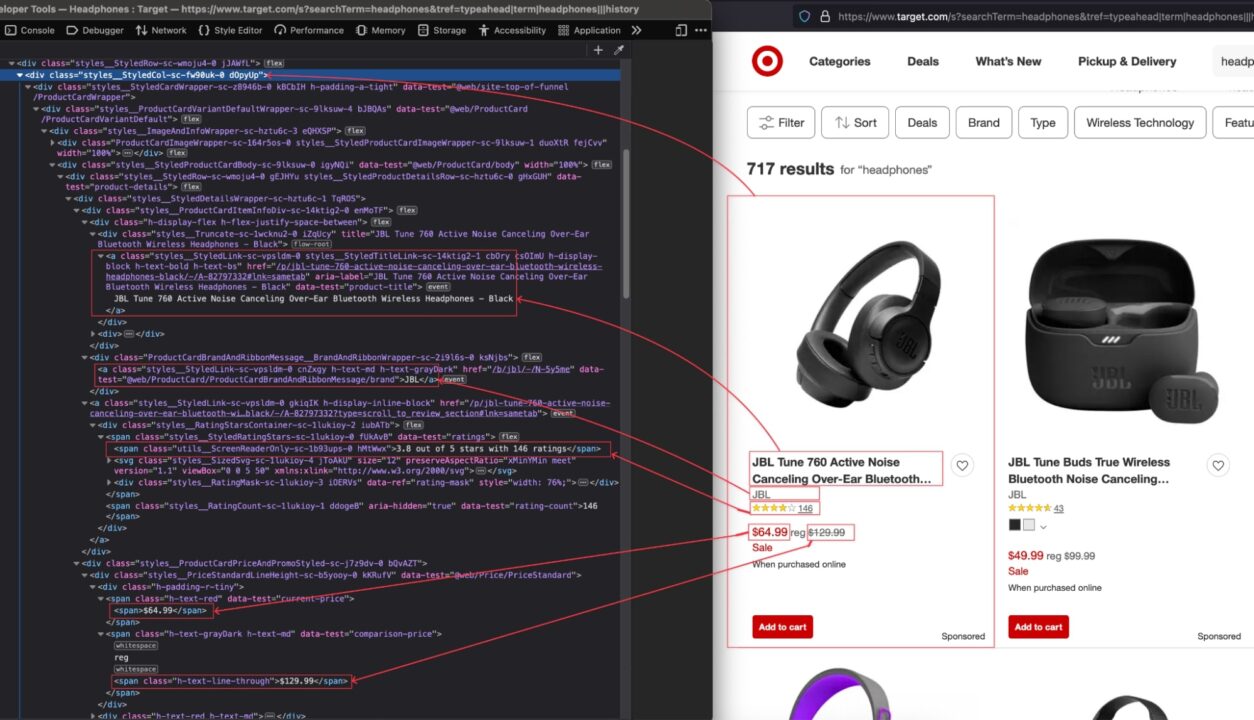
From the above picture, here are all the DOM selectors the web scraper will target to extract the information:
| Information | DOM selector |
| Product’s Title | .d0pyUp a.csOImU |
| Brand | .d0pyUp a.cnZxgy |
| Current price | .d0pyUp “span[data-test=’current-price’] span” |
| Regular price | .d0pyUp “span[data-test=comparison-price’] span” |
| Rating and reviews | .d0pyUp .hMtWwx |
| Target.com’s link | .d0pyUp a.csOImU |
Be careful when writing the selector because a misspelling will prevent the script from retrieving the correct value.
Step 4: Scrape Target.com’s Product Page
To retrieve the URL to scrape, copy the URL in your browse address bar; this is the URL for the search “headphones”.
Open the index.js file and add the code below:
const puppeteer = require("puppeteer");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const webScraper = async () => {
const browser = await puppeteer.launch({
headless: false,
args: ["--disabled-setuid-sandbox", "--no-sandbox"],
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@36.6092093,-129.3569836,6z/data=!3m1!4b1" , {
waitUntil: 'domcontentloaded',
timeout: 60000
});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(5000);
};
void webScraper();
This code above does the following:
- Create a browser instance with the headless mode deactivated; it is helpful when building your scraper to view the interaction on the page and have a feedback loop; we will deactivate it when the scraper is ready for production.
- Define the request
User-Agentso Target.com does not treat us as a bot but as a real browser instead; then navigate to the Web page. - In most European countries, a page to ask for consent will be displayed before being redirected to the URL; we click the button to reject everything and wait three seconds for the web page to load completely.
Step 5: Implement Page Scroll to Load All the Products
When the page loads, only four products are displayed; you must scroll until the page’s bottom to load more products. We must implement this below to retrieve all products on the page instead of the first four.
In the index.js file, add the code below right after the snippet that waits for the page to load completely:
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
The code above performs the scroll until the bottom page; once the bottom page is reached, download the HTML content of the page and close the browser instance.
Step 6: Extract Information from the HTML
Now that we have the HTML of the page, we must parse it with Cheerio to navigate it and extract all the information we want.
Cheerio provides functions to load HTML text and then navigate through the structure to extract information using the DOM selectors.
The code below goes through each element, extracts the information, and returns an array containing all the products.
const cheerio = require("cheerio")
// Puppeteer scraping code here
const $ = cheerio.load(html);
const productList = [];
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span[data-test='current-price'] span").text();
const regularPrice = $(el).find("span[data-test='comparison-price'] span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
console.log(productList);
Step 7: Store the Scraped Data in an Excel File
Storing the extracted data in an Excel file is great for using the data for other usages, such as data analysis.
We will use the package ExcelJS we installed earlier to create a Workbook, map the product property to a column in the workbook, and finally create the file on the disk.
Let’s update the index.js file to add the code below:
// Existing imports here…
const path = require("path");
const EXPORT_FILENAME = 'products.xlsx';
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = [
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
];
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
// Existing code here
Step 8: Test the implementation
At this step, we have everything in place to run our Web scraper; here is the complete code of the file:
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const Excel = require("exceljs");
const path = require("path");
const TARGET_DOT_COM_PAGE_URL = 'https://www.target.com/s?searchTerm=headphones&tref=typeahead%7Cterm%7Cheadphones%7C%7C%7Chistory';
const EXPORT_FILENAME = 'products.xlsx';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const exportProductsInExcelFile = async (productsList) => {
const workbook = new Excel.Workbook();
const worksheet = workbook.addWorksheet('Headphones');
worksheet.columns = [
{ key: 'title', header: 'Title' },
{ key: 'brand', header: 'Brand' },
{ key: 'currentPrice', header: 'Current Price' },
{ key: 'regularPrice', header: 'Regular Price' },
{ key: 'averageRating', header: 'Average Rating' },
{ key: 'totalReviews', header: 'Total Reviews' },
{ key: 'link', header: 'Link' },
];
worksheet.getRow(1).font = {
bold: true,
size: 13,
};
productsList.forEach((product) => {
worksheet.addRow(product);
});
const exportFilePath = path.resolve(__dirname, EXPORT_FILENAME);
await workbook.xlsx.writeFile(exportFilePath);
};
const webScraper = async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto(TARGET_DOT_COM_PAGE_URL);
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(3000);
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve()
}
}, 100);
});
});
const html = await page.content();
await browser.close();
const $ = cheerio.load(html);
const productList = [];
$(".dOpyUp").each((_, el) => {
const link = $(el).find("a.csOImU").attr('href');
const title = $(el).find('a.csOImU').text();
const brand = $(el).find('a.cnZxgy').text();
const currentPrice = $(el).find("span[data-test='current-price'] span").text();
const regularPrice = $(el).find("span[data-test='comparison-price'] span").text();
const reviews = $(el).find(".hMtWwx").text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
title,
brand,
currentPrice,
regularPrice,
averageRating: rating,
totalReviews: reviewCount,
link,
});
});
console.log(`Number of items extracted:`, productList.length);
await exportProductsInExcelFile(productList);
console.log('The products has been successfully exported in the Excel file!');
};
void webScraper();
Run the code with the command node index.js, and appreciate the result:
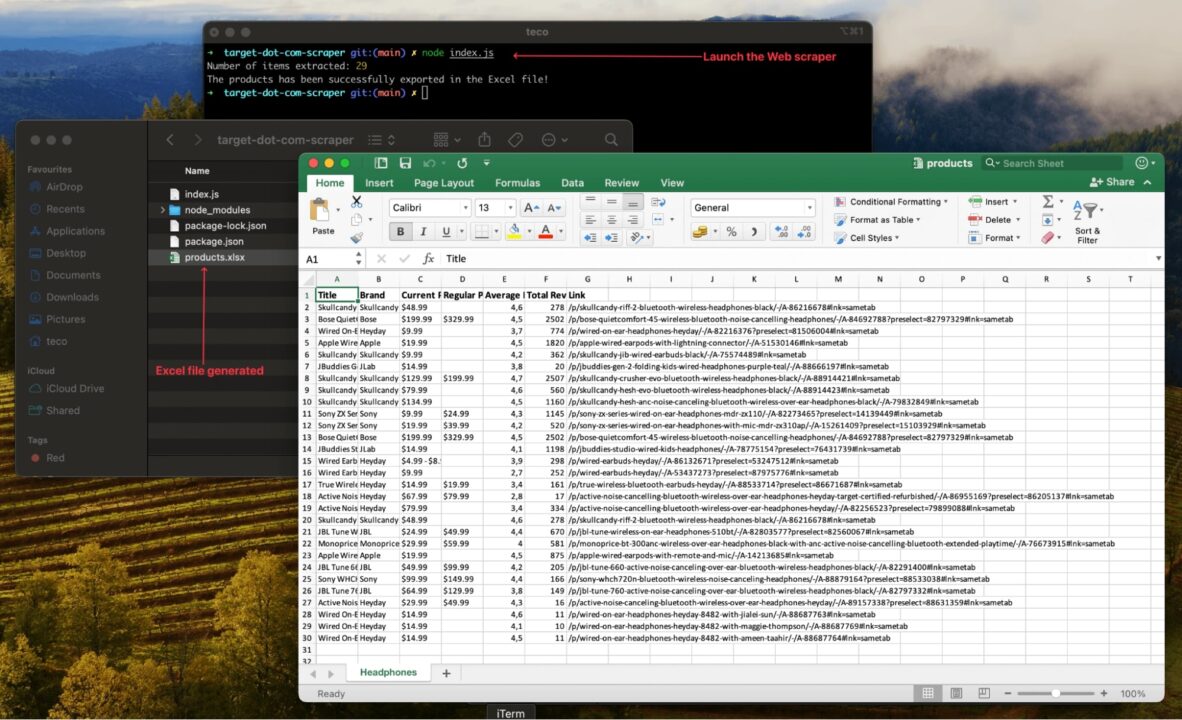
Enhancing the Web Scraper
The web scraper works for a single URL and a single product; to build a relevant dataset, you will need to:
- Scrape more products to have a large variety
- Periodically scrape the data to keep them up to date with the market
You must update the web scraper to handle many URLs at a time, but this comes with many challenges because ecommerce websites such as target.com have anti-scraping methods to prevent intensive web scraping.
For example, sending multiple requests in a second using the same IP address can get you banned by the server.
ScraperAPI’s proxy mode is the right tool to overcome these challenges because it gives you access to a pool of high-quality proxies, prune burned proxies periodically, create a system to rotate these proxies, handle CAPTCHAs, set proper headers, and build many more systems to overcome any roadblocks.
Using ScraperAPI’s Standard API proxy with Puppeteer
Our web scraper is built using Puppeteer and integrates very well with ScraperAPI’s proxy mode with little effort.
To connect to ScraperAPI’s servers through Puppeteer, we need the proxy server, port, username, and password. You can find this information on your dashboard.
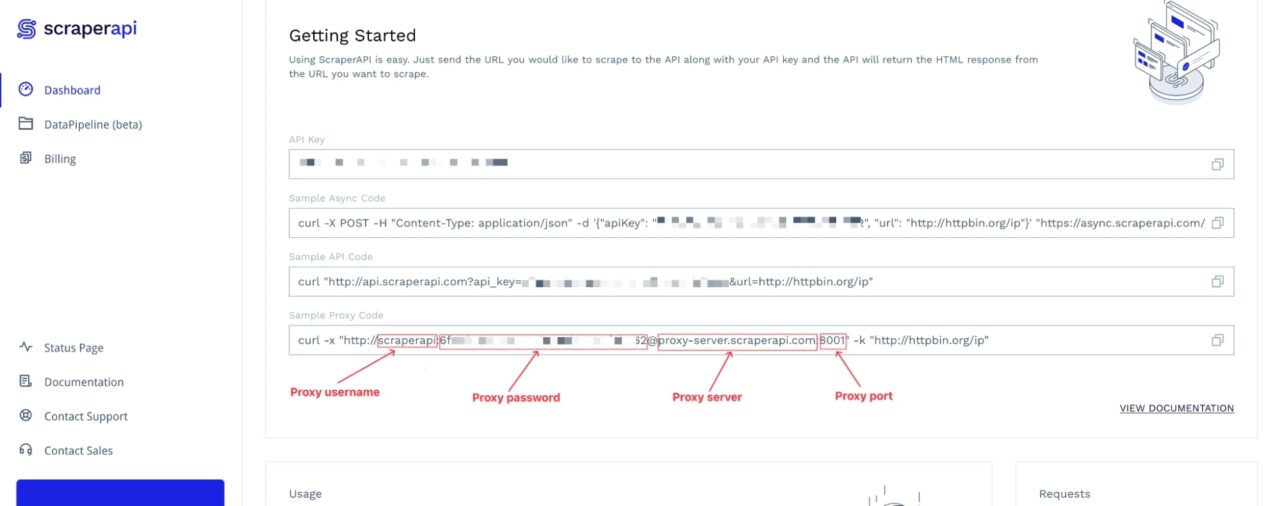
Update the index.js file by adding the code below:
<pre class="wp-block-syntaxhighlighter-code">
const TARGET_DOT_COM_PAGE_URL = 'https://www.google.com/s?searchTerm=headphones&tref=typeahead%7Cterm%7Cheadphones%7C%7C%7Chistory';
PROXY_USERNAME = 'scraperapi';
PROXY_PASSWORD = 'API_K:EY'; // <-- enter your API_Key here
PROXY_SERVER = 'proxy-server.scraperapi.com';
PROXY_SERVER_PORT = '8001';
const webScraper = async () => {
const browser = await puppeteer.launch({
ignoreHTTPSErrors: true,
args: [
`--proxy-server=http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`
]
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto(TARGET_DOT_COM_PAGE_URL, { timeout: 60000 });
// The rest of the code here
};
</pre>
Run the command node index.js.
You will still get the same result as before, but now, each instance you create will be seen as a new user navigating to the page.
Here’s a full guide on why and how to use proxy mode with Puppeteer.
Wrapping Up
To summarize, here are the steps to build a Target.com product scraper:
- Use Puppeteer to launch a browser instance, interact with the page, and download the rendered HTML content.
- Integrate ScraperAPI Proxy Mode into our scraper to avoid getting blocked
- Parse the HTML with Cheerio to extract the data based on DOM selectors
- Store the data extracted in an Excel file for further usage, such as data analysis
To go further with this Web scraper and enhance its capabilities, here are some ideas:
- Scrape all the pages for a product result search
- Create different versions of this script to target different products
- Store scraped data for each product in a different Excel worksheet
- Use DataPipeline to monitor over 10,000 URLs (per project) with no code
Check out ScraperAPI’s documentation for Node.js to learn the ins and outs of the tool. For easy access, here’s this project’s GitHub repository.
Until next time, happy scraping!





