


Want to scrape data from Reddit? You’ve come to the right place.
This web scraping guide will walk you through the process of collecting Reddit posts and comments using Python and ScraperAPI as your data scraping tool. We’ll also show you how to export the scraped data into JSON for easy usage.
Let’s start with our tutorial on how to scrape Reddit with Python!

TL;DR: Full Reddit Data Scraper
For those in a hurry, here is the complete code for building a Reddit scraper in Python:
</p>
import json
from datetime import datetime
import requests
from bs4 import BeautifulSoup
scraper_api_key = 'YOUR API KEY'
def fetch_comments_from_post(post_data):
payload = { 'api_key': scraper_api_key, 'url': 'https://www.reddit.com//r/valheim/comments/15o9jfh/shifte_chest_reason_for_removal_from_valheim/' }
r = requests.get('https://api.scraperapi.com/', params=payload)
soup = BeautifulSoup(r.content, 'html.parser')
# Find all comment elements
comment_elements = soup.find_all('div', class_='thing', attrs={'data-type': 'comment'})
# Initialize a list to store parsed comments
parsed_comments = []
for comment_element in comment_elements:
try:
# Extract relevant information from the comment element, handling potential NoneType errors
author = comment_element.find('a', class_='author').text.strip() if comment_element.find('a', class_='author') else None
dislikes = comment_element.find('span', class_='score dislikes').text.strip() if comment_element.find('span', class_='score dislikes') else None
unvoted = comment_element.find('span', class_='score unvoted').text.strip() if comment_element.find('span', class_='score unvoted') else None
likes = comment_element.find('span', class_='score likes').text.strip() if comment_element.find('span', class_='score likes') else None
timestamp = comment_element.find('time')['datetime'] if comment_element.find('time') else None
text = comment_element.find('div', class_='md').find('p').text.strip() if comment_element.find('div', class_='md') else None
# Skip comments with missing text
if not text:
continue # Skip to the next comment in the loop
# Append the parsed comment to the list
parsed_comments.append({
'author': author,
'dislikes': dislikes,
'unvoted': unvoted,
'likes': likes,
'timestamp': timestamp,
'text': text
})
except Exception as e:
print(f"Error parsing comment: {e}")
return parsed_comments
reddit_query = f"https://www.reddit.com/t/valheim/"
scraper_api_url = f'http://api.scraperapi.com/?api_key={scraper_api_key}&url={reddit_query}'
r = requests.get(scraper_api_url)
soup = BeautifulSoup(r.content, 'html.parser')
articles = soup.find_all('article', class_='m-0')
# Initialize a list to store parsed posts
parsed_posts = []
for article in articles:
post = article.find('shreddit-post')
# Extract post details
post_title = post['post-title']
post_permalink = post['permalink']
content_href = post['content-href']
comment_count = post['comment-count']
score = post['score']
author_id = post.get('author-id', 'N/A')
author_name = post['author']
# Extract subreddit details
subreddit_id = post['subreddit-id']
post_id = post["id"]
subreddit_name = post['subreddit-prefixed-name']
comments = fetch_comments_from_post(post)
# Append the parsed post to the list
parsed_posts.append({
'post_title': post_title,
'post_permalink': post_permalink,
'content_href': content_href,
'comment_count': comment_count,
'score': score,
'author_id': author_id,
'author_name': author_name,
'subreddit_id': subreddit_id,
'post_id': post_id,
'subreddit_name': subreddit_name,
'comments': comments
})
# Save the parsed posts to a JSON file
output_file_path = 'parsed_posts.json'
with open(output_file_path, 'w', encoding='utf-8') as json_file:
json.dump(parsed_posts, json_file, ensure_ascii=False, indent=2)
print(f"Data has been saved to {output_file_path}")
<p>After running the code, you should have the data dumped in the parsed_post.json file.
The image below shows how your parsed_post.json file should look like.
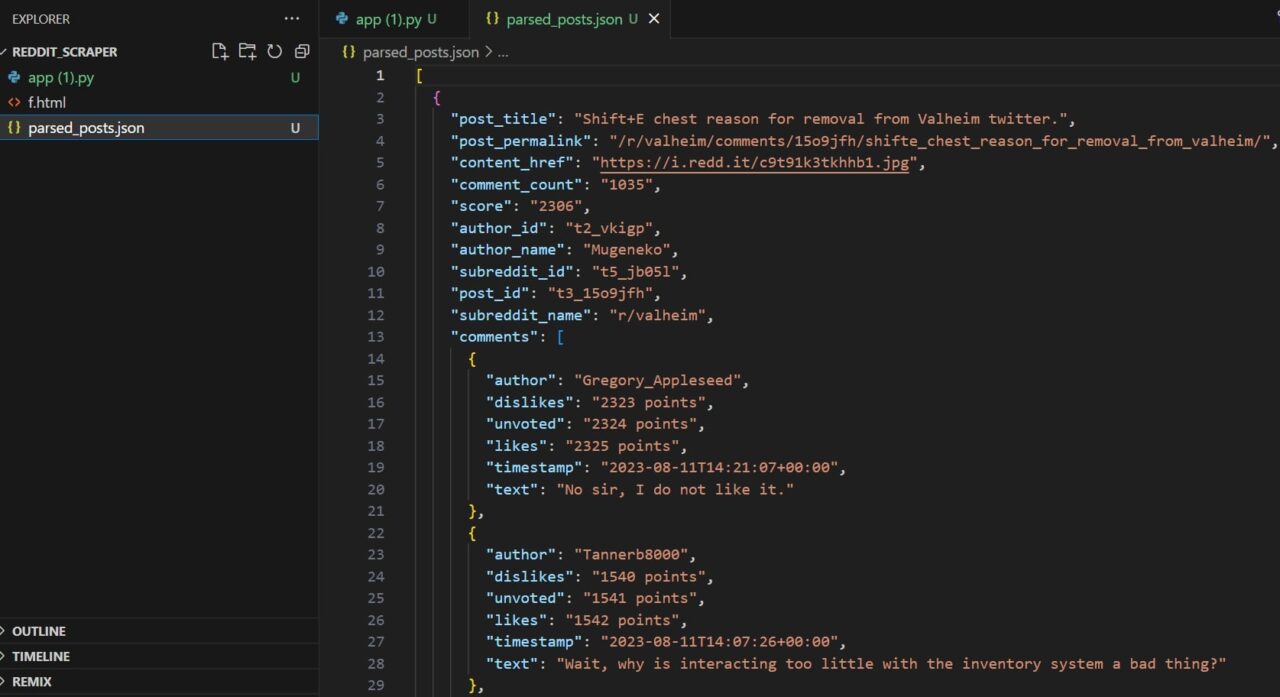
Curious to know how it all happened? Keep reading to get the step-by-step guide on how to build a website scraper for Reddit with Python!
Web Scraping Reddit Project Requirements
For this Reddit web scraping tutorial, you will need Python 3.8 or newer. Ensure you have a supported version before continuing.
Also, you will need to install Request and BeautifulSoup4.
- The Request library helps you to download Reddit’s post search results page.
- BS4 makes it simple to scrape information from web pages.
Install both of these libraries using PIP:
</p>
pip install requests bs4
<p>Now create a new directory and a Python file to store all of the code for this tutorial:
</p>
mkdir reddit_scraper
echo. > app.py
<p>You are now ready to go on to the next steps!
Deciding What to Scrape From Reddit
Before diving headfirst into code, define your target data meticulously. Ask yourself, what specific insights do I want to scrape? Are you after:
- Sentiment analysis on trending topics?
- Analyzing user behavior in a niche subreddit?
- Do you need post titles, comments, or both?
Pinpointing your desired data points will guide your scraping strategy and prevent an overload of irrelevant information.
Consider specific keywords, subreddits, or even post IDs for a focused harvest.
For this article, we’ll focus on this specific subreddit: https://www.reddit.com/t/valheim/ and extract its posts and comments.
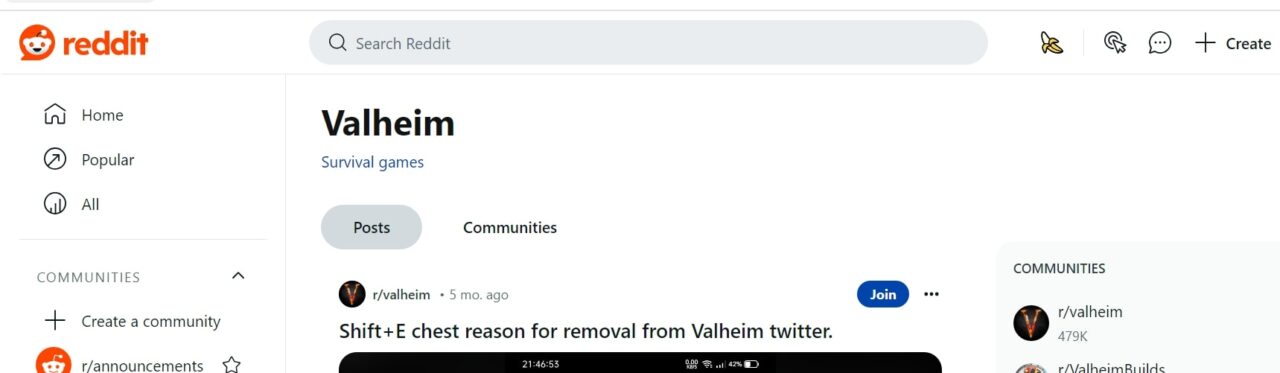
Using ScraperAPI for Reddit Scraping
Reddit is known for blocking scrapers from its website, making collecting data at any meaningful scale challenging. For that reason, we’ll be sending our get() requests through ScraperAPI, effectively bypassing Reddit’s anti-scraping mechanisms without complicated workarounds.
To get started quickly, create a free ScraperAPI account to access your API key.
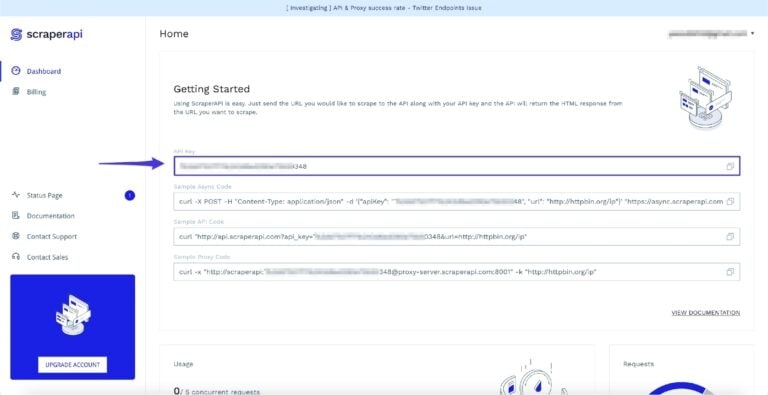
You’ll receive 5,000 free API credits for a seven-day trial – which will start whenever you’re ready.
Now that you have your ScraperAPI account, let’s get down to business!!
Step 1: Importing Your Libraries
For any of this to work, you need to import the necessary Python libraries, which are json, request, and BeautifulSoup.
</p>
import json
from datetime import datetime
import requests
from bs4 import BeautifulSoup
<p>Next, create a variable to store your API key
</p>
scraper_api_key = 'ENTER KEY HERE'
<p>Step 2: Fetching Reddit Post
Let’s start by adding our initial URL to reddit_query and then constructing our get() requests using ScraperAPI’s standard endpoint.
</p>
reddit_query = f"https://www.reddit.com/t/valheim/"
scraper_api_url = f'http://api.scraperapi.com/?api_key={scraper_api_key}&url={reddit_query}'
r = requests.get(scraper_api_url)
<p>Next, let’s parse Reddit’s HTML (using BeautifulSoup), creating a soup object we can now use to select specific elements from the page:
</p>
soup = BeautifulSoup(r.content, 'html.parser')
articles = soup.find_all('article', class_='m-0')
<p>Specifically, we’re searching for all article elements with a CSS class of m-0 using the find_all() method. The resulting list of articles is assigned to the variable articles which contain each post.
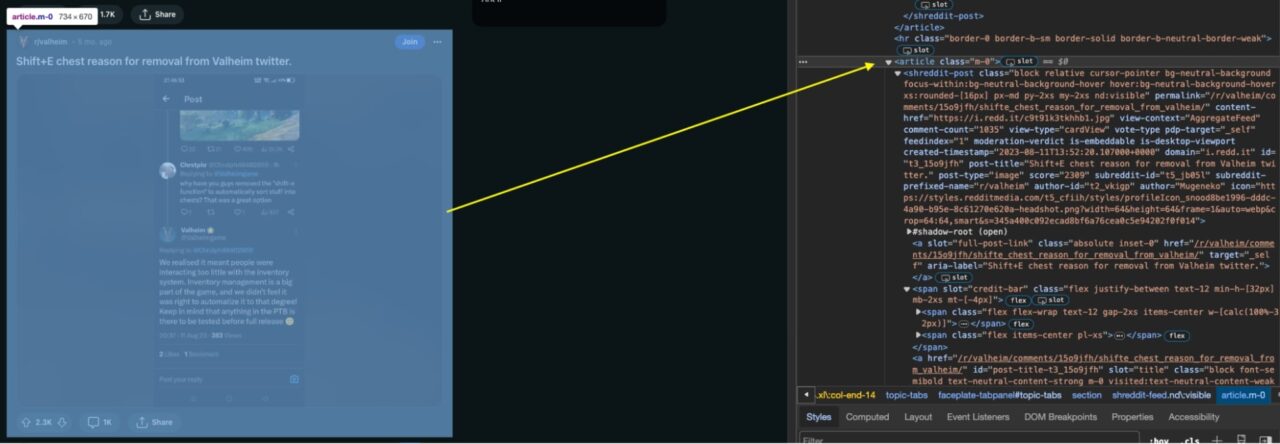
Step 3: Extracting Reddit Post Information
Now that you have scraped the article elements containing each subreddit post on the Reddit page, it is time to extract each post from it along with their information
</p>
# Initialize a list to store parsed posts
parsed_posts = []
for article in articles:
post = article.find('shreddit-post')
# Extract post details
post_title = post['post-title']
post_permalink = post['permalink']
content_href = post['content-href']
comment_count = post['comment-count']
score = post['score']
author_id = post.get('author-id', 'N/A')
author_name = post['author']
# Extract subreddit details
subreddit_id = post['subreddit-id']
post_id = post["id"]
subreddit_name = post['subreddit-prefixed-name']
# Append the parsed post to the list
parsed_posts.append({
'post_title': post_title,
'post_permalink': post_permalink,
'content_href': content_href,
'comment_count': comment_count,
'score': score,
'author_id': author_id,
'author_name': author_name,
'subreddit_id': subreddit_id,
'post_id': post_id,
'subreddit_name': subreddit_name
})
<p>In the code above you identified individual posts by looking for elements with the class shreddit-post. For each of these posts, you then extracted details like:
- Title
- Permalink
- Content link
- Comment count
- Score
- Author ID
- Author name
By referring to specific HTML elements associated with each piece of information.
Moreover, when dealing with subreddit post details, the code also utilizes elements such as shreddit-id, id, and subreddit-prefixed-name to capture relevant information.
In essence, the code programmatically navigates the HTML structure of Reddit posts, gathering essential details for each post and storing them in a list for further use or analysis.
Step 4: Fetching Reddit Post Comments
For you to be able to extract comments from posts, you need to send a request to ScraperAPI, or you risk getting banned by Reddit’s anti-scraping mechanisms.
First, let’s create a fetch_comments_from_post() function to send a request to ScraperAPI using your API KEY (don’t forget to replace YOUR_SCRAPER_API_KEY with your actual API KEY) and the post URL.
</p>
def fetch_comments_from_post(post_data):
payload = { 'api_key': 'YOUR_SCRAPER_API_KEY', 'url': 'https://www.reddit.com//r/valheim/comments/15o9jfh/shifte_chest_reason_for_removal_from_valheim/' }
r = requests.get('https://api.scraperapi.com/', params=payload)
soup = BeautifulSoup(r.content, 'html.parser')
<p>This request is then passed to BeautifulSoup for parsing.
Then, we can identify all comments on the SubReddit by looking for div elements that have a data-type attribute set to comment.
</p>
# Find all comment elements
comment_elements = soup.find_all('div', class_='thing', attrs={'data-type': 'comment'})
<p>Now that you have found the comments, it’s time to extract them.
</p>
# Initialize a list to store parsed comments
parsed_comments = []
for comment_element in comment_elements:
try:
# Extract relevant information from the comment element, handling potential NoneType errors
author = comment_element.find('a', class_='author').text.strip() if comment_element.find('a', class_='author') else None
dislikes = comment_element.find('span', class_='score dislikes').text.strip() if comment_element.find('span', class_='score dislikes') else None
unvoted = comment_element.find('span', class_='score unvoted').text.strip() if comment_element.find('span', class_='score unvoted') else None
likes = comment_element.find('span', class_='score likes').text.strip() if comment_element.find('span', class_='score likes') else None
timestamp = comment_element.find('time')['datetime'] if comment_element.find('time') else None
text = comment_element.find('div', class_='md').find('p').text.strip() if comment_element.find('div', class_='md') else None
# Skip comments with missing text
if not text:
continue # Skip to the next comment in the loop
# Append the parsed comment to the list
parsed_comments.append({
'author': author,
'dislikes': dislikes,
'unvoted': unvoted,
'likes': likes,
'timestamp': timestamp,
'text': text
})
except Exception as e:
print(f"Error parsing comment: {e}")
return parsed_comments
<p>In the code above, we called the parsed_comments list to store the information extracted. The code then iterates through each comment_element in a collection of comment elements.
Inside the loop, we used find() to extract relevant details from each comment, such as the:
- Author’s name
- Dislikes
- Unvoted count
- Likes
- Timestamps
- Text content of the comment
To handle cases where some information might be missing (resulting in NoneType errors), we’re using a conditional statement. If a comment lacks text content, it is skipped, and the loop moves on to the next comment. This will save us time and stop the NoneType errors.
The extracted data is then organized into a dictionary for each comment and appended to the parsed_comments list.
Any errors that occur during the parsing process are caught and printed.
Finally, the list containing the parsed comments is returned, providing a structured representation of essential comment information for further use or analysis.
After the comments for each subreddit post are extracted, you can save the comments in the initial parsed_post data by adding the code below.
</p>
comments = fetch_comments_from_post(post)
<p>Step 5: Converting to JSON
Now that you have extracted all the data you need, it is time to save them to a JSON file for easy usability.
</p>
# Save the parsed posts to a JSON file
output_file_path = 'parsed_posts.json'
with open(output_file_path, 'w', encoding='utf-8') as json_file:
json.dump(parsed_posts, json_file, ensure_ascii=False, indent=2)
print(f"Data has been saved to {output_file_path}")
<p>The output_file_path variable is set to the file name parsed_posts.json. The code then opens this file in write mode (‘w‘) and uses the json.dump() function to write the content of the parsed_posts list to the file in JSON format.
The ensure_ascii=False argument ensures that non-ASCII characters are handled properly, and indent=2 adds indentation for better readability in the JSON file.
After writing the data, a message is printed to the console indicating that the data has been successfully saved to the specified JSON file (parsed_posts.json).
Testing the Scraper
To test out the scraper is very easy, you just run your Python code, and all data posts and comments in the subreddit provided will be scraped and converted into a JSON file named parsed_post.json.
Congratulations, you have successfully scraped data from Reddit, and you are free to use the data any way you want!
Successfully Scrape Reddit Data with ScraperAPI
This tutorial presented a step-by-step approach to scraping data from Reddit, showing you how to
- Collect the 25 most recent posts within a subreddit
- Loop through all posts to collect comments
- Send your requests through ScraperAPI to avoid getting banned
- Export all extracted data into a structured JSON file
As we conclude this insightful journey into the realm of Reddit scraping, we hope you’ve gained valuable insights into the power of Python and ScraperAPI in unlocking the treasure trove of information Reddit holds.
Stay curious, and remember, with great scraping capabilities come great responsibilities.
Until next time, happy scraping!




