



What is PerimeterX (now Human Security)?
PerimeterX is a cybersecurity firm that provides tools to protect web applications from automated attacks, fraudulent activities, and web scraping. Using advanced machine learning algorithms and risk scores, PerimeterX analyzes request fingerprints and behavioral signals to detect and block bot attacks in real time.
One of its essential defenses, the HUMAN Bot Defender (formerly PerimeterX Bot Defender), is directly aimed at scraping bots. It sits directly on a website, monitoring and collecting information from incoming web requests. These requests are then analyzed according to predefined rules and later acted upon if found suspicious.
While PerimeterX does allow some legitimate bots, like Googlebot, to pass through, it remains a formidable barrier to unauthorized web scraping and other automated activities.
Recognize PerimeterX
To identify PerimeterX’s presence on a website, look for these characteristics:
- Internal property: Check your browser’s console for the “window._pxAppId” property.
-
Collector XHR: PerimeterX can operate with or without an external server.
- External Collector: Look for requests to domains like “px-cdn.net”, “pxchk.net”, or “px-client.net”.
- Internal Endpoint: An internal endpoint will likely follow the format “/rf8vapwA/xhr/api/v2/collector”.
- Cookies: PerimeterX sets cookies with names like “_px3”,” _pxhd”, and “_px_vid”.
Note: Are you frustrated that your web scrapers are blocked once and again? ScraperAPI handles rotating proxies and headless browsers for you. Try it for FREE!
Popular PerimeterX Errors
When PerimeterX determines that a visitor is an automated scraper or bot, it will block access and serve a 403 Forbidden response along with branded block pages. These responses come from the PerimeterX sensor integrated with the site’s infrastructure.
Here are some common PerimeterX error messages you might encounter:
| Message or Code | Meaning |
| 403 Forbidden | PerimeterX has flagged your request as potentially automated. |
| “Please prove you are human” | This message appears when the JavaScript browser test fails, prompting the user to verify their humanity. |
| “Enable cookies” | Irregular or missing cookies header |
| “Try again later” | Temporary block due to suspicious activity patterns |
| APTCHA challenge | Triggered by failed fingerprinting and behavior checks, requiring additional verification to continue. |
Remember, PerimeterX’s blocking behaviors are designed to be dynamic and may change over time. Always be prepared to adapt your scraping techniques as you encounter new types of blocks or challenges.
How does PerimeterX detect bots?
You can recognize PerimeterX by the “Press & Hold” and “Please verify you are a human” messages similar to the image below:

To avoid anti-web scraping services like PerimeterX, we first should understand how they work, which really boils down to 3 categories of detection:
- IP address
- Javascript Fingerprint
- Request details
Services like PerimeterX use these tools to calculate a trust score for every visitor. A low score means you’re most likely a bot, so you’ll either be required to solve a CAPTCHA challenge or denied access entirely. So, how do we get a high score?
IP Addresses / Proxies
PerimeterX analyzes IP addresses to identify suspicious activity. Ideally, we want to distribute our load through proxies. These proxies can be Datacenter, Residential, or Mobile proxies.
So, to maintain a high trust score, your scraper should rotate through a pool of residential or mobile proxies. To learn more, check our blog post on what residential proxies are and why use them for scraping.
Javascript Fingerprints
This topic is quite extensive, especially for junior developers, but here is a quick summary.
Websites can use Javascript to fingerprint the connecting client (the scraper) because Javascript leaks data about the client, including the operating system, support fonts, visual rendering capabilities, etc.
For example, if PerimeterX detects a large number of Linux clients connecting through 1280×720 windows, it can simply deduce that this sort of setup is likely a bot and gives everyone with these fingerprint details low trust scores.
If you’re using Selenium to bypass PerimeterX, you need to patch many of these leaks to escape the low trust zone. You can do this by modifying the browser to set fake fingerprint details or using a patched version of the headless browser like “Selenium-wire.”
For more on this, check out our blog: 10 tips for web scraping without getting blocked.
Request Details
PerimeterX can still give us low trust scores if our connection patterns are unusual, even if we have a large pool of IP addresses and have patched our headless browser to prevent key fingerprint details from being leaked.
It observes various specified events, which suggests that it utilizes behavioral analysis. As a result, it’s important to be careful when scraping these sites. To avoid this, your scraper should scrape in non-obvious patterns. It should also connect to non-target pages like the website’s homepage once in a while to appear more human-like.
TNow that we understand how our scraper is being detected, we can start researching how to bypass these measures. Selenium, Playwright, and Puppeteer have large communities, and the keyword to look for here is “stealth.”
Unfortunately, this is not very bulletproof, as PerimeterX can simply collect publicly known patches and adjust their service accordingly. You should have experienced this a couple of times if you have been trying out this method manually, which means you have to figure out many things yourself.
A better alternative is to use a web scraping API to scrape protected websites easily.
Bypassing PerimeterX with ScraperAPI
ScraperAPI helps you avoid getting your IP banned by rotating IP addresses, handling CAPTCHAs, and managing request limits. It simplifies the entire scraping process by providing reliable access to web pages, ensuring you can focus on extracting and analyzing data rather than handling anti-scraping measures.
Using Python and ScraperAPI makes scraping large amounts of data from PerimeterX-protected websites much easier.
In this guide, we’ll demonstrate how to scrape product information from Neiman Marcus, a well-known department store with an e-commerce website protected by PerimeterX.
Prerequisites
To follow along with this guide, ensure you have met the following prerequisites:
- Python v3.10 or later installed
- Requests and Beautifulsoup4 libraries
- A ScraperAPI account – create a free ScraperAPI account and get 5000 free API credits to start!
Step 1: Set Up Your Environment
First, let’s set up a virtual environment to avoid any conflicts with existing Python modules or libraries.
For macOS users:
pip install virtualenv
python3 -m virtualenv venv
source venv/bin/activate
For Windows users:
pip install virtualenv
virtualenv venv
srouce venv\Scripts\activate
Once your virtual environment is activated, install the required libraries:
pip install requests beautifulsoup4 lxml
Step 2: Analyze the Target Website
Our target website is Neiman Marcus, a well-known department store with an e-commerce website, where we’ll try to scrape product prices.
Using tools like Wappalyzer, we can confirm that PerimeterX protects Neiman Marcus. However, to bypass the protection, we’ll need to use ScraperAPI.
We’ll focus on scraping product information from the men’s loafers category page.
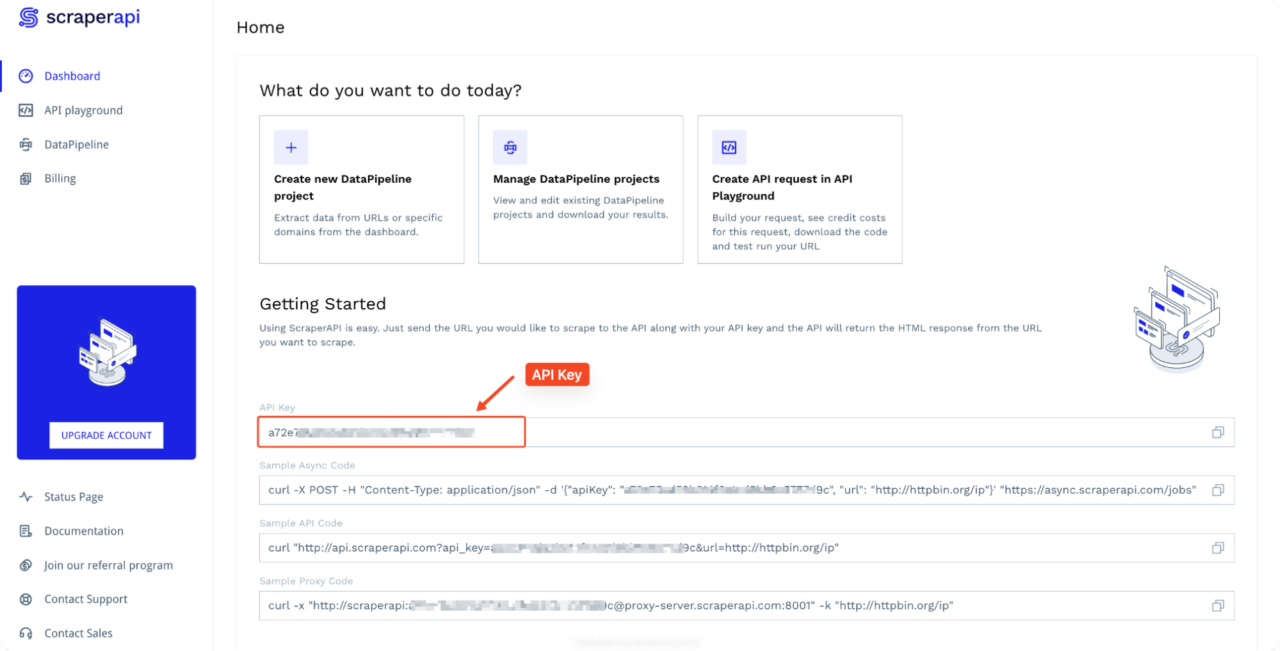
Step 3: Set Up ScraperAPI
To get started, create a free ScraperAPI account and copy your API key from your dashboard.
Step 4: Write the Scraping Script
Now, let’s create a Python script that uses ScraperAPI to bypass PerimeterX and scrape product information:
import requests
from bs4 import BeautifulSoup
import json
API_KEY = "YOUR_API_KEY"
url = "https://www.neimanmarcus.com/en-ng/c/shoes-shoes-loafers-slip-ons-cat10580739?navpath=cat000000_cat000470_cat000550_cat10580739"
payload = {"api_key": API_KEY, "url": url, "render": "true"}
def scrape_product_info():
response = requests.get("http://api.scraperapi.com", params=payload)
if response.status_code != 200:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return []
soup = BeautifulSoup(response.text, 'lxml')
products = soup.find_all('div', class_='product-thumbnail__details')
product_info = []
for product in products:
designer = product.find('span', class_='designer')
name = product.find('span', class_='name')
price = product.find('span', class_='price-no-promo')
badge = product.find('div', class_='gift-badge')
info = {
'designer': designer.text.strip() if designer else 'N/A',
'name': name.text.strip() if name else 'N/A',
'price': price.text.strip() if price else 'N/A',
'batch_details': badge.text.strip() if badge else 'N/A'
}
product_info.append(info)
return product_info
def save_to_json(product_info, filename='neiman_marcus_loafers.json'):
with open(filename, 'w', encoding='utf-8') as jsonfile:
json.dump(product_info, jsonfile, ensure_ascii=False, indent=4)
if __name__ == "__main__":
print("Scraping product information...")
product_info = scrape_product_info()
if product_info:
print(f"Found {len(product_info)} products.")
save_to_json(product_info)
print("Product information saved to neiman_marcus_loafers.json")
else:
print("No products found or there was an error scraping the website.")
Note: To run this example, replace
YOUR_API_KEY with your actual API key from your dashboard.
Here, we’re making a request to ScraperAPI, passing our API key and the target
URL. ScraperAPI will handle the complexities of rotating IP addresses, solving
CAPTCHAs, and managing other PerimeterX anti-scraping measures. The
render=true parameter within the payload instructs ScraperAPI to
fully render the target webpage in a headless browser, ensuring that any
dynamic content protected by PerimeterX is fully loaded and available for
scraping.
Once ScraperAPI returns the rendered HTML content, we use
BeautifulSoup to parse it. We target specific HTML elements using
their class names (product-thumbnail__details,
designer, name, price-no-promo,
gift-badge) to extract the desired product information.
Step 5: Run the Script
Save the script as neiman_marcus_scraper.py and run it:
python neiman_marcus_scraper.py
This script will then scrape product information from Neiman Marcus men’s
loafers page, bypassing PerimeterX protection using ScraperAPI. The scraped
data will be saved in a JSON file named
neiman_marcus_loafers.json.
[
{
"designer": "Tod's",
"name": "Men's Suede Moccasin Slipper Loafers",
"price": "$725",
"batch_details": "N/A"
},
{
"designer": "Ferragamo",
"name": "Men's Cosimo Leather Ganicni Bit Loafers",
"price": "$895",
"batch_details": "Best Seller"
},
{
"designer": "Prada",
"name": "Men's Monolith Patent Leather Loafers",
"price": "$1,270",
"batch_details": "Exclusive"
},
{
"designer": "Santoni",
"name": "Men's Kalvin Leather Penny Loafers",
"price": "$1,330",
"batch_details": "N/A"
},
Truncated data,
}
Congratulations, if you have been coding along so far, then you have successfully bypassed a website protected by Human Security! This approach can also be adapted to scrape other PerimeterX-protected websites.
Final Thoughts
There’s no denying that PerimeterX (now HUMAN Security) is a sophisticated anti-bot system that employs a range of techniques to protect websites from unwanted scraping. From monitoring IP addresses and analyzing request headers to using various fingerprinting methods, PerimeterX presents a formidable challenge for web scrapers.
ScraperAPI’s team is constantly updating the API bypassing methods to keep your scrapers running, making it the best way to scrape data from PerimeterX protected sites without getting blocked.
If you’re interested in learning how to scrape other popular websites, check out our other how to scrape guides:




