



In this article, we’ll show you how to build an indetectable web scraper to retrieve data from Home Depot and store the result in a CSV file using Node.js and ScraperAPI.
TL;DR: Full Home Depot Scraper
For those in a hurry, here’s the complete script we’ll build in this tutorial:
const axios = require('axios');
const cheerio = require('cheerio');
const { exportDataInCsvFile } = require("./csv-exporter");
const EXPORT_FILENAME = 'products.csv';
const HOMEDEPOT_PAGE_URL = 'https://www.homedepot.com/b/Appliances-Refrigerators/N-5yc1vZc3pi?catStyle=ShowProducts&NCNI-5&searchRedirect=refrigerators&semanticToken=i10r10r00f22000000000_202311261341369949425674627_us-east4-5qn1%20i10r10r00f22000000000%20%3E%20rid%3A%7B945c050322f005b6254c2457daf503cb%7D%3Arid%20st%3A%7Brefrigerators%7D%3Ast%20ml%3A%7B24%7D%3Aml%20ct%3A%7Brefrigerator%7D%3Act%20nr%3A%7Brefrigerator%7D%3Anr%20nf%3A%7Bn%2Fa%7D%3Anf%20qu%3A%7Brefrigerator%7D%3Aqu%20ie%3A%7B0%7D%3Aie%20qr%3A%7Brefrigerator%7D%3Aqr&Nao=24';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '' // <--- Enter your API key here
const webScraper = async () => {
console.log('Fetching data with ScraperAPI...');
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: HOMEDEPOT_PAGE_URL,
render: true,
country_code: 'us'
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const productList = [];
console.log('Extract information from the HTML...');
$(".browse-search__pod").each((_, el) => {
const price = $(el).find('.price-format__main-price').text();
const model = $(el).find('.product-identifier--bd1f5').text();
const link = $(el).find("div[data-testid='product-header'] a").attr('href');
const description = $(el).find("div[data-testid='product-header'] .product-header__title-product--4y7oa").text();
const brand = $(el).find("div[data-testid='product-header'] .product-header__title__brand--bold--4y7oa").text();
const characteristics = [];
const values = $(el).find('.kpf__specs .kpf__value');
values.each((index, value) => {
characteristics.push([$(value).text()]);
});
productList.push({
description: description.trim(),
price,
model: model.replace('Model# ', ''),
brand: brand.trim(),
link: `https://homedepot.com${link}`,
characteristics: characteristics.join(' - '),
});
});
console.log('JSON result:', productList);
await exportDataInCsvFile(EXPORT_FILENAME, productList);
} catch (error) {
console.log(error)
}
};
void webScraper();
Note: Replace <API_KEY> with your ScraperAPI’s API key before running the code. If you don’t have one, create a free ScraperAPI account to claim 5,000 API credits to test the tool.
Want to understand each line of code of this web scraper? Let’s build it from scratch!
Scraping Home Depot Product Data
As a use case for scraping Home Depot products, we will write a web scraper in Node.js that finds Headphones and extracts the following information for each product:
- Model
- Description
- Price
- Brand
- Characteristics
- Product’s link
When the scraping is done and the data extracted, the web scraper will export them in a CSV file for further usage.
Prerequisites
You must have these tools installed on your computer to follow this tutorial.
- Node.js 18+ and NPM – Download link
- Knowledge of JavaScript and Node.js API.
- Create a ScraperAPI account and get 5,000 free API credits to get started.
Step 1: Set up the project
mkdir homedepot-scraper
cd homedepot-scraper
npm init -y
The last command above creates a package.json file in the folder. Create a file index.js in which we will write our scraper; keep it empty for now.
touch index.js
Step 2: Install the dependencies
To build the Home Depot Web scraper, we need these two Node.js packages:
- Axios – to build the HTTP request (headers, body, query string parameters, etc…), send it to the ScraperAPI standard API, and download the HTML content.
- Cheerio – to extract the information from the HTML downloaded from the request sent using Axios.
Run the command below to install these packages:
npm install axios cheerio
Step 3: Identify the DOM Selectors to Target
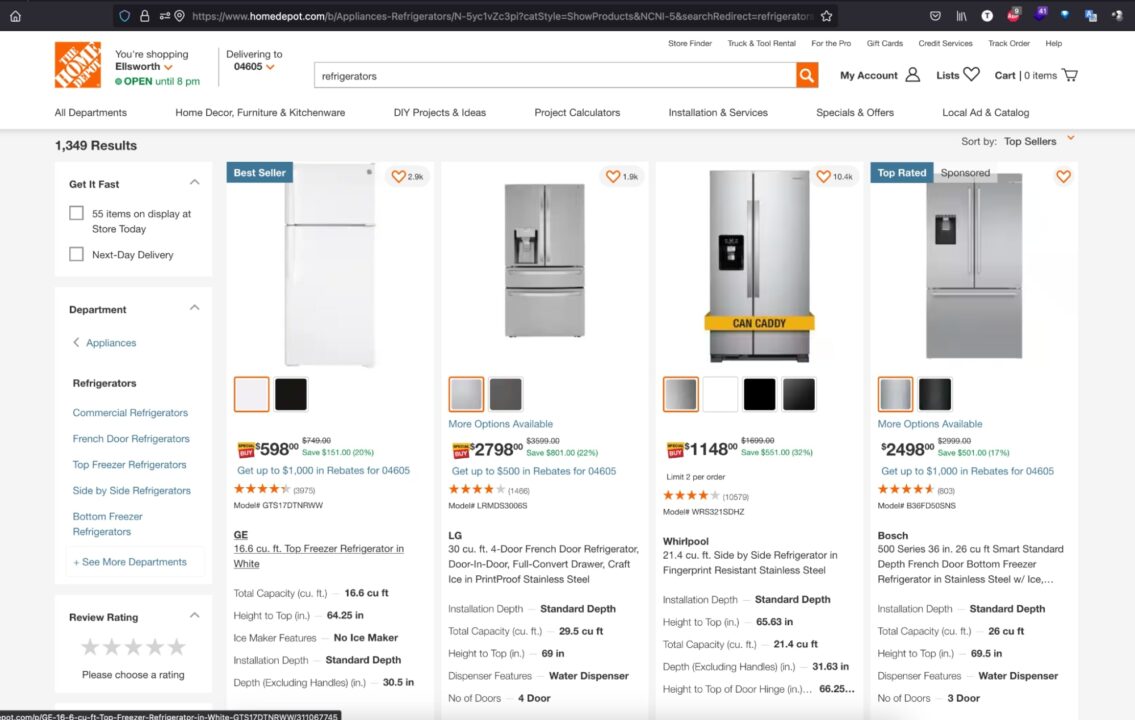
Navigate to https://www.homedepot.com; type “refrigerators” in the search bar and press enter.
When the search result appears, inspect the page to display the HTML structure and identify the DOM selector associated with the HTML tag wrapping the information we want to extract.
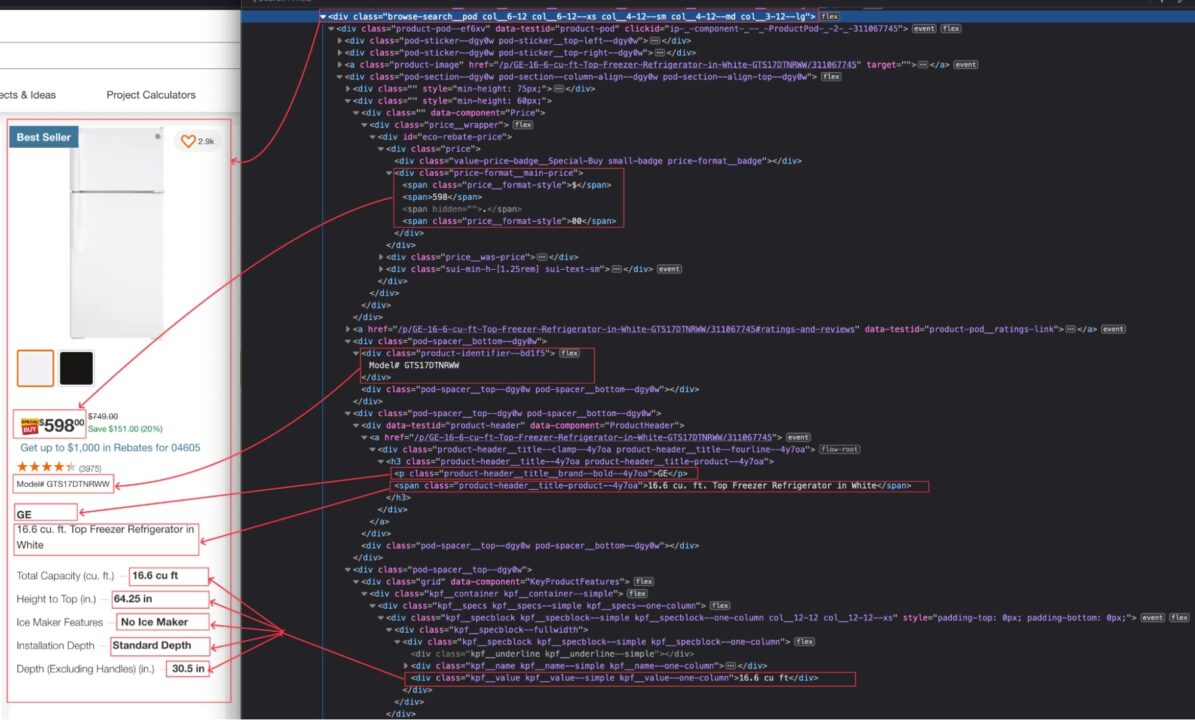
In the picture above, we can define the following DOM selectors to extract the information:
| Information | DOM selector |
| Model | .browse-search__pod .product-identifier–bd1f5 |
| Description | .browse-search__pod div[data-testid=’product-header’] .product-header__title-product–4y7oa |
| Price | .browse-search__pod .price-format__main-price |
| Brand | .browse-search__pod div[data-testid=’product-header’] .product-header__title__brand–bold–4y7oa |
| Characteristics | .browse-search__pod .kpf__specs .kpf__value |
| Home Depot’s link | .browse-search__pod div[data-testid=’product-header’] a |
Be careful when writing the DOM selector because a misspelling will prevent the script from retrieving the correct value.
Step 4: Scrape the Home Depot Product Page
Let’s use Axios to build the HTTP request to send to the ScraperAPI Standard API; we will need the following parameters:
- The URL to scrape: It is the URL of the Home Depot products search page. To retrieve the URL to scrape, copy the URL in your browse address bar; this is the URL for the search of “refrigerators”.
- The API Key: to authenticate against the Standard API and perform the scraping; if you still have enough credit, find it on the dashboard page of your ScraperAPI account.
- Enable JavaScript: Home Depot’s website is built with a modern frontend Framework that adds JavaScript for better interactivity. To enable JavaScript while Scraping, we will use a property named
renderwith the value set totrue. - Enable Geotargeting: The Home Depot website is only available in some countries; to ensure our request doesn’t get blocked, we must indicate a valid country the request comes from, such as the United States.
Open the index.js file and add the code below that builds the HTTP request, sends it, receives the response, and prints it in the terminal.
const axios = require('axios');
const HOMEDEPOT_PAGE_URL = 'https://www.homedepot.com/b/Appliances-Refrigerators/N-5yc1vZc3pi?catStyle=ShowProducts&NCNI-5&searchRedirect=refrigerators&semanticToken=i10r10r00f22000000000_202311261341369949425674627_us-east4-5qn1%20i10r10r00f22000000000%20%3E%20rid%3A%7B945c050322f005b6254c2457daf503cb%7D%3Arid%20st%3A%7Brefrigerators%7D%3Ast%20ml%3A%7B24%7D%3Aml%20ct%3A%7Brefrigerator%7D%3Act%20nr%3A%7Brefrigerator%7D%3Anr%20nf%3A%7Bn%2Fa%7D%3Anf%20qu%3A%7Brefrigerator%7D%3Aqu%20ie%3A%7B0%7D%3Aie%20qr%3A%7Brefrigerator%7D%3Aqr&Nao=24';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '' // <--- Enter your API key here
const webScraper = async () => {
console.log('Fetching data with ScraperAPI...');
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: HOMEDEPOT_PAGE_URL,
render: true,
country_code: 'us'
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
console.log("HTML content", html);
} catch (error) {
console.log(error)
}
};
void webScraper();
Run the command node index.js to execute the web scraper.
Step 5: Extract Information from the HTML
Now that we have the HTML content of the page, we must parse it using Cheerio to build the DOM structure, making extracting all the information we want possible.
Cheerio provides functions to load HTML text and then navigate through the structure to extract information using the DOM selectors.
The code below goes through each element, extracts the information, and returns an array containing all the products on the page.
const cheerio = require('cheerio');
const $ = cheerio.load(html);
const productList = [];
console.log('Extract information from the HTML...');
$(".browse-search__pod").each((_, el) => {
const price = $(el).find('.price-format__main-price').text();
const model = $(el).find('.product-identifier--bd1f5').text();
const link = $(el).find("div[data-testid='product-header'] a").attr('href');
const description = $(el).find("div[data-testid='product-header'] .product-header__title-product--4y7oa").text();
const brand = $(el).find("div[data-testid='product-header'] .product-header__title__brand--bold--4y7oa").text();
const characteristics = [];
const values = $(el).find('.kpf__specs .kpf__value');
values.each((index, value) => {
characteristics.push([$(value).text()]);
});
productList.push({
description: description.trim(),
price,
model: model.replace('Model# ', ''),
brand: brand.trim(),
link: `https://homedepot.com${link}`,
characteristics: characteristics.join(' - '),
});
});
console.log('JSON result:', productList);
Step 6: Export the Data Into a CSV File
To save the extracted data in a CSV file, we will use a Node.js package called csv-writer that handles the tedious task of creating the CSV structure and inserting items inside.
Let’s install it by running the command below:
npm install csv-writer
Create a new file csv-exporter.js, and add the code below:
const path = require('path');
const csvWriter = require('csv-writer');
const COLUMN_HEADER = [
{ id: 'model', title: 'Model' },
{ id: 'description', title: 'Description' },
{ id: 'price', title: 'Price (USD)' },
{ id: 'brand', title: 'Brand' },
{ id: 'link', title: 'Link' },
{ id: 'characteristics', title: 'Characteristics' },
];
const exportDataInCsvFile = async (filename, data) => {
// TODO perform fields validation in data
const writer = csvWriter.createObjectCsvWriter({
path: path.resolve(__dirname, filename),
header: COLUMN_HEADER,
});
await writer.writeRecords(data);
};
module.exports = {
exportDataInCsvFile,
}
The exciting part of the code above is the COLUMN_HEADER variable containing an array of objects mapping the CSV column header to a product’s property.
We will import the file in the index.js file and call the function exportDataInCsvFile() to save the extracted data.
Step 7: Test the implementation
After importing and using the function to save the data in a CSV file, here is the final code of our web scraper.
const axios = require('axios');
const cheerio = require('cheerio');
const { exportDataInCsvFile } = require("./csv-exporter");
const EXPORT_FILENAME = 'products.csv';
const HOMEDEPOT_PAGE_URL = 'https://www.homedepot.com/b/Appliances-Refrigerators/N-5yc1vZc3pi?catStyle=ShowProducts&NCNI-5&searchRedirect=refrigerators&semanticToken=i10r10r00f22000000000_202311261341369949425674627_us-east4-5qn1%20i10r10r00f22000000000%20%3E%20rid%3A%7B945c050322f005b6254c2457daf503cb%7D%3Arid%20st%3A%7Brefrigerators%7D%3Ast%20ml%3A%7B24%7D%3Aml%20ct%3A%7Brefrigerator%7D%3Act%20nr%3A%7Brefrigerator%7D%3Anr%20nf%3A%7Bn%2Fa%7D%3Anf%20qu%3A%7Brefrigerator%7D%3Aqu%20ie%3A%7B0%7D%3Aie%20qr%3A%7Brefrigerator%7D%3Aqr&Nao=24';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '' // <--- Enter your API key here
const webScraper = async () => {
console.log('Fetching data with ScraperAPI...');
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: HOMEDEPOT_PAGE_URL,
render: true,
country_code: 'us'
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const productList = [];
console.log('Extract information from the HTML...');
$(".browse-search__pod").each((_, el) => {
const price = $(el).find('.price-format__main-price').text();
const model = $(el).find('.product-identifier--bd1f5').text();
const link = $(el).find("div[data-testid='product-header'] a").attr('href');
const description = $(el).find("div[data-testid='product-header'] .product-header__title-product--4y7oa").text();
const brand = $(el).find("div[data-testid='product-header'] .product-header__title__brand--bold--4y7oa").text();
const characteristics = [];
const values = $(el).find('.kpf__specs .kpf__value');
values.each((index, value) => {
characteristics.push([$(value).text()]);
});
productList.push({
description: description.trim(),
price,
model: model.replace('Model# ', ''),
brand: brand.trim(),
link: `https://homedepot.com${link}`,
characteristics: characteristics.join(' - '),
});
});
console.log('JSON result:', productList);
await exportDataInCsvFile(EXPORT_FILENAME, productList);
} catch (error) {
console.log(error)
}
};
void webScraper();
Run the code with the command node index.js, and appreciate the result:
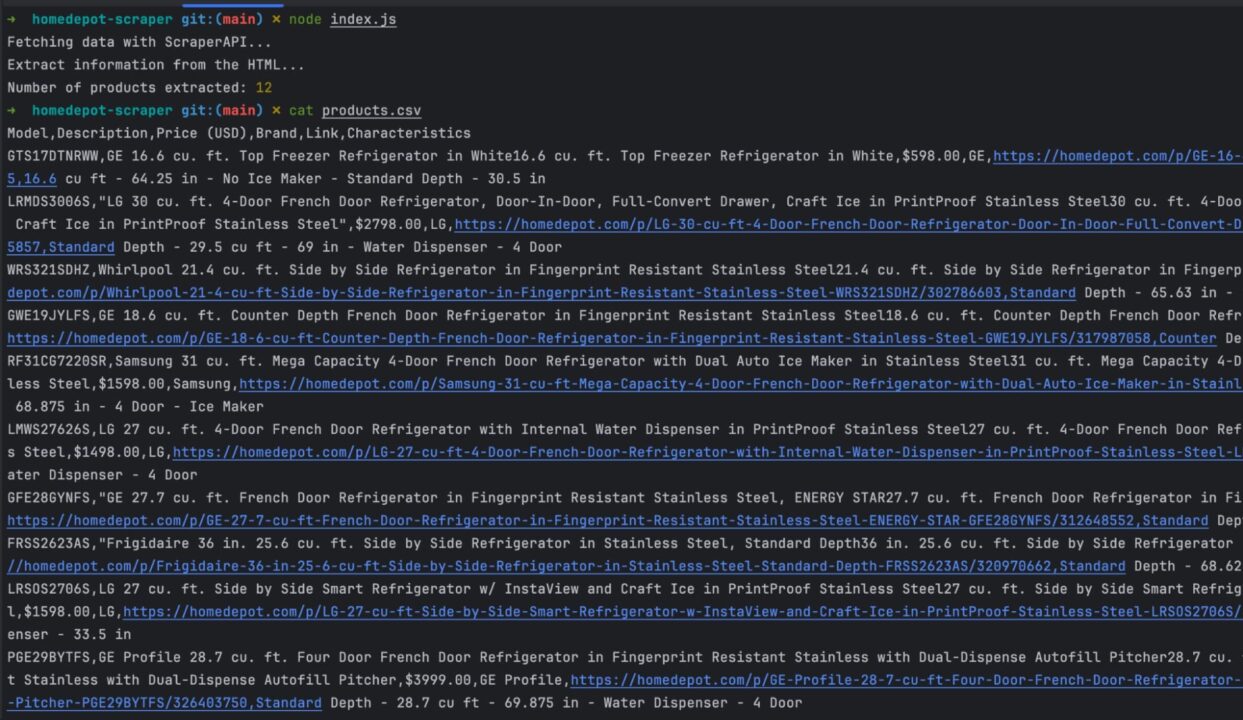
Wrapping Up
To build a Web scraper for the Home Depot website, we can summarize the process in the following steps:
- Send an HTTP request using Axios to the ScraperAPI standard API with the Home page to Scrape and download the rendered HTML content. Ensure that geotargeting is enabled by setting the country to the United States
- Parse the HTML with Cheerio to extract the data based on DOM selectors
- Format and transform the data retrieved to suit your needs
- Export the data extracted in a CSV file
The CSV file can be populated by the many products that will become a dataset you can analyze to gain a competitive advantage in your market.
Here are a few ideas to go further with this Home Depot Web scraper:
- Retrieve more data about a product, such as technical characteristics, reviews, etc…
- Make the Web scraper dynamic by allowing you to type the search keyword directly
- Update the CSV exporter to append data in the existing CSV file
- Use the Async Scraper service to scrape up to 10,000 URLs asynchronously
To learn more, check out ScraperAPI’s documentation for Node.js. For easy access, here’s this project’s GitHub repository.
Until next time, happy scraping!




