TL;DR: Google Jobs Python Scraper
For those in a hurry, here’s a quick way to scrape Google Jobs for multiple queries using Python and ScraperAPI:
import requests
queries = ['video editor', 'python developer']
for query in queries:
payload = {
'api_key': 'YOUR_API_KEY',
'query': query,
'country_code': 'us',
'output_format': 'csv'
}
response = requests.get('https://api.scraperapi.com/structured/google/jobs', params=payload)
if response.status_code == 200:
filename = f'{query.replace(" ", "_")}_jobs_data.csv'
with open(filename, 'w', newline='', encoding='utf-8') as file:
file.write(response.text)
print(f"Data for {query} saved to {filename}")
else:
print(f"Error {response.status_code} for query {query}: {response.text}")
This scraper iterates through a list of job queries, sending requests through ScraperAPI’s Google Jobs endpoint and saves the results as CSV files.
Want to learn how it was built? Keep reading!
The Challenges of Scraping Google Jobs
Google Jobs (or Google for Jobs) is one of the world’s most significant sources of job listings. It gathers job listings from millions of websites in one place, allowing job seekers to find the right opportunity in Google search results.

Because these results are publicly available, we can scrape Google Jobs listings legally, following ethical practices to avoid overwhelming the service.
However, there are a couple of challenges that make this task harder:
- Google anti-scraping mechanisms: Being part of Google services, Google Jobs has advanced bot detection systems that can quickly pick when a human makes a request. This can include CAPTCHA challenges and rate limiting, to mention a few.
- JavaSscript rendering: If you inspect the website, you’ll notice that the data you see on your screen is not actually contained in the site’s HTML. Instead, it is dynamically injected via JavaScript. This adds another layer of complexity, forcing us to find a way to render the page before being able to access any data.
- Infinite scrolling: Connected to the previous challenges, new Google Jobs listings are only loaded to the page when scrolling to the bottom. In other words, we also need to interact with the page if we want to collect a significant amount of data.
- Geo-specific data: Although it is not a challenge per se, Google Jobs shows different results based on your IP location. If you want, for example, to scrape data from the US but are based in Italy like me, you’ll need to find a way to change your IP location (geotargeting).
To overcome these challenges – and any other blocker in our way – I’ll use ScraperAPI to:
- Access a pool of +40M proxies across +50 countries
- Automatically rotate my proxies to ensure a high success rate
- Turn raw Google Jobs HTML data into structured JSON data
Scraping Google Jobs with Python and ScraperAPI
ScraperAPI offers a simple-to-use Google Jobs endpoint to collect job listings for any query we need without building any complex infrastructure or using a headless browser.
By sending our requests through the endpoint, ScraperAPI will handle JS rendering, CAPTCHA handling, and proxy rotation for us and return job data in JSON format, saving us development hours, data parsing, and cleaning.
For this example project, let’s collect data for the query “video editor”.
Google Jobs Layout Overview
If you navigate to Google and search for video editor jobs, you’ll find yourself on a page similar to this one:
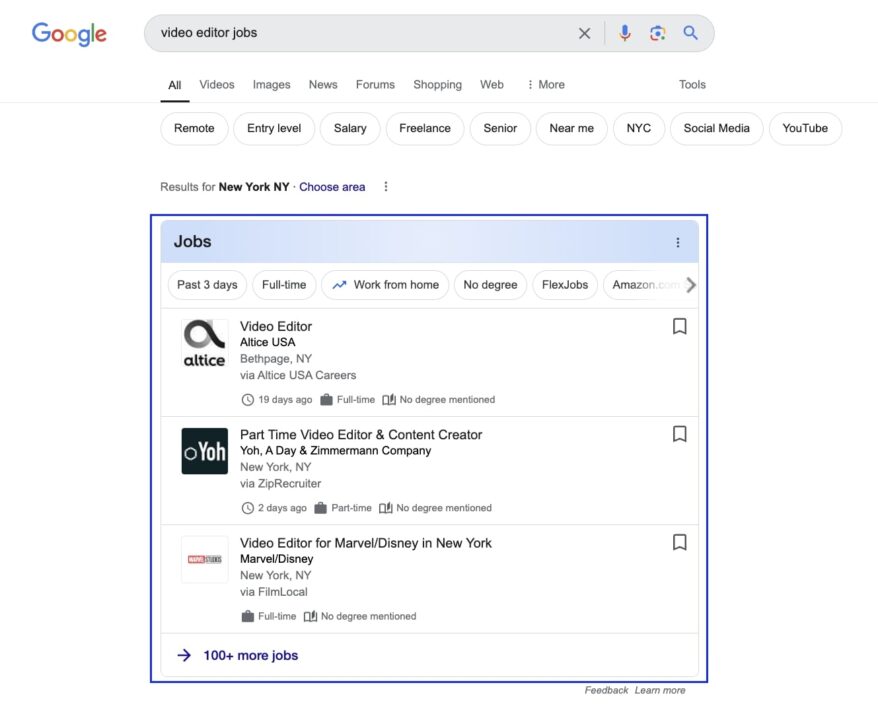
Clicking on the box will lead you to the main Google Jobs interface. All job listings are listed on the left, and more details are shown on the right.
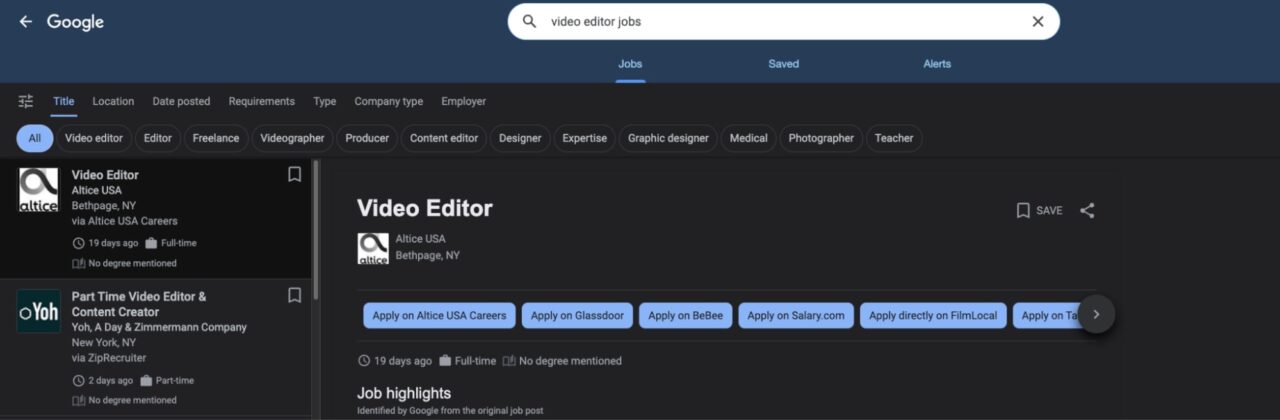
From here, we can access some basic information on the left card, like job title, company offering the position, job location, and extra details, such as how long the job opportunity was posted and salary.
Of course, we can get even more data from the job listing itself, although the most relevant element would be the job description on the right, which will give us all the context we need from the job opportunity.
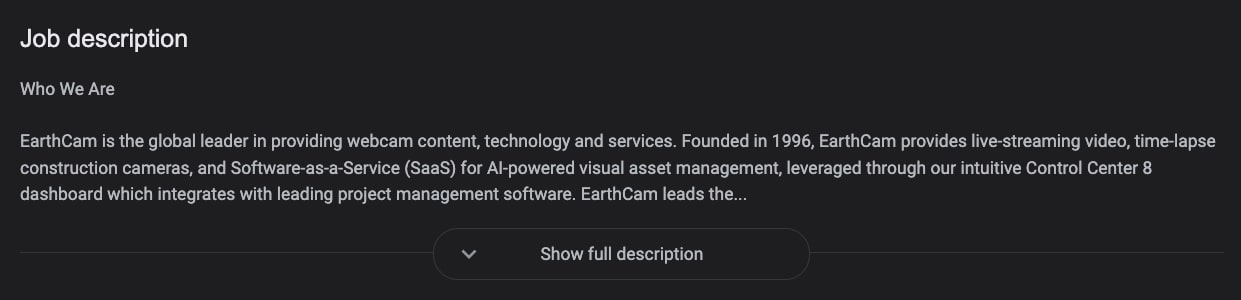
Also, you have to remember that all of this information is dynamically injected into the page through JavaScript, so a regular script won’t be able to see the page as we do, and even after rendering, we still need to perform certain actions to get the full picture.
A good example is the job description above. To be able to collect the entire job description, we would need to click on the Show full description button.
However, by using ScraperAPI’s Google Jobs endpoint, we’ll be able to get the:
- Job listing URL
- Company name
- Job title
- Description
And additional details without performing any page interactions – so no headless browser or complex workaround.
Most importantly, you won’t need to maintain your parsers, as the ScraperAPI dev team will ensure your scrapers keep running by monitoring Google Jobs site changes and quickly adapting to new layouts and challenges.
Project requirements
Before we start writing our script, ensure you have Python and the Requests library installed on your machine.
To install Requests, use the following command:
pip install requests
You’ll also need to create a free ScraperAPI account to get access to your API key – which you can access from your dashboard.
That’s it, we’re now ready to get started!
Step 1: Setting up your Google Jobs scraping project
First, create a new directory for your project and a new Python file inside. I’ll call it google-jobs-scraper.py.
At the top of the file, import requests and json. We’ll use the latter to export our data.
import requests
import json
The Google jobs endpoint works by passing your API key, the query you want data for, and the country from which you’d like your requests to come. We’ll pass all of this information in a payload.
payload = {
'api_key': 'YOUR_API_KEY',
'query': 'video editor',
'country_code': 'us'
}
Note: Add your real API key to the api_key parameter before running your script.
I also set our proxies to the US to get US-based job listings. Otherwise, ScraperAPI could use proxies from different countries, messing with the accuracy of our data. If location isn’t important to you, ignore this suggestion.
To control geolocation even more, you can also target a specific Google TLD using the tld parameter like so:
payload = {
'api_key': 'YOUR_API_KEY',
'query': 'video editor',
'country_code': 'us',
'tld': '.com'
}
This is especially useful if you want to see how the search results change with different combinations, like using UK proxies but targeting Google’s .com TLD.
If not set, ScraperAPI will target the .com TLD by default.
Step 2: Send a get() request to the Google Jobs endpoint
Now that the payload is ready, send a get() request to the endpoint, passing the payload as params.
response = requests.get('https://api.scraperapi.com/structured/google/jobs', params=payload)
ScraperAPI will use your query to perform the search on Google Jobs, render the page, and return all relevant data points in JSON format.
Step 3: Export All Job Listings Into a JSON File
Because the endpoint returns a JSON response, we can store the data in an all_jobs variable and then export it into a file using the dump() method from json.
all_jobs = response.json()
with open('google-jobs', 'w') as f:
json.dump(all_jobs, f)
Here’s what you’ll get:
{
"url": "https://www.google.com/search?ibp=htl;jobs&q=video+editor&gl=US&hl=en&uule=w+CAIQICIgSHViZXIgSGVpZ2h0cyxPaGlvLFVuaXRlZCBTdGF0ZXM=",
"scraper_name": "google-jobs",
"jobs_results": [
{
"title": "Freelance Video Editor for Long Form Video",
"company_name": "Upwork",
"location": "Anywhere",
"link": "https://www.google.com/search?ibp=htl;jobs&q=video+editor[TRUNCATED]",
"via": "Upwork",
"description": "We are looking for a talented freelance video editor to work on a long form style video. [TRUNCATED]",
"extensions": [
"Posted 16 hours ago",
"Work from home",
"Employment Type Contractor and Temp work",
"Qualification No degree mentioned"
]
}, //TRUNCATED
Note: See what a full Google Jobs response looks like.
Step 3.2: Export Google Job Listings as CSV
The Google Jobs endpoint also takes care of transforming the scraped data into tabular data, making it super simple to export job listings into a CSV file.
First, let’s set the output parameter to csv in our payload:
payload = {
'api_key': credentials.api_key,
'query': 'video editor',
'country_code': 'us',
'tld': '.com',
'output_format': 'csv'
}
Note: If the output_format is not set, the endpoint defaults to JSON format.
Then, we can create the CSV file using the text from the response:
response = requests.get('https://api.scraperapi.com/structured/google/jobs', params=payload)
if response.status_code == 200:
filename = 'jobs_data.csv'
# Save the response content to a CSV file
with open(filename, 'w', newline='', encoding='utf-8') as file:
file.write(response.text)
print(f"Data saved to {filename}")
else:
print(f"Error {response.status_code}: {response.text}")
Here’s how your file will look like:
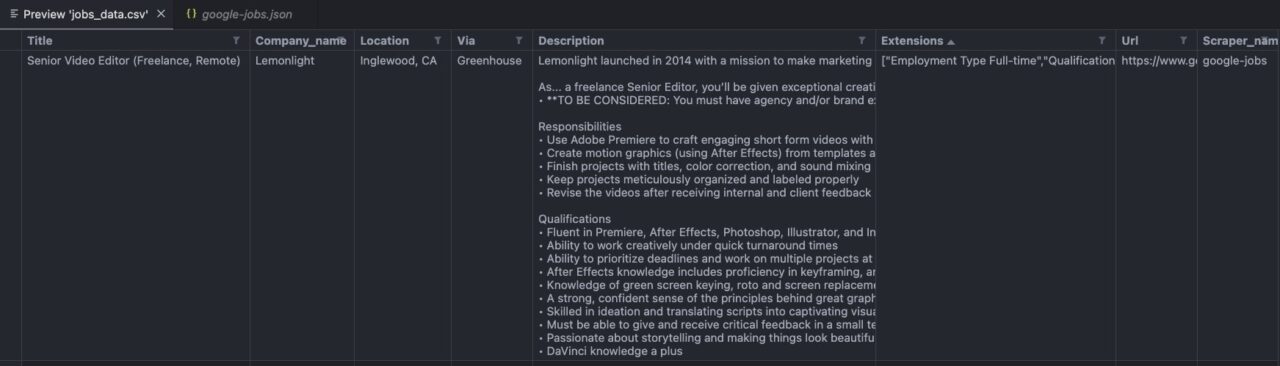
Note: The image above is from my VScode editor preview.