



Ruby is an open-source programming language with an elegant and easy-to-read syntax – very close to human-like language. It has gained popularity for building MVPs thanks to the Rails framework.
Because it’s such a great technology to pick up, we want to close our beginner web scraping series with an introduction to Ruby web scraping using HTTParty and Nokogiri.
Note: More advanced tools like Kimurai will be covered later on but we want to keep it simple at this time.
This tutorial is aimed at beginners that wants are just getting started in the web scraping world and would like to be able to extract data from static pages.
In today’s example, we’ll build a Ruby scraper step by step to extract product names, prices, and links from a NewChic clothing category. Feel free to follow along to get the most out of this tutorial.
1. Installing Ruby, HTTParty and Nokogiri
The first thing we’ll need to do is to install all the necessary tools we’ll be using to build our scraper. If you’re on Mac, you should already have a version of Ruby installed on your computer.
Go to your terminal and type ruby -v and it’ll show you which version you have installed.
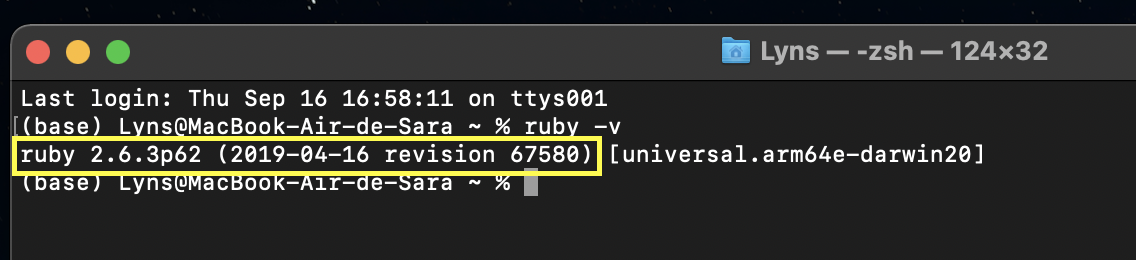
If you’re on Windows and you don’t have any version of Ruby installed on your machine, use the Ruby installer and follow the instructions.
Once you’re done with Ruby, setting up your development environment will be much easier.
Create a new directory for the project
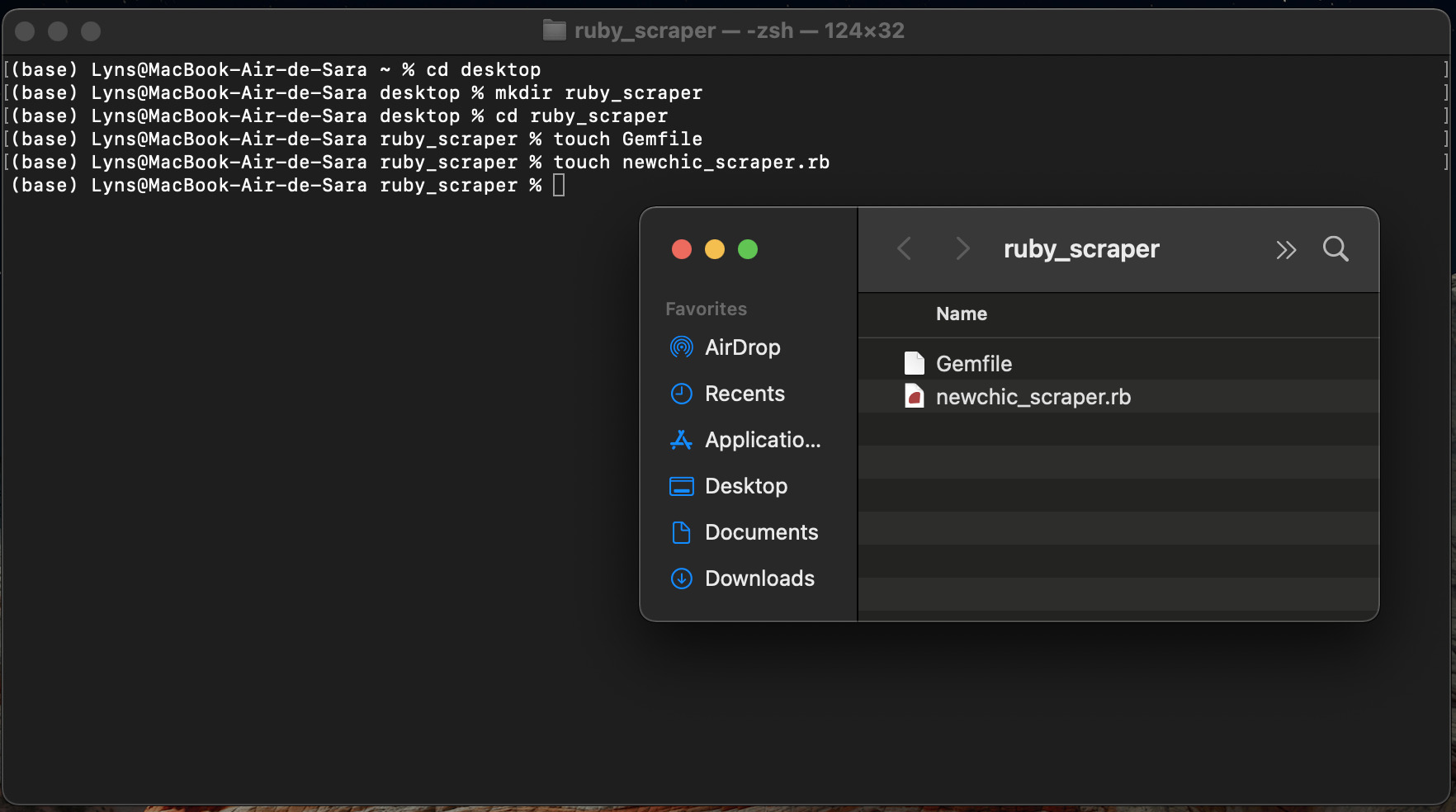
Jump again to your terminal and navigate to your desktop (cd desktop). Then, enter mkdir ruby_scraper to create a new folder for the project.
Inside, we’ll create two files:
- A gem file: touch Gemfile
- Our scraper file: touch newchic_scraper.r
Install HTTParty and Nokogiri
Open your project folder with your preferred text editor. In our cases, we’ll open our folder in VScode and then jump to Gemfile.
In there we’ll add the following code:
</p>
source "https://rubygems.org/"
gem 'httparty'
gem 'nokogiri'
gem 'byebug'
<p>Back in our terminal, we’ll enter bundle install and it will automatically fetch these three gems and add them to our project, creating a Gemfile.lock file inside the directory. In addition to the gems we’ve already mentioned, we added the Byebug gem for debugging purposes.
Now that our environment is setup, it is a good time to navigate to our target page and get familiar with its structure.
2. Understanding Page Structure for Web Scraping
Before we start writing our script, it’s important to know what we are looking for and where. If we understand the website structure of our target page, it will make it way easier to write a logic that’ll bring the results we want.
As you might already know, websites are built using two fundamental blocks, HTML and CSS. These are the two elements we’ll use to write our scraper.
HyperText Markup Language (HTML) is used to describe to web browsers how to display a website. It structures all the content on the site using tags to describe every element.
Let’s take a look at the HTML of the men’s hoodies category page by right clicking on it and hitting inspect.
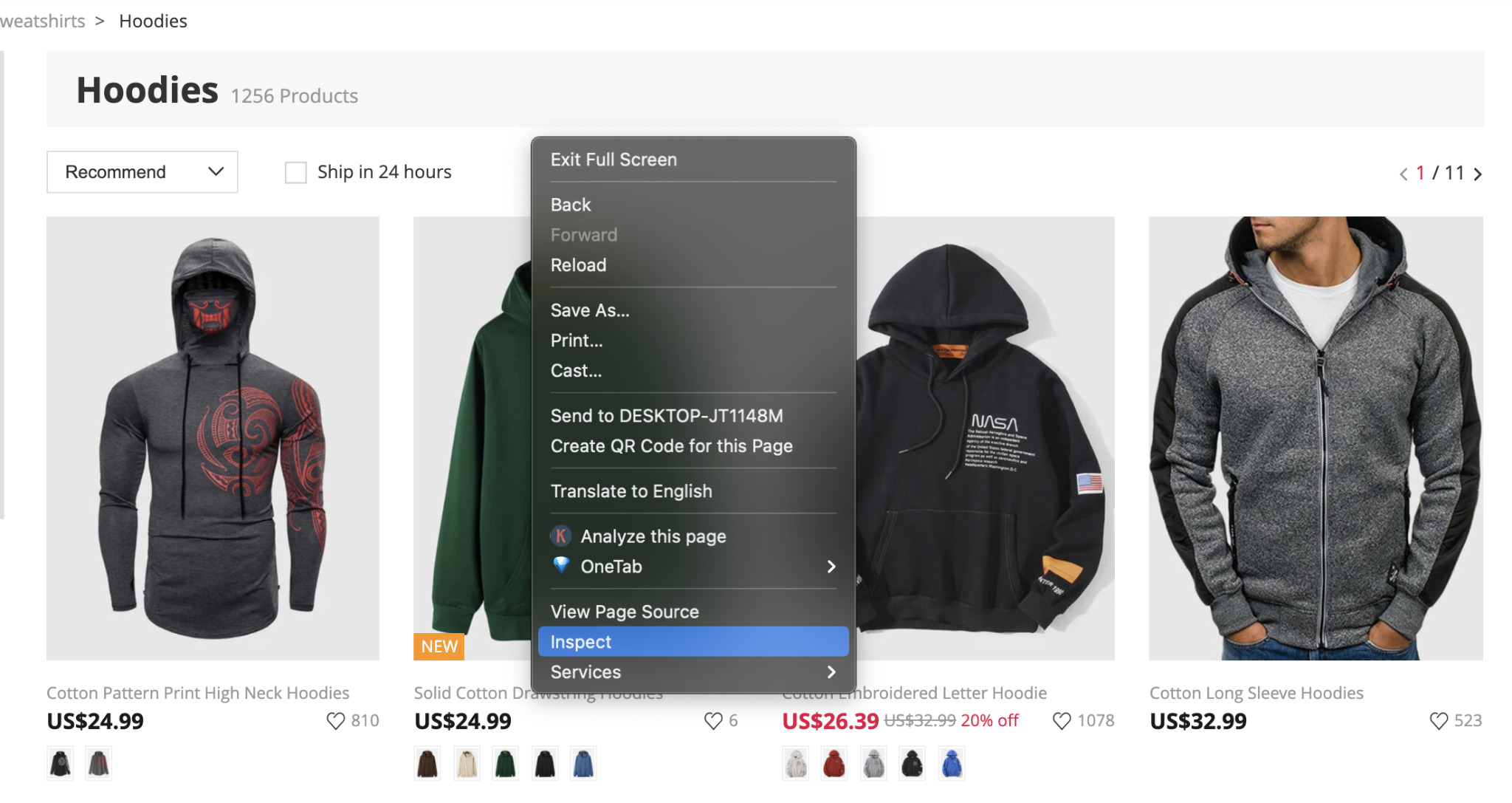
It will open the developers tool and show us the HTML file.
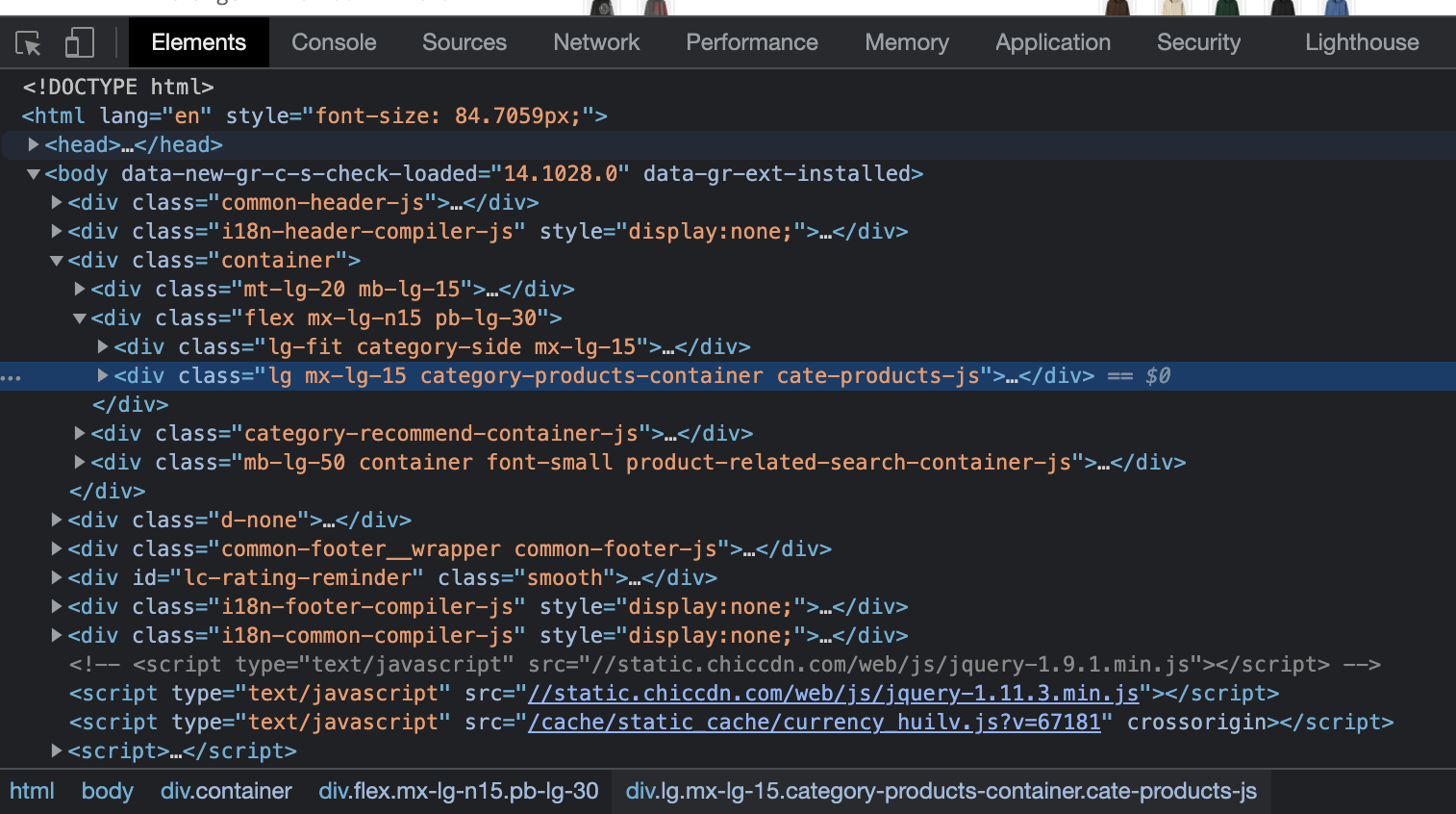
If we use this tool to inspect the main title of the page, we’ll be able to see how it is served in the HTML.
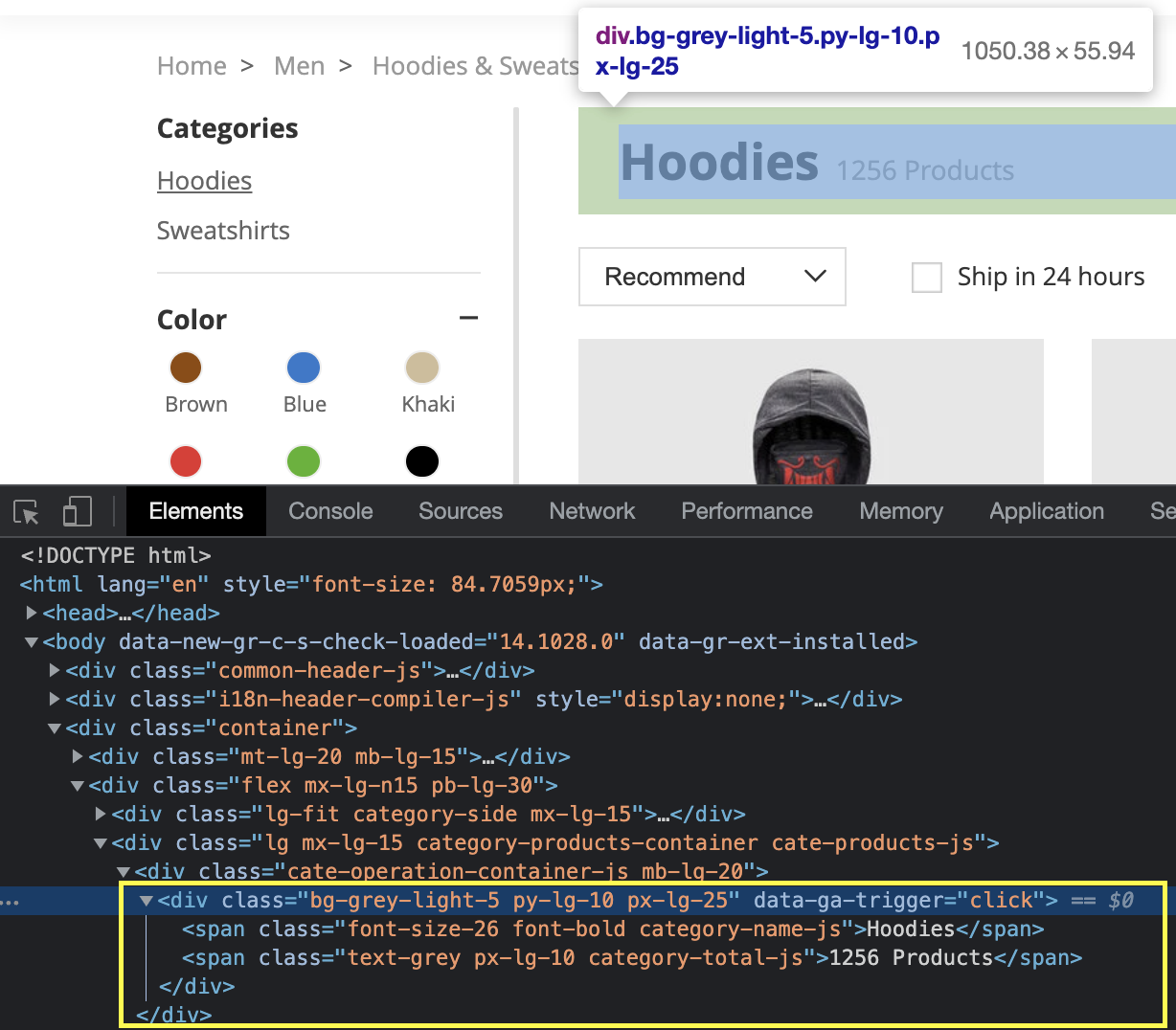
The title ‘Hoodies” is wrapped inside a <span> HTML tag inside a <div>. However, you might have noticed something else: a class attribute.
The ID and class attributes are used to identify an element within the HTML document so it can then be selected when applying styles, implementing JavaScript, etc.
Cascading Style Sheets (CSS) is language used to describe (style) elements within a markup language like HTML. In other words, it tells the browser how each element described in the HTML document should look like in terms of color, size, position and more, by selecting the class or ID of the elements..
To make it easier, let’s take a look at the CSS styling our title:
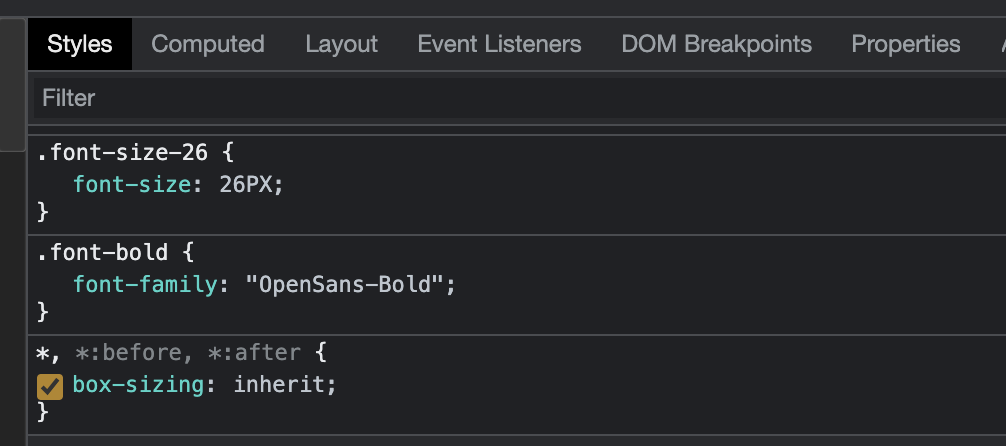
The <span> element wrapping the title has several classes, but in this example we can see that the Newchic team is using the classes ‘font-size-26’ and ‘font-bold’ to select the element and adding the style.
Alright, but why is this all important? Because we can use the exact selectors to tell our scraper which elements to bring back and where to find them.
3. Picking Our CSS Selectors
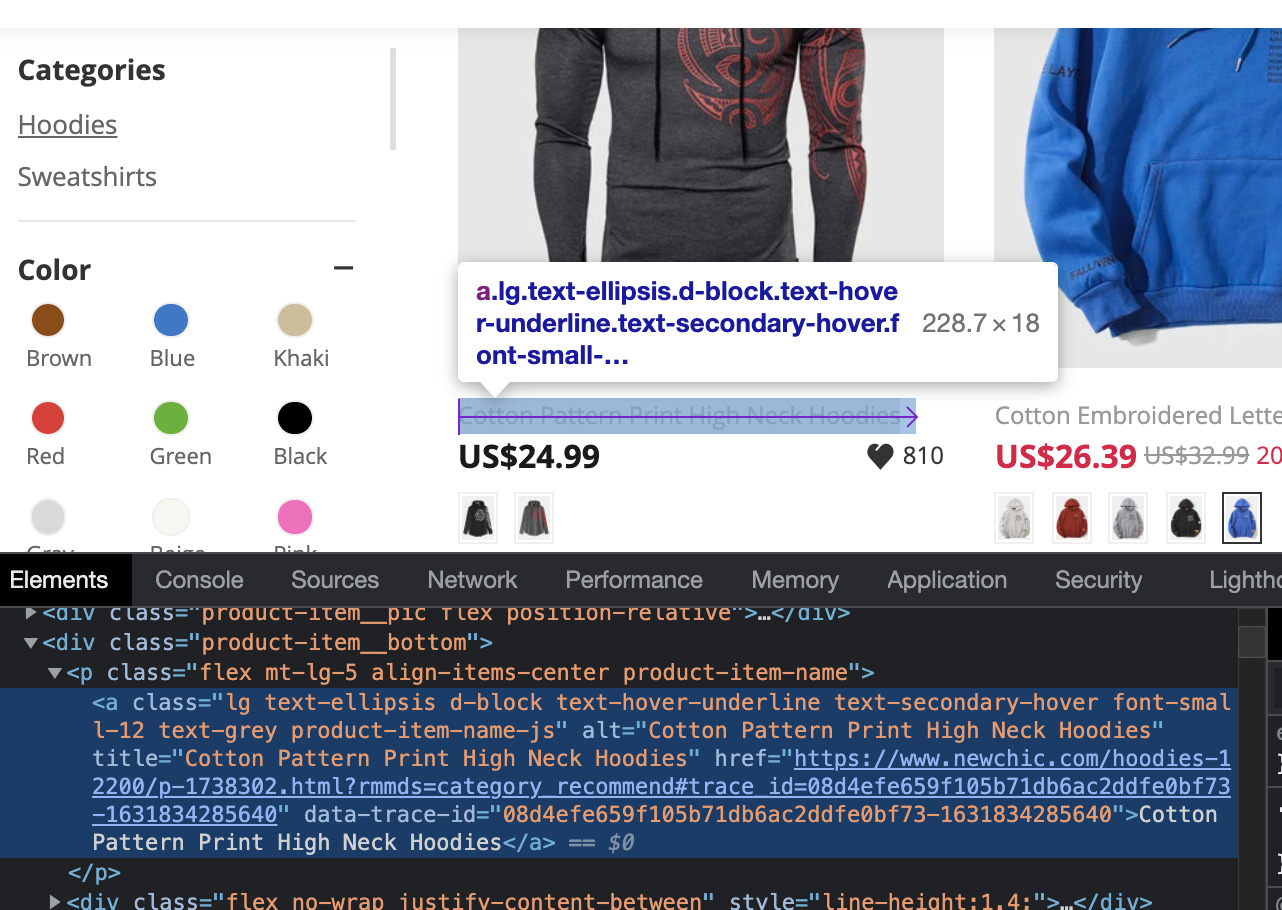
With that in mind, we can find the right CSS selector in two ways. We can either inspect the elements we want to scrape and take a look at the HTML element in the developers tool panel:
Or we can use a tool like SelectorGadget to help us pick the best.
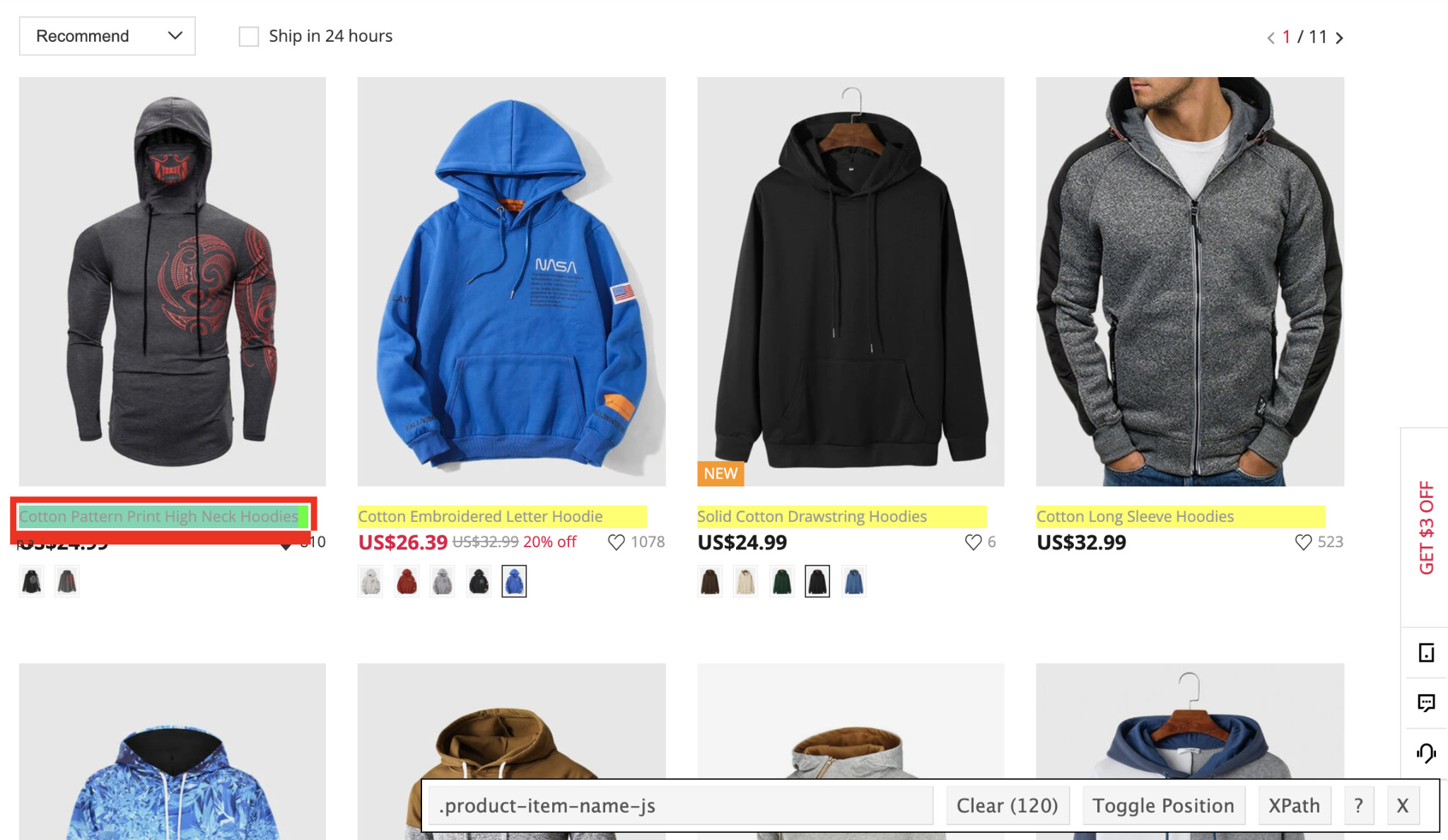
When we click on an element, SelectorGadget will highlight all similar elements and display a class on the bar. We can then click on any highlighted element we don’t want until all the elements we’ll be scraping are on the only ones in yellow.
So it seem that for the product name we can use the class ‘product-item-name-js’. Also, as we inspected the element before we can tell that the link to the product is also inside this tag, so we’ll use the same selector for that too.
For the price we’ll use the class 'product-price-js':
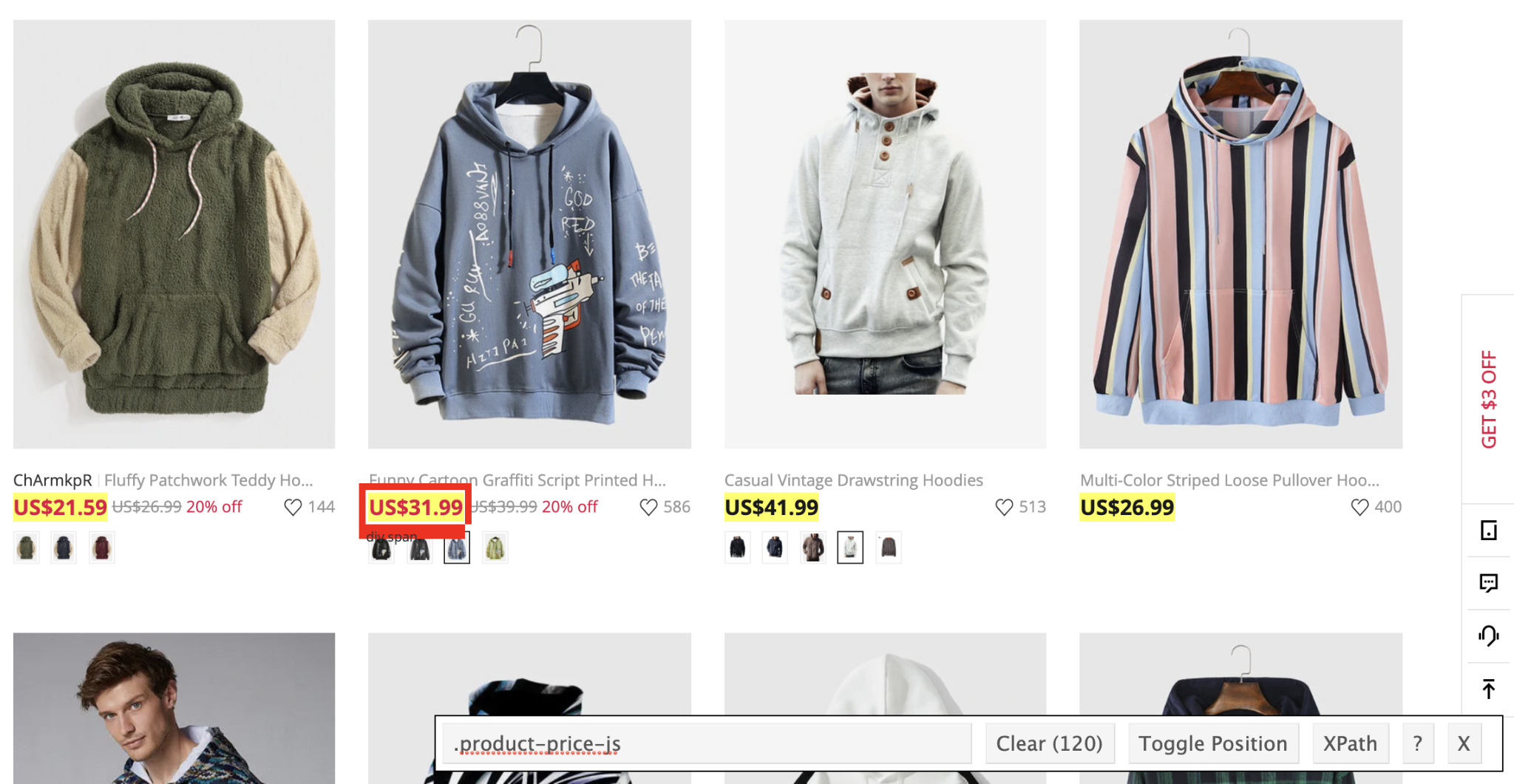
We had to select and deselect a few because the price tag is using similar classes to those of navigation links. Also, the price with discount has different classes as well (we also know is the correct one as it has 120 elements selected just like the product name class).
Always make sure you’re picking a class representing all the elements you want to scrape without mixing it with other elements.
Great! We have our target, let’s get some code into our newchic_scraper.rg file.
4. Sending an HTTP Request and Parsing the HTML
First things first. We’ll need to download the HTML file in order to parse it. For that we’ll be using HTTParty.
Let’s start by adding our dependencies to the top of our scraper file:
</p>
require 'nokogiri'
require 'httparty'
require 'byebug'
<p>Next, let’s define a new method called scraper and send the HTTP request:
</p>
def scraper
url = "https://www.newchic.com/hoodies-c-12200/1.html?newhead=0&mg_id=2&from=nav&country=223&NA=1"
unparsed_html = HTTParty.get(url)
page = Nokogiri::HTML(unparsed_html)
end
<p>A few things are happening here. First, we added the target URL to a url variable and then pass it to HTTParty to send the HTTP request. As a response, the server will send us the raw HTML file and store it in the unparsed_html variable.
However, we can’t parse this file just yet. First, we need to send the unparsed_html to Nokogiri who will create a snapshot of the HTML in the form of a series nested nodes, which we’ll be able to navigate using the CSS selectors we identified in the previous step.
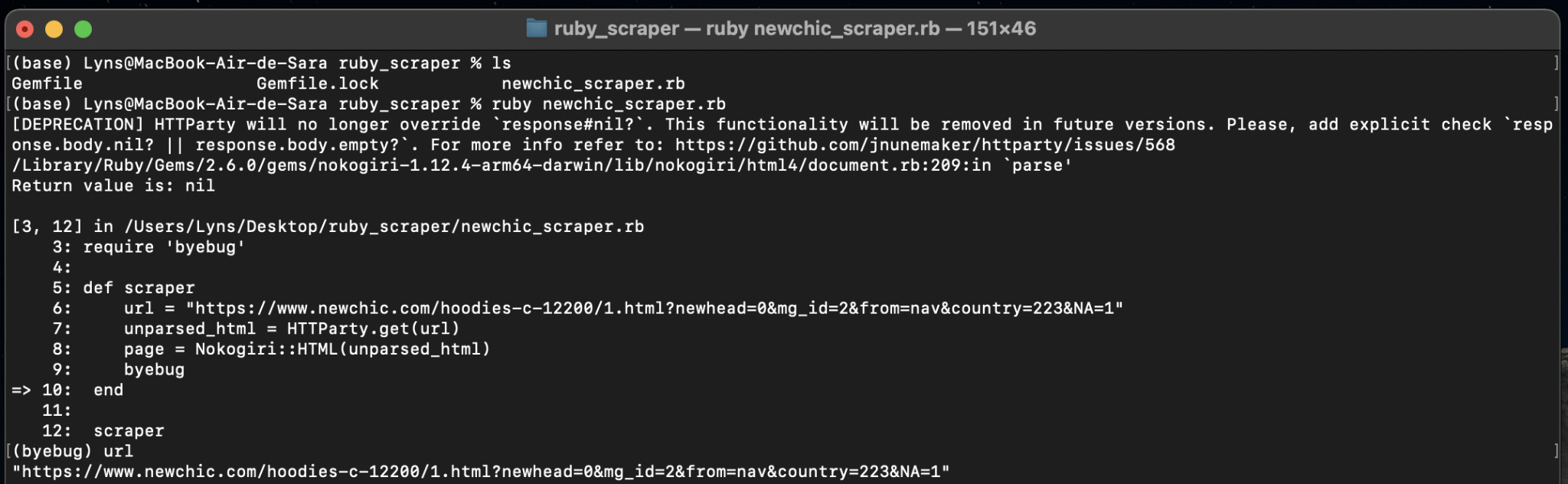
So let’s test this request using Byebug. Just add byebug after the page variable and scraper outside of our method.
Then, we’ll run our scraper from the terminal (ruby newchic_scraper.rb). This command will run our script and once it hits the byebug, it will let us interact with our variables. This is a great way to make sure we’re extracting the right data.
If you now enter any of the variable, you’ll be able to visualize what data has been stored in them.
5. Building a Ruby Parser Using CSS Selectors in Nokogiri
Now that the response is set to Nokogiri, we can use CSS selectors to navigate the nodes and select everything need.
Before jumping into the file, let’s use our console to test some of the CSS selectors we picked and see what they return.
Testing Our CSS Selectors Within the Console

First, let’s assign all titles to a variable using hoodies-names = page.css(‘a.product-item-name-js’) in our terminal. Then, we’ll enter hoodies-names.count and we should be returning 120 products.
Oops! What happened there? We had selected 120 product names but we’re now down to 60.
Well, this is actually happening because the first request only loads 60 products and the page inject the other 60 after scrolling down – which is a behavior our current scraper isn’t able to mimic.
Let’s take a look at our target URL:
</p>
https://www.newchic.com/hoodies-c-12200/1.html?newhead=0&mg_id=2&from=nav&country=223&NA=1
<p>But if we go to this category directly from the browser, the url would look more like this:
</p>
https://www.newchic.com/hoodies-c-12200/?newhead=0&mg_id=2&from=nav&country=223&NA=1
<p>In other words, every product page is stored in a different HTML file and then dynamically display to the user.
We discovered this by playing around with the top navigation.
Instead of going from page 1 to page 2, the navigation actually jumps some HTML documents because in a single page, two HTML documents are being displayed.
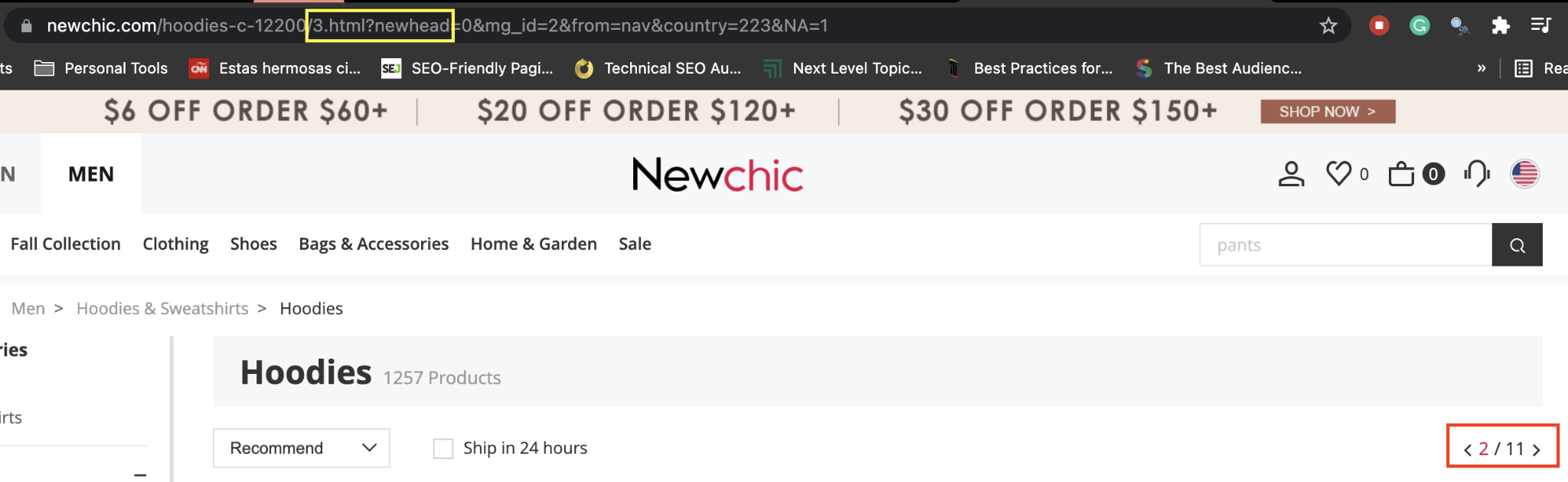
In other words, the first page displayed on the browser is showing 1.html and 2.html files, but the second file only triggers after the user scrolls down.
Knowing that we can target each HTML file individually instead of the page displayed for users. So 60 products stored in the hoodiesNames variable is actually correct!
For further testing, type hoodiesNames.first to log the first item stored in the variable into the console.

Perfect, it seems like it’s working properly. Time to move on!
Writing Our Parser in the newchic_scraper.rb File
Just like we did above, we’ll want to add a new variable containing all 60 products listings. However, we want to get the element wrapping all the data we want.
Using SelectorGadget, we can see that every product listing is a <div> element with the class ‘mb-lg-32’.
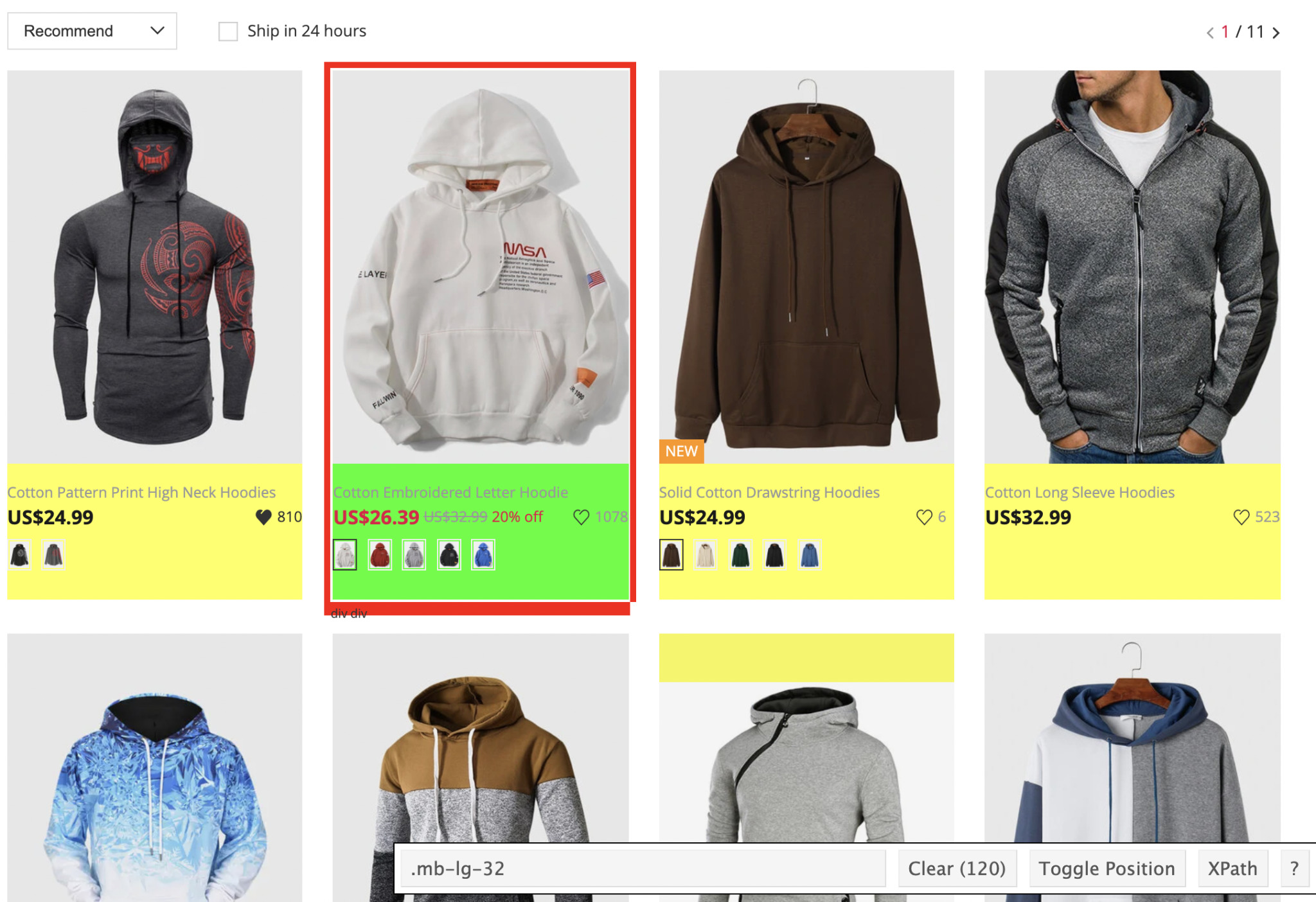
So that’s the first element we want to target, to then iterate through every product and extract the name, price, and link.
</p>
require 'httparty'
require 'nokogiri'
require 'byebug'def scraper
url = "https://www.newchic.com/hoodies-c-12200/1.html?newhead=0&mg_id=2&from=nav&country=223&NA=1"
unparsed_html = HTTParty.get(url)
page = Nokogiri::HTML(unparsed_html)
product_listings = page.css('div.mb-lg-32')
product_listings.each do |product_listing|
product = {
title: product_listing.css('a.product-item-name-js').text,
price: product_listing.css('span.product-price-js').text,
link: product_listing.css('a')[0].attributes["href"].value
}
byebug
end
endscraper
<p>A few things here:
- When we test our CSS selectors in the console, it logs all the HTML code within the selected node. To only grab the text (which is all we need for the name and price) we used .text at the end of the string.
- We also added the HTML tag to make it easier for our scraper to find the objects and not get confused in any way.
- For the link we don’t really want the text (which is the same as the title), so we want our scraper to access the value inside the href attribute instead.
- We moved the Byebug to our iterator to debug it.
Back to our console, let’s continue through the Byebug so we get back to our project directory. There, we’ll run our script once more, and what we have now is a product object with all the data we’re trying to extract.
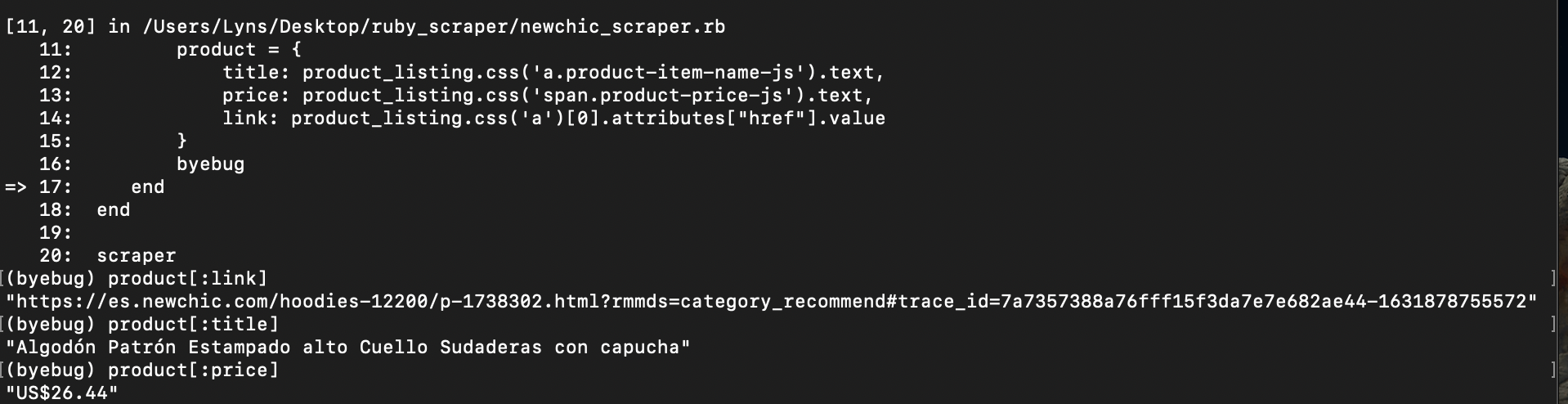
Enter exit, so we don’t iterate over the 60 products right now, and let’s keep working on our scraper.
The next thing we want is to store all this data into an array to give it some structure or order, and make it easier to work with.
After the page variable, add products = Array.new and then replace the byebug line with products << product to push every listing to the array, and place the byebug outside the iterator for debugging.
If it’s working properly, our products variable should now contain 60 products and each one should have the title, price and link.
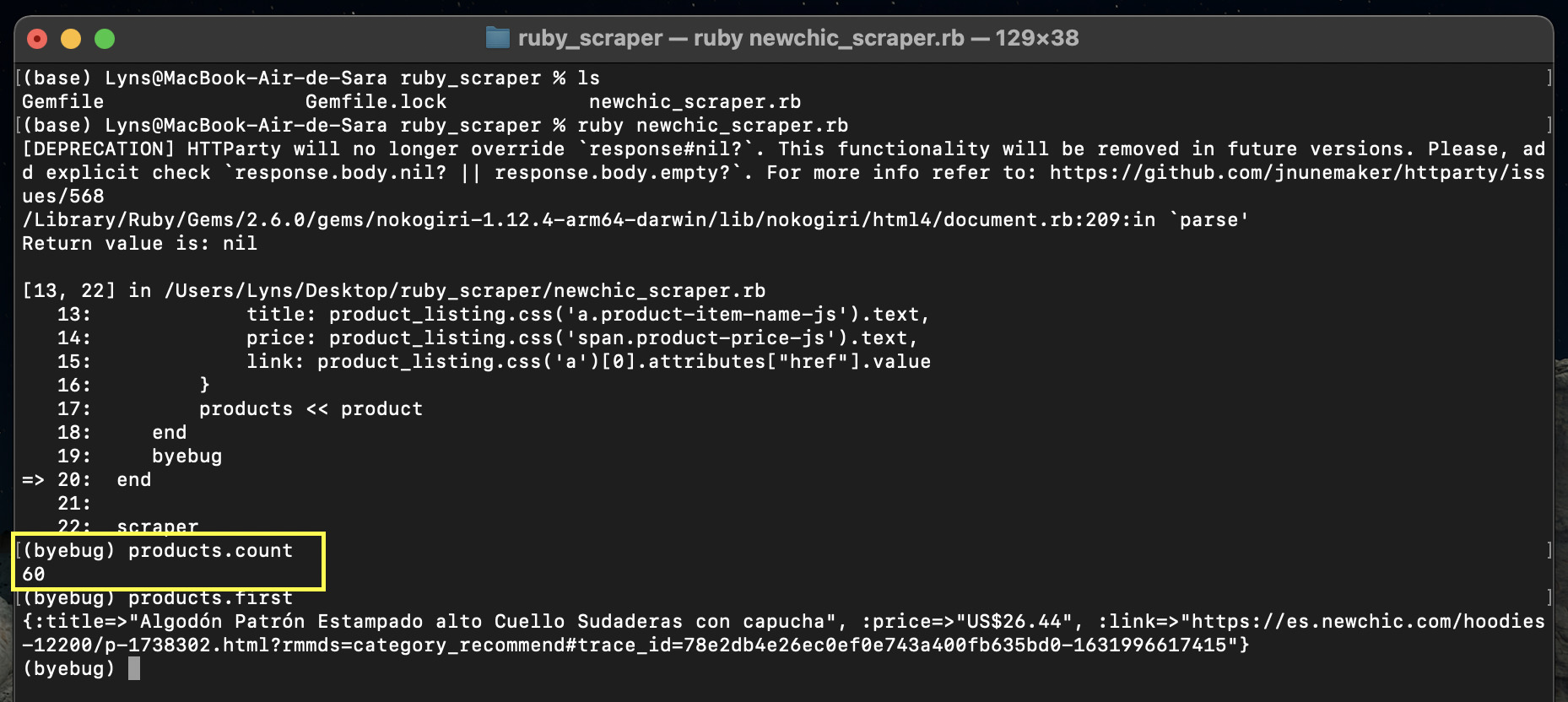
Awesome! We’ve scraped all 60 products listed on our target page.
With this same process you can scrape almost any page you like on the internet (at least static pages). However, we can take it a little bit further.
Let’s make our Nokogiri scraper navigate to other pages and collect the rest of the products data from this category.
6. Scraping Multiple Pages with Ruby
Alright, so now that our scraper is extracting the desired, we can use the URL logic Newchic uses to our advantage.
Because of the constrains of this article, we found a quick – but rather hacky – solution, but that’ll work great for this website in particular, and will save us some time.
Setting Our Entry and End Point
First, create a new variable called per_page to store the right amount of products our bot will find in each page. We already know it’s 60 but what if this changes in the future, we don’t want to limit this, so instead, we’ll do it like this: per_page = product_listings.count.
Note: remember that our variable product_listings is pulling all product cards on the page.
The next variable will be total and it will tell our scraper how many products are on the site in total which is 1050 products.
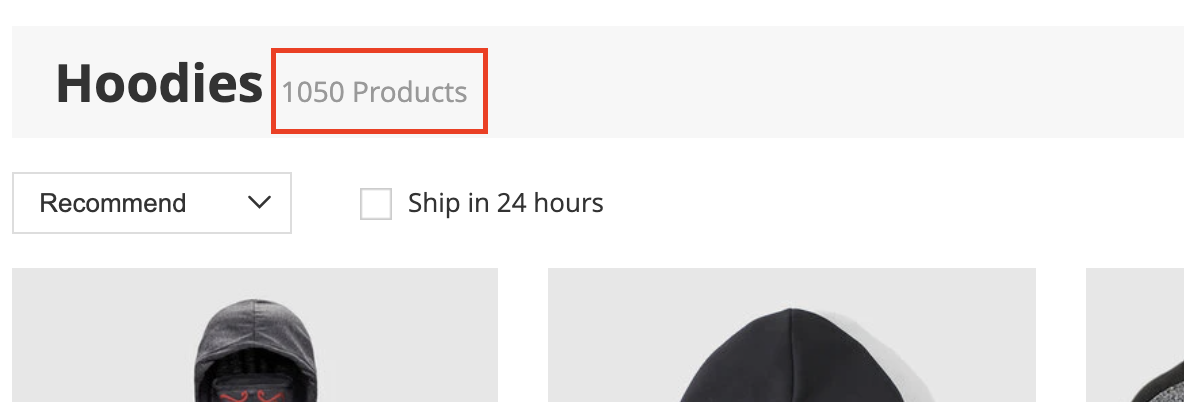
Let’s also add a variable with the starting navigation page which is 1 (from 1.html), as we’ll be using this variable to change the URL.
However, the last thing we want is to have our scraper going to the site infinitely, so we need to create an end point in the form of last_navigation = 17. Which is the last HTML file on the category.
Of course, this isn’t the only way we could build a crawler-like feature for our scraper.
For example, we hard coded the total number of products and the last_navigation end point. However, we could build each one adopting a more flexible logic.
For example, we could access the total number of products on the top. The problem is that the <div> wrapping that data is only trigger by clicking:
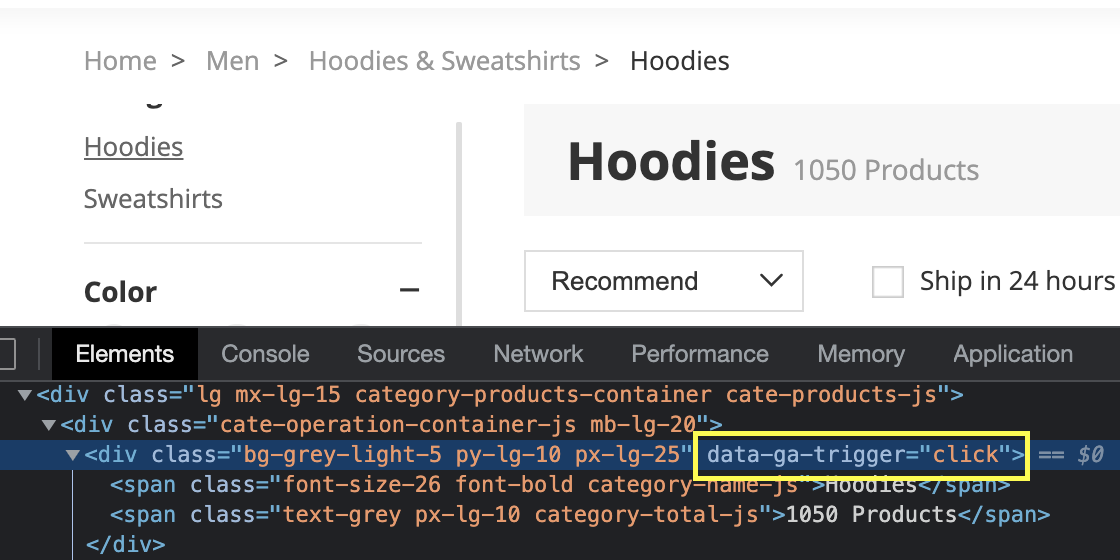
Trying to extract this data with our current scraper will only bring an empty string as our script is not actually interacting with the page. To do so, we would have to use another tool.
We’re telling you this not to discourage you but to open your mind to the possibilities!
Wrapping the Iterator in a While Loop
At this point, you’ve probably realized how easy to read Ruby is. Instead of explaining every little detail for the while loop, read the last version of the code to figure out what we changed and why:
</p>
require 'httparty'
require 'nokogiri'
require 'byebug'
def scraper
url = "https://www.newchic.com/hoodies-c-12200/?newhead=0&mg_id=2&from=nav&country=223&NA=0"
unparsed_html = HTTParty.get(url)
page = Nokogiri::HTML(unparsed_html)
products = Array.new
product_listings = page.css('div.mb-lg-32')
navigation = 1
per_page = product_listings.count
total = 1050
last_navigation = 17
while navigation <= last_navigation
navigation_url = "ttps://www.newchic.com/hoodies-c-12200/{navigation}.html?newhead=0&mg_id=2&from=nav&country=223&NA=1"
navigation_unparsed_html = HTTParty.get(navigation_url)
navigation_page = Nokogiri::HTML(navigation_unparsed_html)
navigation_product_listings = navigation_page.css('div.mb-lg-32')
navigation_product_listings.each do |product_listing|
product = {
title: product_listing.css('a.product-item-name-js').text,
price: product_listing.css('span.product-price-js').text,
link: product_listing.css('a')[0].attributes["href"].value
}
products < product
end
navigation += 1
end
byebug
end
scraper
<p>If we run this, our Ruby scraper will extract 60 products per page, then increment by 1 the number in the URL and access the next page to do the same process until it hits our last_navigation page.
Note: we could also add some puts inside the code to see what’s going on in our console to make sure it’s working correctly.
7. Integrating Ruby Web Scraping with ScraperAPI for Scalability
We’ve done great work so far, and we hope you’re understanding every bit of code we’ve written today. Nonetheless, there are a few problems we need to overcome.
We only scraped seventeen pages from Newchic which is a rather small project.
But if we try to scale our scraper and get into more pages, it won’t take too long for the server to realize it’s our scraper who’s accessing the page and not a human. Once it happens, the server will block our IP address and prevent any request to get through.
To workaround this, we would have to code an IP rotation function (to change our IP address after every request), set timeouts to slow down the number of requests per second and minute, potentially coding a solution to handle CAPTCHAs and more.
In fact, we’re sending our requests from a Latinamerican IP address, so all the results we’re getting are in spanish.
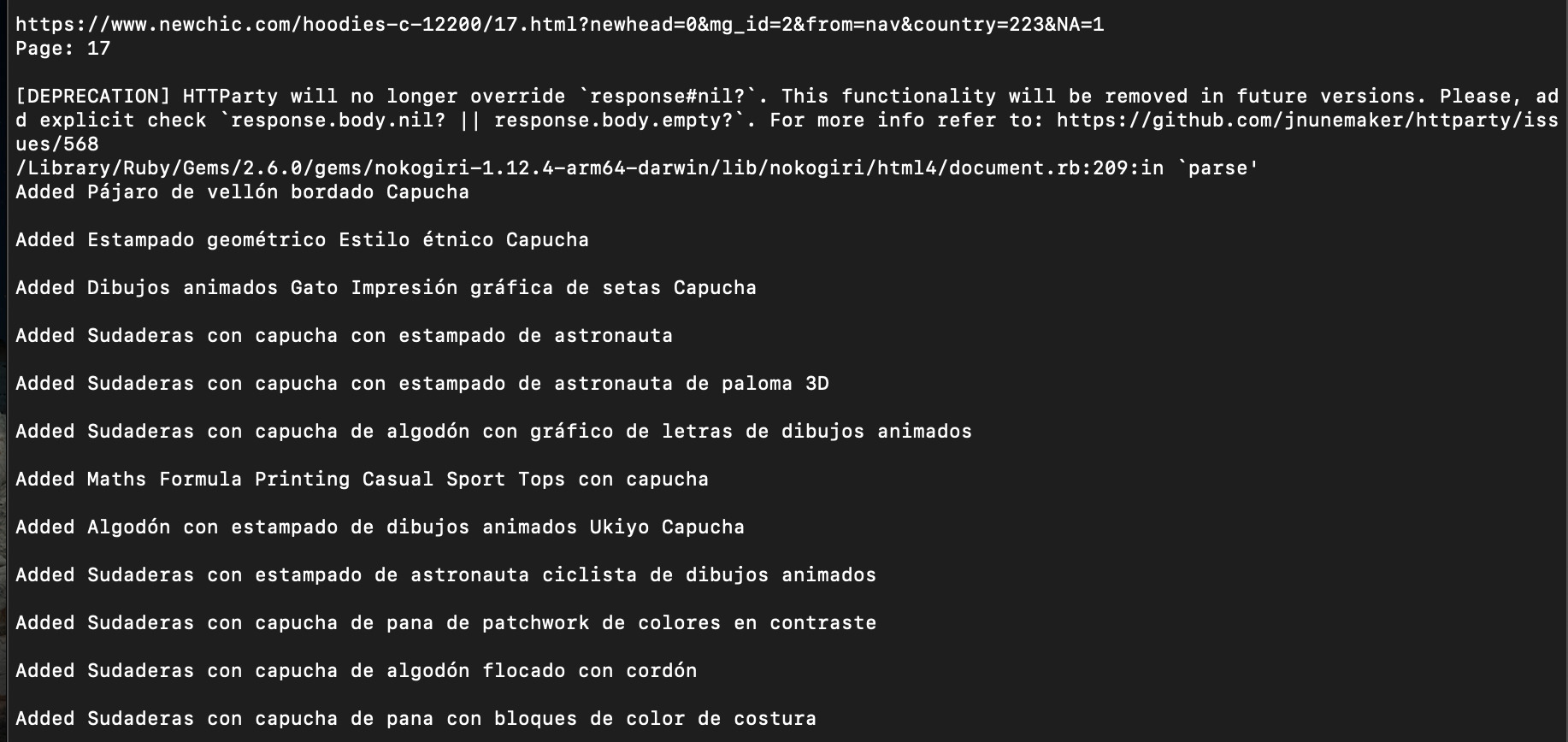
If you’re trying to collect data on pages that changes depending on geolocalization, you’ll have to look for that as well.
That’s exactly what ScraperAPI is built for. It uses 3rd party proxies, machine learning and years of statistical analysis to make your scraper virtually undetectable.
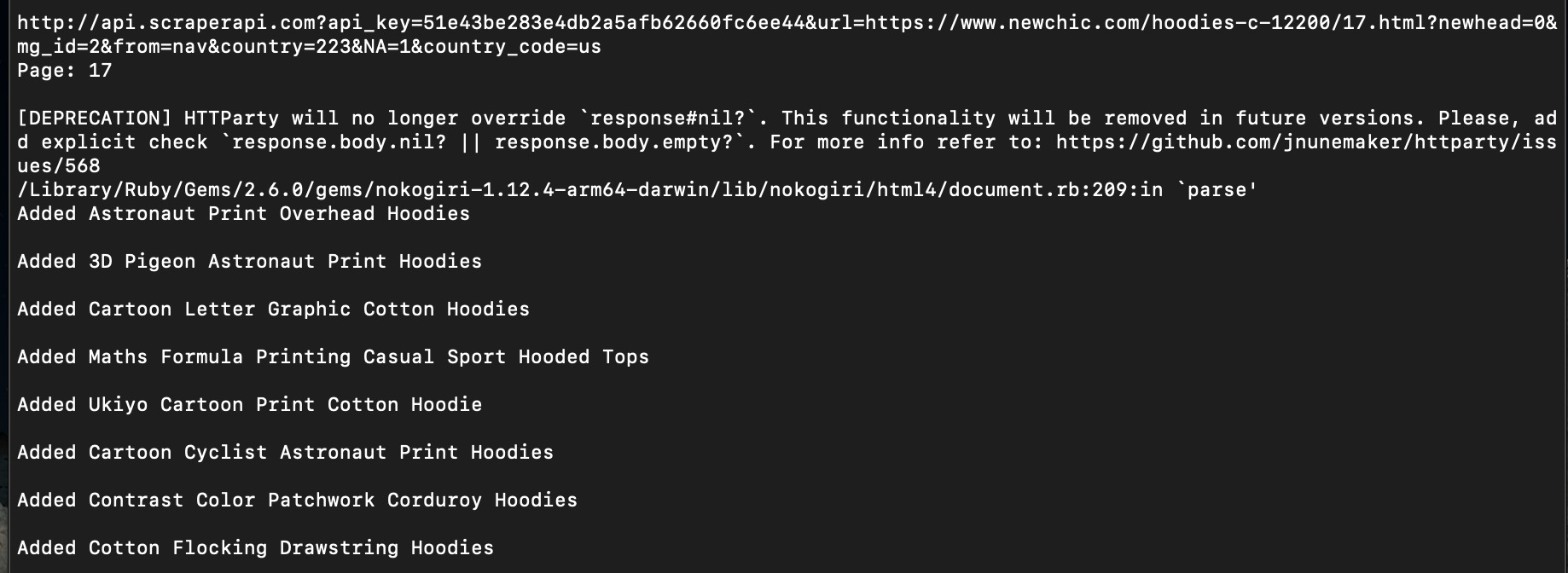
All we need to do is send our request through ScraperAPI and set a few parameters to tell ScraperAPI what we need it.
</p>
http://api.scraperapi.com?api_key={API_key}&url=https://www.newchic.com/hoodies-c-12200/{navigation}.html?newhead=0&mg_id=2&from=nav&country=223&NA=1&country_code=us
<p>In white you can see the new lines we added to the navigation_url value, and just with that we’ve added better functionalities to our scraper without extra code or work.
To get your API Key, just sign up for a free ScraperAPI account. You’ll receive 5000 free API credits and all pro features for a week (then you’ll enjoy 1000 free credits per month).
In your dashboard you’ll find your API Key, code snippets to copy and paste into your project, and your monthly calls report.
You’ll also find out everything you can do with ScraperAPI in our extensive documentation.
Wrapping Up and Other Web Scraping Resources
We hope you enjoyed this beginner Ruby web scraping tutorial. It was a blast to write!
Web scraping is all about practicing. Every website is a different puzzle that requires thinking out of the box. Reading and building projects is the best way to learn and master this craft.
To help you with this, here are the best resources on web scraping for beginners:
- 5 Tips For Building Large Scale Web Scrapers
- The Ultimate CSS Selectors Cheat Sheet for Web Scraping
- Web Scraping in C#: Building Your First C-Sharp Scraper from Scratch
- How To Scrape Amazon Product Data
- Web Scraping in R: How to Use Rvest for Scraping Data
Happy scraping!





