



Project 1: Scraping iTunes’ Popular Podcasts with Emails
Objective: Find the most popular podcasts and get the hosts’ contact email.
In this example, we combine classical web scraping with a REST API and a feed parser. Let’s start with some ideas and research.
First, we need to find a list of the most popular podcasts. As iTunes (Apple Podcasts) is still considered the canonical go-to place for podcasts, we start here.
We notice that each category (and sub-category) has its own list of popular podcasts. Each is linked to the details page of a podcast. Unfortunately, the details page does not contain the host’s email address. However, we have the iTunes ID of each podcast and can query the iTunes lookup API to get the feed URL.
Note: Feeds are a structured way to provide content in a machine-readable format. They are often used for news, blogs, and podcasts. The most common feed format is RSS (Really Simple Syndication).
Inside the feed, we find the publisher’s email address. Our retrieval strategy, therefore, goes as follows:
1. Compile a list of popular podcasts by category from the iTunes website
We find a link to each category on the overview page of Apple Podcasts.
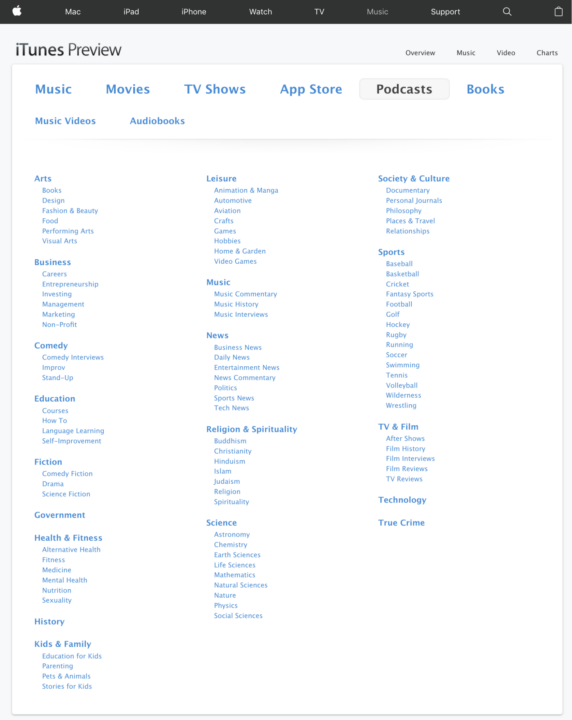
There is a list of popular podcasts for each category.
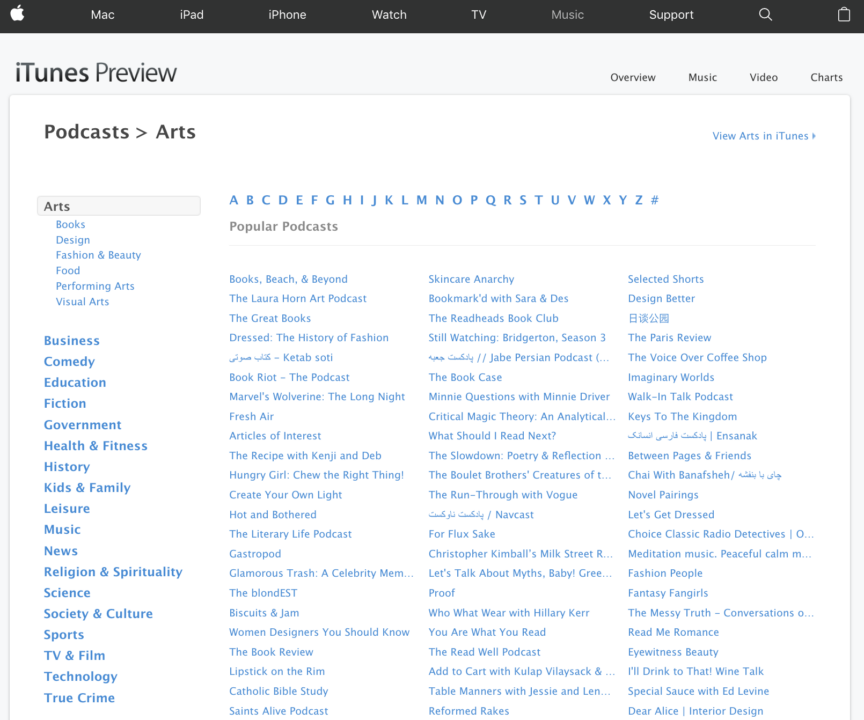
Unfortunately, the email address is not available on the details page. We can, however, get the iTunes ID from the URL.
2. Look up the feed URL via the iTunes lookup API
Apple provides an API to look up podcasts using their iTunes ID. We can use this API to get the podcast feed URL.
3. Get the publisher’s email from the feed
The feed is the machine-readable version of the podcast. It contains the podcast episodes and metadata. We can extract the publisher’s email from the feed.
Put together, the spider looks like this:
<pre class="wp-block-syntaxhighlighter-code">
import feedparser
import scrapy
class ItunespopularwithemailsSpider(scrapy.Spider):
name = "ItunesPopularWithEmails"
start_urls = ["https://podcasts.apple.com/us/genre/podcasts/id26"]
def parse(self, response):
category_links = response.css("div#genre-nav a::attr(href)").getall()
for category_link in category_links:
yield scrapy.Request(
category_link,
callback=self.parse_category,
)
def parse_category(self, response):
breadcrumbs = response.css("div#title h1 ul.breadcrumb li a::text").getall()
for a in response.css("div#selectedcontent a"):
id = a.css("::attr(href)").get().split("/")[-1].replace("id", "")
yield response.follow(
f"https://itunes.apple.com/lookup?id={id}",
self.parse_api,
)
def parse_api(self, response):
data = response.json()
result = data.get("results")[0]
yield response.follow(result.get("feedUrl"), self.parse_feed)
def parse_feed(self, response):
feed = feedparser.parse(response.text)
try:
email = feed.feed.publisher_detail.email
except:
email = None
if email:
yield {
"email": email,
"feed": response.url,
}</pre
>
Project 2: Scraping Amazon RAM Prices
Objective: Get a list of the 10 most popular RAM kits with 32GB and their prices from Amazon.
Amazon is a popular online marketplace where you can buy almost anything. In this example, we want to get the prices of the most popular RAM kits with 32GB.
You may want to collect a time series of prices to analyze the price development over time. Alternatively, you might choose a different product category or search term to conduct a competitive analysis if you sell similar products.
We start by searching for ram 32gb on Amazon. Just use your browser to search for the term and copy the URL.
Our scraper looks like this:
<pre class="wp-block-syntaxhighlighter-code">
import scrapy
API_KEY = '...'
class EconomicsamazonrampriceswithscrapingapiSpider(scrapy.Spider):
name = "EconomicsAmazonRAMPricesWithScrapingAPI"
allowed_domains = ["amazon.com", "www.amazon.com"]
start_urls = ["https://www.amazon.com/s?k=ram+32gb&"]
def start_requests(self):
meta = { "proxy": f"http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001" }
for start_url in self.start_urls:
yield scrapy.Request(start_url, callback=self.parse, meta=meta)
def parse(self, response):
items = response.xpath('//div[@data-asin]')
for item in items:
asin = item.xpath('@data-asin').extract_first()
if not asin:
continue
price = item.xpath('.//span[@class="a-price"]/span/text()').extract_first()
price = price.replace("$", "")
price = float(price)
if not price:
continue
yield {
"asin": asin,
"title": item.xpath('.//h2/a/span/text()').extract_first(),
"price": price,
}</pre
>
💡 Pro Tip
You can simplify this process using ScraperAPI’s Amazon Search endpoint. By sending your request through the API, alongside your search query, ScraperAPI will return all Amazon search results in JSON or CSV format.
Project 3: Scraping Public Holidays
Objective: Get a list of public holidays in the United States, Great Britain, Germany, France, Italy and the Netherlands.
This is a special one. Sometimes, you might have a special request like a list of public holidays, a list of international dialing codes, or a list of countries with their capitals.
For these kinds of things, GitHub is your friend. There are many repositories that contain this kind of data. In this example, I’ve found a repository that contains a list of public holidays for many countries. The data is available publicly, not only on GitHub, and can be accessed via a simple API.
Here is our spider code:
<pre class="wp-block-syntaxhighlighter-code">
import csv
import datetime
import io
import scrapy
class PublicholidaysSpider(scrapy.Spider):
name = "PublicHolidays"
allowed_domains = ["date.nager.at"]
countries = ["US", "GB", "DE", "FR", "ES", "IT", "NL"]
start_year = 2020
def start_requests(self):
current_year = datetime.datetime.now().year
for country in self.countries:
for year in range(self.start_year, current_year + 1):
url = f"https://date.nager.at/PublicHoliday/Country/{country}/{year}/CSV"
yield scrapy.Request(url, self.parse, cb_kwargs={"country": country, "year": year})
def parse(self, response, year = None, country = None):
csv_file = io.StringIO(response.text)
reader = csv.DictReader(csv_file)
for row in reader:
row["year"] = year
row["country"] = country
yield row</pre
>
Project 4: Scraping NBA.com
Fun time! Now, let’s scrape the NBA website. We want to get a list of all players based on their weight and height. This is a good example of how to scrape a website with JavaScript-rendered content.
We start by visiting the NBA website and inspecting the page. We see that the player data is loaded dynamically with JavaScript.
Our scraper will use Playwright to interact with the website and get the player data.
<pre class="wp-block-syntaxhighlighter-code">
import scrapy
class ExamplesnbaspiderSpider(scrapy.Spider):
name = "ExamplesNBASpider"
allowed_domains = ["www.nba.com"]
start_urls = ["https://www.nba.com/stats/teams"]
custom_settings = {
"CONCURRENT_REQUESTS": 50,
"PLAYWRIGHT_BROWSER_TYPE": "chromium",
"DOWNLOAD_HANDLERS": {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"headless": False,
"timeout": 20 * 1000, # 20 seconds
},
"PLAYWRIGHT_DEFAULT_NAVIGATION_TIMEOUT": 10 * 1000,
}
def start_requests(self):
for start_url in self.start_urls:
yield scrapy.Request(
url=start_url,
meta={
"playwright": True,
"playwright_include_page": True,
},
)
async def parse(self, response):
page = response.meta['playwright_page']
team_links = response.css("a[class*='StatsTeamsList_teamLink__']")
for i, team_link in enumerate(team_links):
yield scrapy.Request(
url=response.urljoin(team_link.attrib.get("href")),
callback=self.parse_team_page,
meta={
"playwright": True,
"playwright_include_page": True,
},
)
await page.close()
async def parse_team_page(self, response):
page = response.meta['playwright_page']
team_name = response.css("div[class*='TeamHeader_name__']")
team_name_text = "".join(team_name.css("*::text").getall())
yield {"t": "team_page", "url": response.url}
# Crom_table__p1iZz
table = response.css("table[class*='Crom_table__']").css("tbody")
for row in table.css("tr"):
columns = row.css("td")
yield {
"team": team_name_text,
"player_name": columns[0].css("::text").get(),
"player": columns[1].css("::text").get(),
"position": columns[2].css("::text").get(),
"height": columns[3].css("::text").get(),
"weight": columns[4].css("::text").get(),
"birthdate": columns[5].css("::text").get(),
}
await page.close()</pre
>
Scaling our Web Scraping Projects with ScraperAPI
ScraperAPI is a service that provides scalable infrastructure and advanced solutions for professional scraping projects.
Using an external service for scraping projects comes with several advantages:
1. Circumvent scraping limits
Using a (rotating) proxy can help circumvent limits imposed by sites you scrape. Such limits include geo-blocking, rate limits, or unusual behavior (bot) detection. An external service like ScraperAPI offers a wide range of proxies located anywhere in the world, some even with IP addresses from dial-up ranges so that they look like real human visitors.
2. Automate JavaScript handling
When dealing with client-side generated JavaScript-heavy pages, we can use tools like Playwright, as seen in this mini-guides examples section. With ScraperAPI, you can forget about dealing with resource-heavy browser setups on your end. You can simply send a URL to the API and get JSON back.
3. Automatic Data Extraction
One of the most powerful features of ScraperAPI is the ability to query common ecommerce, jobs, and even search engine result pages like a REST API. Instead of parsing the HTML directly, ScraperAPI does it for you when using its structured data endpoints.
Promo Code
As a reader of this MiniGuide, you’ll get 10% off their usual prices using the code BAS10 when signing up for a plan.
ScraperAPI Code Examples
Example 1: ScraperAPI Amazon SDE
Product data from Amazon can be retrieved from the Structured Data Endpoint (“SDE”) of ScraperAPI.
Following that approach, there is no need to inspect the Amazon product page's HTML structure and handle bot prevention systems or markup changes manually.
<pre class="wp-block-syntaxhighlighter-code">
import requests
product_data = []
payload = {
'api_key': '<YOUR API KEY>',
'asin': 'B09R93MDJX'
}
response = requests.get('https://api.scraperapi.com/structured/amazon/product', params=payload)
product = response.json()
product_data.append({
"product_name": product["name"],
"product_price": product["pricing"],
"product_ASIN": product["product_information"]["asin"]
})
print(product_data)</pre
>
Example 2: JS Rendering
Similar to the Structured Data Endpoint, ScraperAPI also offers a JavaScript Rendering endpoint. This endpoint is useful when the website you want to scrape uses JavaScript to render its content.
Using this endpoint, you can get the rendered HTML of the website just as you would see it using Playwright.
<pre class="wp-block-syntaxhighlighter-code">
import requests
payload = {'api_key': 'APIKEY', 'url':'https://httpbin.org/ip', 'render': 'true'}
r = requests.get('https://api.scraperapi.com', params=payload)
print(r.text)
# Scrapy users can simply replace the urls in their start_urls and parse function
# ...other scrapy setup code
start_urls = ['https://api.scraperapi.com?api_key=APIKEY&url=' + url + '&render=true']
def parse(self, response):
# ...your parsing logic here
yield scrapy.Request('https://api.scraperapi.com/?api_key=APIKEY&url=' + url + '&render=true', self.parse</pre
>




