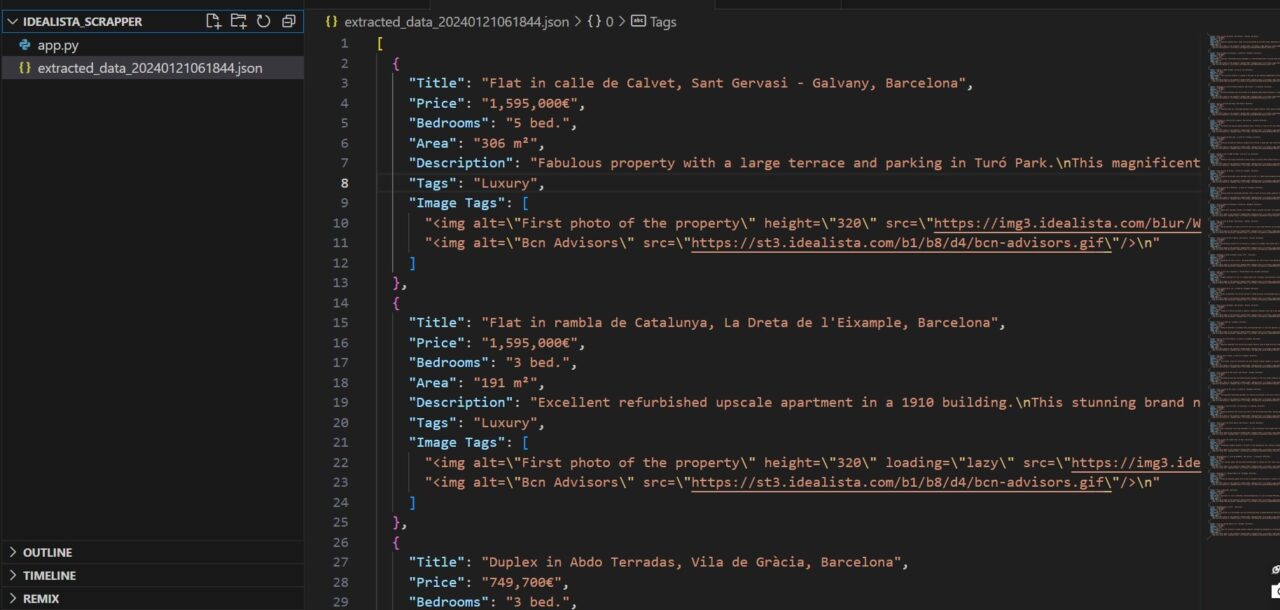
After running the code, you should have the data dumped in the extracted_data(datetime).json file.
The image below shows how your extracted_data(datetime).json file should look like.
You are now ready to go on to the next steps!
Understanding Idealists’s Website Layout
To understand the Idealista website, inspect it to see all the HTML elements and CSS properties.
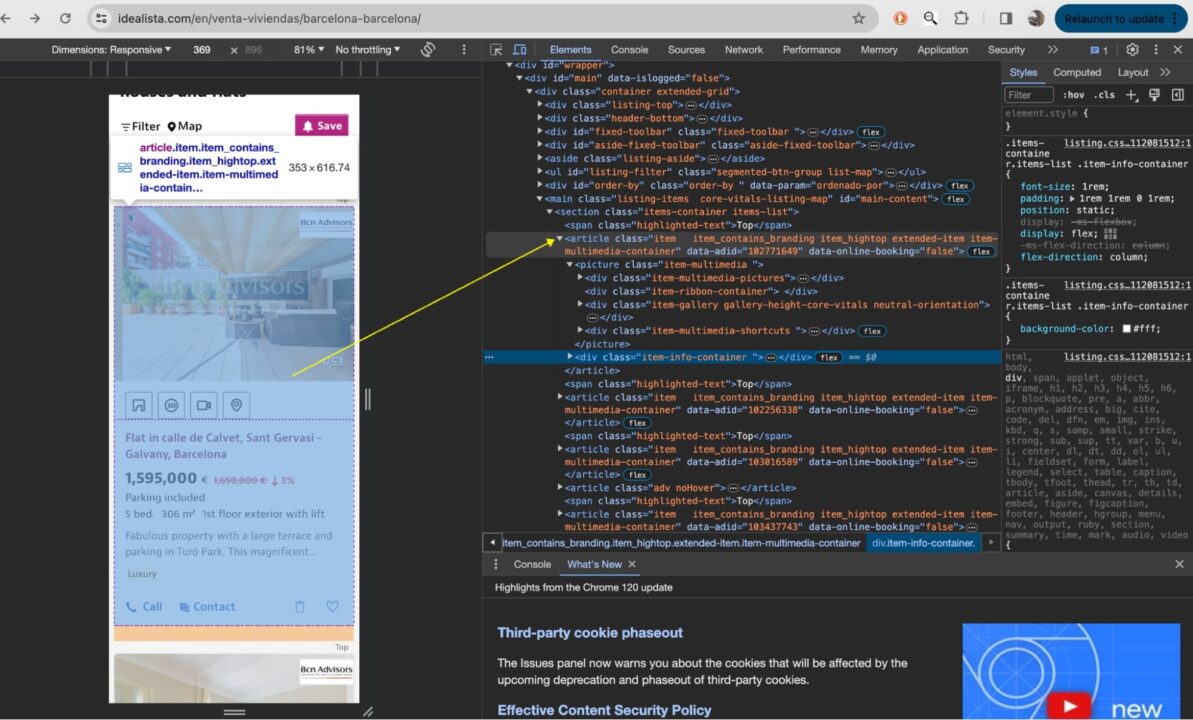
The HTML structure shows that each listing is wrapped in an <article> element. This is what we’ll target to get the listings from Idealista.
The <article> element contains all the property features we need. You can expand the entire structure fully to see them.
Using ScraperAPI
Idealista is known for blocking scrapers from its website, making collecting data at any meaningful scale challenging. For that reason, we’ll be sending our get() requests through ScraperAPI, effectively bypassing Idealista’s anti-scraping mechanisms without complicated workarounds.
To get started, create a free ScraperAPI account to access your API key.
In the code above, we checked if the HTTP response status code is 200, indicating a successful request.
If successful, it parses the HTML content of the Idealista webpage and extracts individual house listings by finding all HTML elements with the tag <article> and class 'item'. These represent individual house listings on the Idealista webpage.
The script then iterates through each listing and extracts its details.
The extracted information for each listing is stored in dictionaries, which are appended to a list called extracted_data.
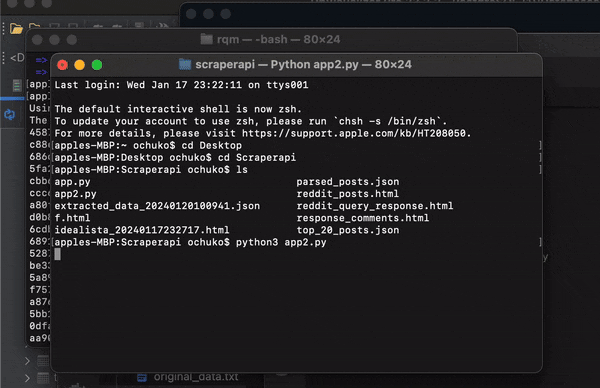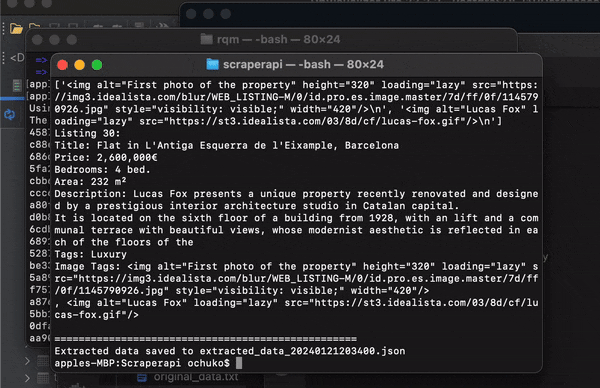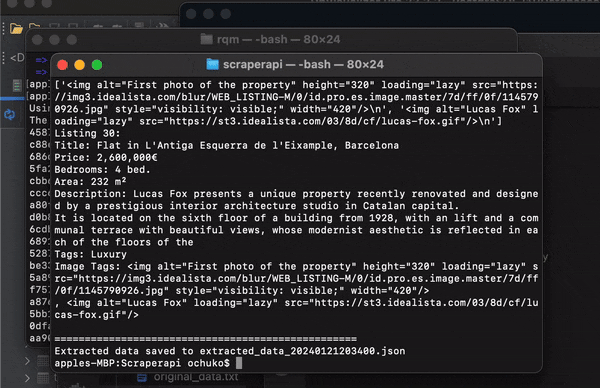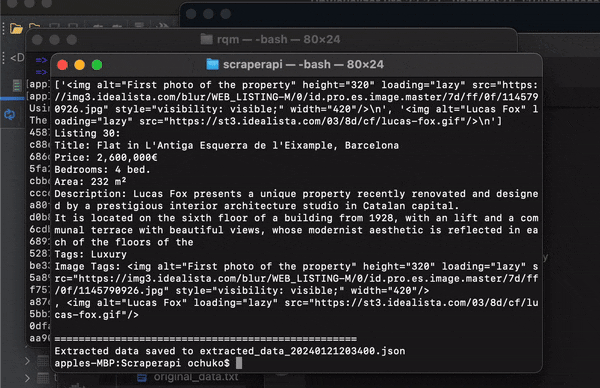
The script prints the extracted information for each listing to the console, displaying details like:
- Title
- Price
- Bedrooms
- Area
- Description
- Tags
- Image tags
Step 5: Exporting Idealista Properties Into a JSON File
Now that you have extracted all the data you need, it is time to save them to a JSON file for easy usability.