



In this web scraping tutorial, we’ll show you how to collect product reviews from G2 without getting detected or blacklisted. The extracted G2 review data includes the review’s dates, URLs, ratings, and user information (username).
TL;DR of Full Python Code on G2 Software Product Review Scraper
For those in a hurry, here’s the full Python script for the web scraper we’re making in this tutorial:
import requests
from bs4 import BeautifulSoup
import json
API_KEY = "Your_API_Key"
url = "https://www.g2.com/products/scraper-api/reviews"
payload = {"api_key": API_KEY, "url": url}
html = requests.get("https://api.scraperapi.com", params=payload)
soup = BeautifulSoup(html.text, "lxml")
# Initialize the results dictionary
results = {"product_name": "", "number_of_reviews": "", "reviews": []}
# Extracting the product name
product_name_element = soup.select_one(".product-head__title a")
results["product_name"] = (
product_name_element.get_text(strip=True)
if product_name_element
else "Product name not found"
)
# Extracting the number of reviews
reviews_element = soup.find("li", {"class": "list--piped__li"})
results["number_of_reviews"] = (
reviews_element.get_text(strip=True)
if reviews_element
else "Number of reviews not found"
)
# Loop through each review element
for review in soup.select(".paper.paper--white.paper--box"):
review_data = {}
# Extracting the username
username_element = review.find("a", {"class": "link--header-color"})
review_data["username"] = (
username_element.get_text(strip=True)
if username_element
else "No username found"
)
# Extracting the review summary
summary_element = review.find("h3", {"class": "m-0 l2"})
summary_text = (
summary_element.get_text(strip=True) if summary_element else "No summary found"
)
review_data["summary"] = summary_text.replace('"', "")
# Extracting the review
user_review_element = review.find("div", itemprop="reviewBody")
review_data["review"] = (
user_review_element.get_text(strip=True)
if user_review_element
else "No review found"
)
# Extracting the review date
review_date_element = review.find("time")
review_data["date"] = (
review_date_element.get_text(strip=True)
if review_date_element
else "No date found"
)
# Extracting the review URL
review_url_element = review.find("a", {"class": "pjax"})
review_data["url"] = (
review_url_element["href"] if review_url_element else "No URL found"
)
# Extracting the rating
rating_element = review.find("meta", itemprop="ratingValue")
review_data["rating"] = (
rating_element["content"] if rating_element else "No rating found"
)
# Add the review data to the reviews list
results["reviews"].append(review_data)
# Writing results to a JSON file
with open("G2_reviews.json", "w", encoding="utf8") as f:
json.dump(results, f, indent=2)
print("Data written to G2_reviews.json")
Note: Don’t have an API key? Create a free ScraperAPI account and receive 5,000 API credits to test all our tools.
If you want to follow along, open your preferred editor, and let’s get started!
Scraping G2 Product Reviews with Python
For this tutorial, we’ll focus on scraping ScraperAPI’s G2 reviews, collecting details like:
- Reviewer usernames
- Review summaries (titles)
- Reviews
- Dates
- Review’s URLs
- G2 product/service ratings
As the final step, we’ll export all of the scraped G2 product review data into a JSON file (or a CSV file if you prefer) to make it easier to navigate and repurpose the way you want.
Requirements of G2 Data Extractor
The packages needed as prerequisites for this project are beautifulsoup4, requests, and lxml. You can install these using the following command:
pip install beautifulsoup4 requests lxml
You’ll also need to have Python installed, preferably version 3.8 or beyond, to prevent issues.
Understanding G2 Review Site Structure
Understanding the HTML structure of the G2 website before starting scraping for reviews is critical, as it will allow you to extract data more efficiently.
Use the search bar to search for ScraperAPI on the G2 website. You will get a page similar to this:
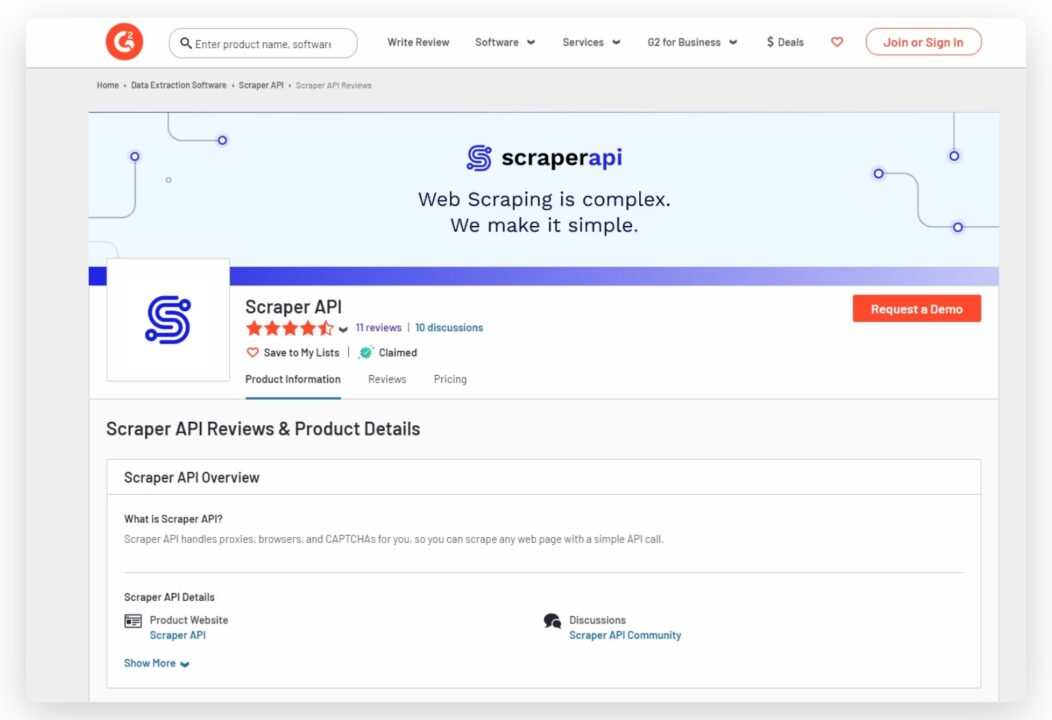
Each review on the G2 product reviews page is typically contained within distinct HTML elements with unique class names or attributes. These elements contain the data we will scrape.
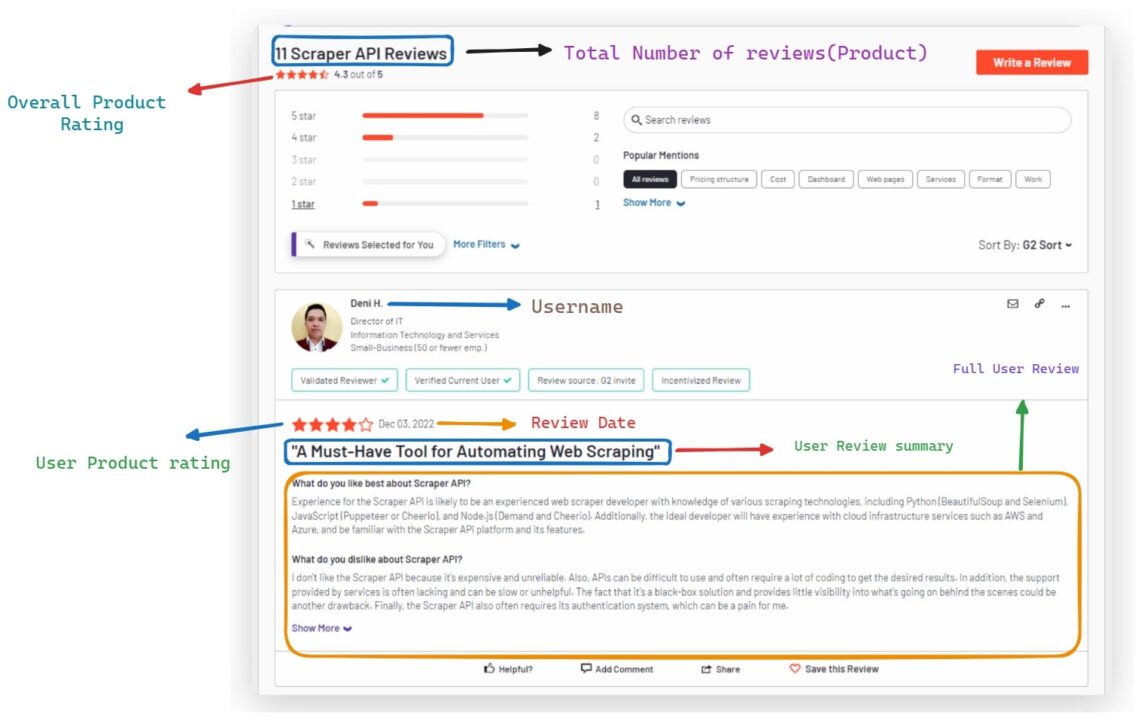
We’ll use BeautifulSoup to target specific data points by identifying unique selectors such as class names, IDs, or attributes.
Start by opening the G2 review page and inspecting the HTML with your browser’s developer tools. This is usually accessed by right-clicking the page and selecting “Inspect“.
The HTML structure can be seen in the developer tools window:
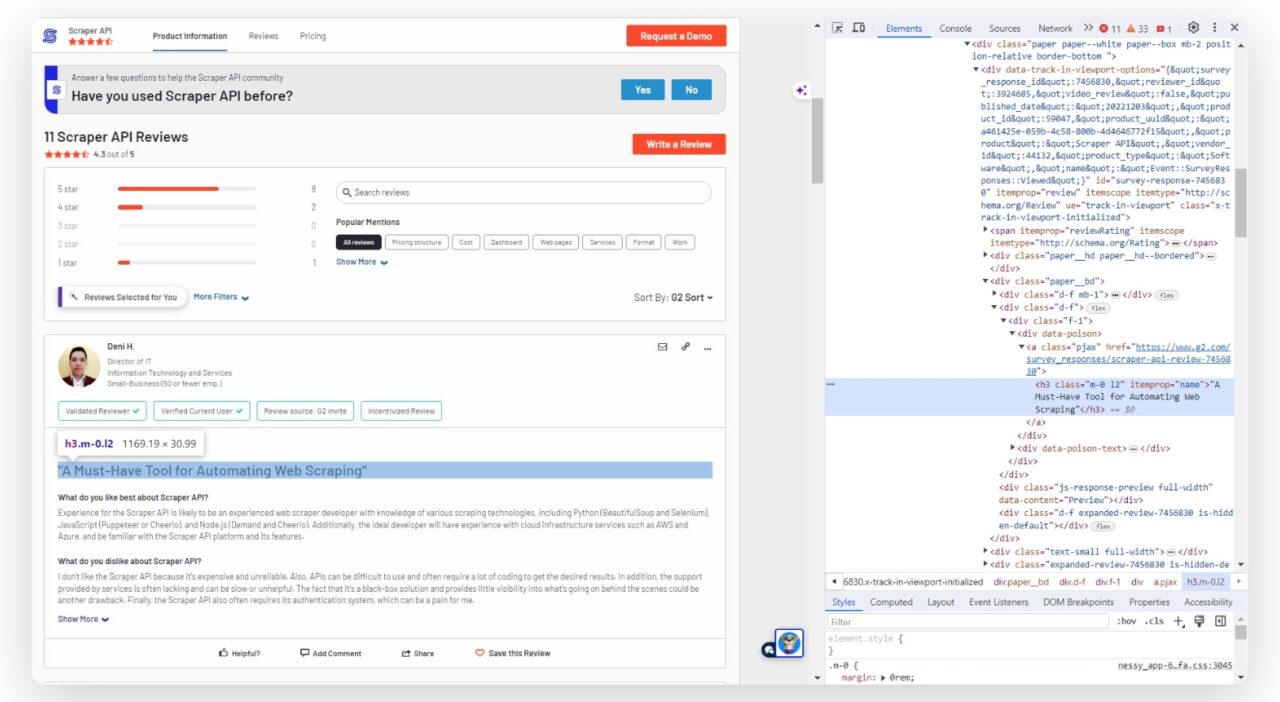
Now that we know this, it’s a matter of taking notes of each element and its particular CSS selector.
Step 1: Setting Up Your G2 Web Scraping Project
First, we need to import the necessary libraries for this project into our Python file:
import requests
from bs4 import BeautifulSoup
import json
Next, we define the API key and the URL of the product page we want to scrape as variables.
Note: You can find your API key from your ScraperAPI dashboard.
API_KEY = "your_api_key"
url = "https://www.g2.com/products/product_id/reviews"
It’s important to note that for scraping G2 effectively, a premium subscription to ScraperAPI is recommended as it provides additional capabilities that are particularly suited for dealing with G2’s level of protection.
Step 2: Sending a Request and Parsing the Response
We create a payload object that includes our API key and the G2 URL we wish to scrape. This payload is then used to send a get() request to our Scraping API, which will handle the complexities of web scraping such as smart IP and header rotation, CAPTCHA handling, and more, using machine learning and statistical analysis.
payload = {"api_key": API_KEY, "url": url}
html = requests.get("https://api.scraperapi.com", params=payload)
Then, we can use BeautifulSoup to parse the HTML response and store it as a soup object – allowing us to then navigate the parsed tree using CSS selectors.
soup = BeautifulSoup(html.text, "lxml")
Step 3: Extracting G2 Software Reviews and Their Details
This step involves initializing a dictionary to store the results and extracting the product name, number of reviews, and user review data from the parsed HTML response.
We start by creating a dictionary called results to store the data we’ll extract.
results = {"product_name": "", "number_of_reviews": "", "reviews": []}
Here, product_name and number_of_reviews are strings that will hold the name of the product and the total number of reviews, respectively, while reviews is a list containing dictionaries, each representing an individual review.
Once we have our dictionary ready, we extract the product name from the parsed HTML.
We use BeautifulSoup’s select_one() method to select the first element that matches the CSS selector .product-head__title a. We then get the text of this element and assign it to results['product_name'].
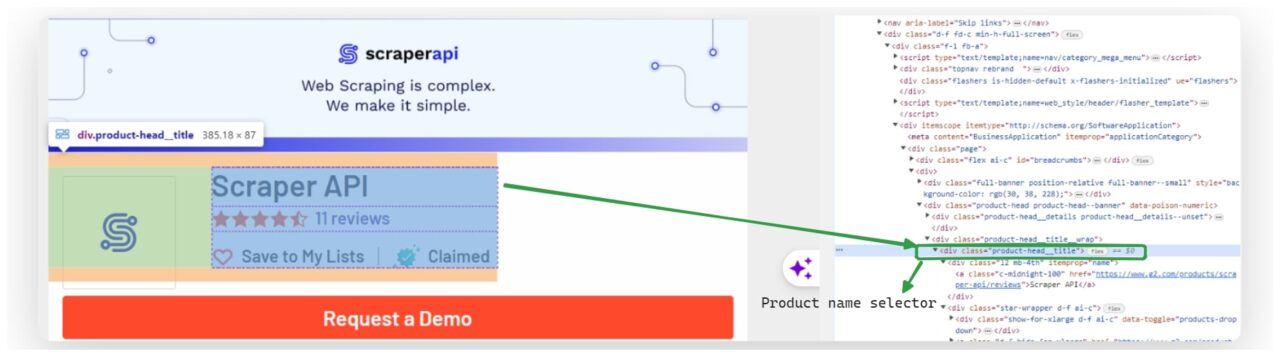
product_name_element = soup.select_one(".product-head__title a")
results["product_name"] = product_name_element.get_text(strip=True) if product_name_element else "Product name not found"
Similarly, we extract the number of reviews by selecting the element with the CSS selector li.list--piped__li and getting its text.

reviews_element = soup.find("li", {"class": "list--piped__li"})
results["number_of_reviews"] = reviews_element.get_text(strip=True) if reviews_element else "Number of reviews not found"
After that, we loop through all the reviews on the page. Each review is selected using the selector .paper.paper--white.paper--box. We extract the username, summary, full review, date, URL, and rating for each review, then proceed to store this information in a new dictionary called review_data.
Scraping the Username of G2 Reviews
The username is typically found within an anchor (a) tag. To extract it, we look for the anchor tag with a class that indicates it contains the username.
For example, if the class name is link--header-color, we then use BeautifulSoup to find this a tag and then get its text content.

username_element = review.find("a", {"class": "link--header-color"})
review_data["username"] = username_element.get_text(strip=True) if username_element else "No username found"
Scraping the G2 Review Summary
The review summary is found within an h3 heading with a class set to m-0 l2.
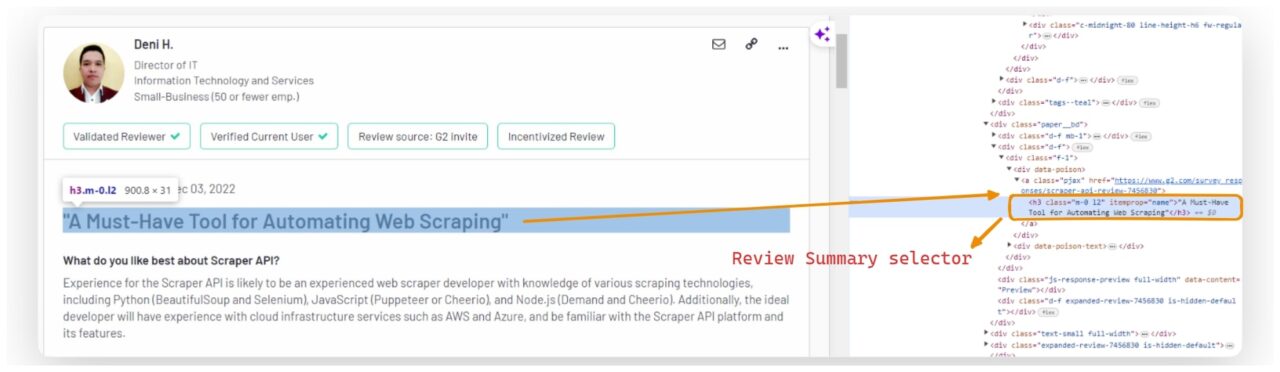
summary_element = review.find("h3", {"class": "m-0 l2"})
review_data["summary"] = summary_element.get_text(strip=True).replace('"', "") if summary_element else "No summary found"
Scraping the G2 Review Body
The full text of the review is usually contained within a div with an itemprop attribute set to reviewBody. To extract the review text, we find this div and retrieve its text content.
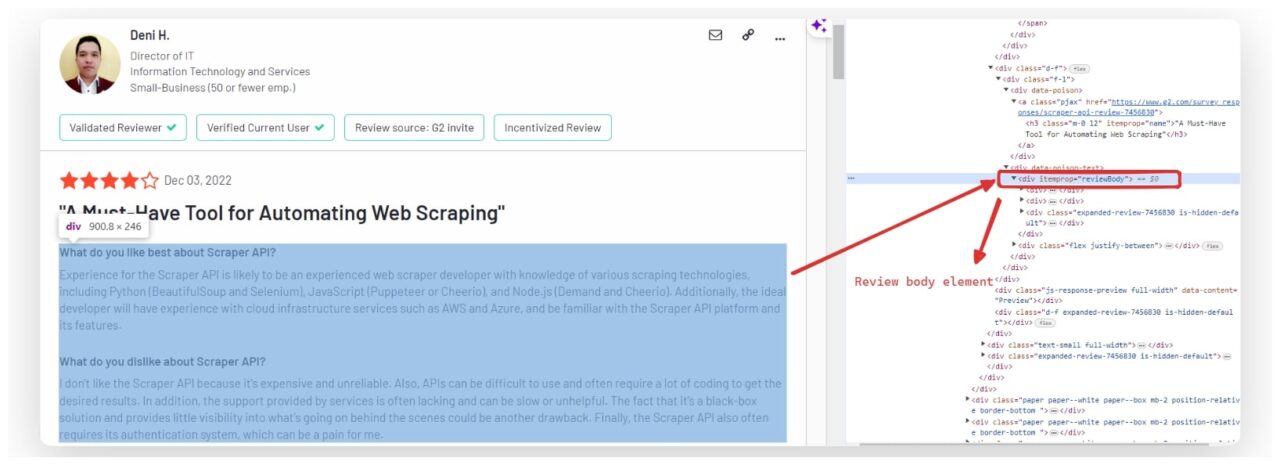
user_review_element = review.find("div", itemprop="reviewBody")
review_data["review"] = user_review_element.get_text(strip=True) if user_review_element else "No review found"
Scraping the G2 Review Date
The date of the review is often located within a time element.
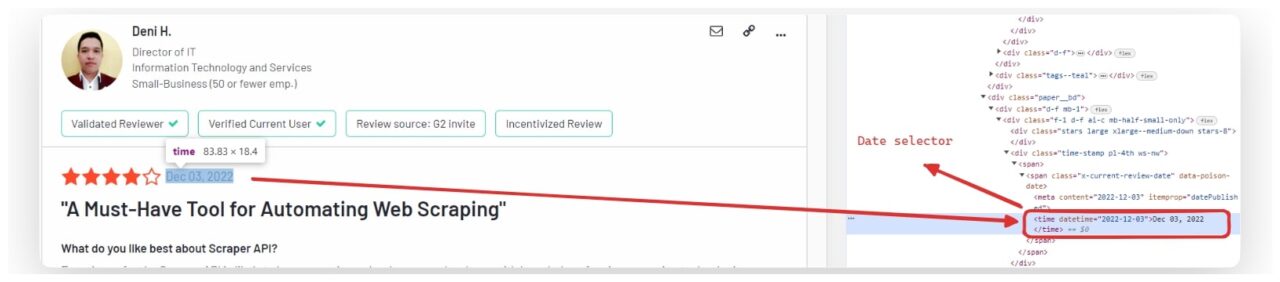
review_date_element = review.find("time")
review_data["date"] = review_date_element.get_text(strip=True) if review_date_element else "No date found"
Scraping the G2 Review URL
To extract the URL of each review, we look for an anchor tag that contains the href attribute. Specifically, we are interested in the a tags with the class pjax, as this is the class used by G2 for the links to the individual reviews.
Here’s how we can include this in our extraction process:
review_url_element = review.find("a", {"class": "pjax"})
review_data["url"] = review_url_element["href"] if review_url_element else "No URL found"
Scraping the G2 Rating
Ratings are found within a meta tag with an attribute itemprop set to ratingValue. We search for this tag and extract its content attribute to get the rating value.
rating_element = review.find("meta", itemprop="ratingValue")
review_data["rating"] = rating_element["content"] if rating_element else "No rating found"
Each piece of data is then stored in a dictionary called review_data. After extracting the data for each review, we append review_data to results['reviews'].
results["reviews"].append(review_data)
By the end of this G2 review extraction step, the results will be a dictionary containing the product name, number of reviews, and a list of dictionaries, each representing an individual review.




