



If you’re working on a large web scraping project (like scraping product information) you have probably stumbled upon paginated pages. It’s standard practice for eCommerce and content sites to break down content into multiple pages to improve user experience. However, web scraping pagination adds some complexity to our work.
In this article, you’ll learn how to build a pagination web scraper in just a few minutes and without getting blocked by any anti-scraping techniques.
Although you can follow this tutorial with no prior knowledge, it might be a good idea to check out our Scrapy for beginners guide first for a more in-depth explanation of the framework before you get started.
Without further ado, let’s jump right into it!
Scraping a Website with Pagination Using Python Scrapy
For this tutorial, we’ll be scraping the SnowAndRock men’s hats category to extract all product names, prices, and links.
A little disclaimer- we’re writing this article using a Mac, so you’ll have to adapt things a little bit to work on PC. Other than that, everything should be the same.
TLDR: here’s a quick snippet to deal with pagination in Scrapy using the “next” button:
</p>
next_page = response.css('a[rel=next]').attrib['href']
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
<p>Keep reading for an in-depth explanation on how to implement this code into your script, along with how to deal with pages without a next button.
1. Set Up Your Development Environment
Before we start writing any code, we need to set up our environment to work with Scrapy, a Python library designed for web scraping. It allows us to crawl and extract data from websites, parse the raw data into a structured format, and select elements using CSS and/or XPath selectors.
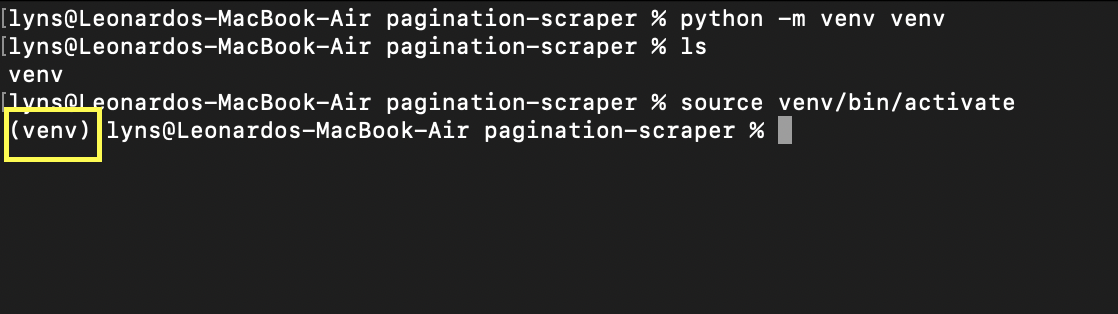
First, let’s create a new directory (we’ll call it pagination-scraper) and create a python virtual environment inside using the command python -m venv venv. Where the second venv is the name of your environment – but you can call it whatever you want.
To activate it, just type source venv/bin/activate. Your command prompt should look like this:
Now, installing Scrapy is as simple as typing pip3 install scrapy – it might take a few seconds for it to download and install it.
Once that’s ready, we’ll input cd venv and create a new Scrapy project: scrapy startproject scrapypagination.
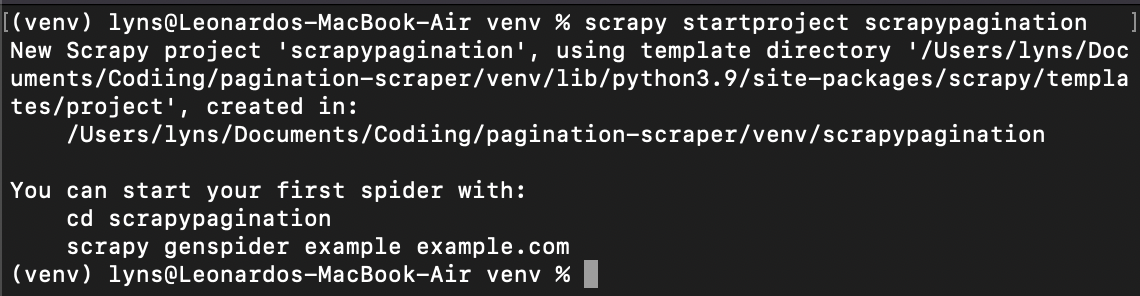
Now you can see that Scrapy kick-started our project for us by installing all the necessary files.
2. Setting Up ScraperAPI to Avoid Bans
The hardest part of handling paginated pages is not writing the script itself, it’s how to not get our bot blocked by the server.
For that, we’ll need to create a function (or set of functions) that rotates our IP address after several attempts (meaning we also need access to a pool of IP addresses). Also, some websites use advanced techniques like CAPTCHAs and browser behavior profiling.
To save us time and headaches, we’ll use ScraperAPI, an API that uses machine learning, huge browser farms, 3rd party proxies, and years of statistical analysis to handle every anti-bot mechanism our script could encounter automatically.
Best of all, setting up ScraperAPI into our project is super easy with Scrapy:
</p>
import scrapy
from urllib.parse import urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxxx'
def get_scraperapi_url(url):
payload = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
<p>As you can see, we’re defining the get_scraperapi_url() method to help us construct the URL we’ll send the request to. First, we added our dependencies on the top and then added the API_KEY variable containing our API key – to get your key, just sign up for a free ScraperAPI account and you’ll find it on your dashboard.
This method will build the URL for the request for each URL our scraper finds, and that’s why we’re setting it up this way instead of the more direct way of just adding all parameters directly into the URL like this:
</p>
start_urls = ['http://api.scraperapi.com?api_key={yourApiKey}&url={URL}']
<p>3. Understanding the URL Structure of the Website
URL structure is pretty much unique to each website. Developers tend to use different structures to make it easier to navigate for them and, in some cases, optimize the navigation experience for search engine crawlers like Google and real users.
To scrape paginated content, we need to understand how it works and plan accordingly, and there’s no better way to do it than inspecting the pages and seeing how the URL itself changes from one page to the next.
So if we go to https://www.snowandrock.com/c/mens/accessories/hats.html and scroll to the last product listed, we can see that it uses a numbered pagination plus a next button.
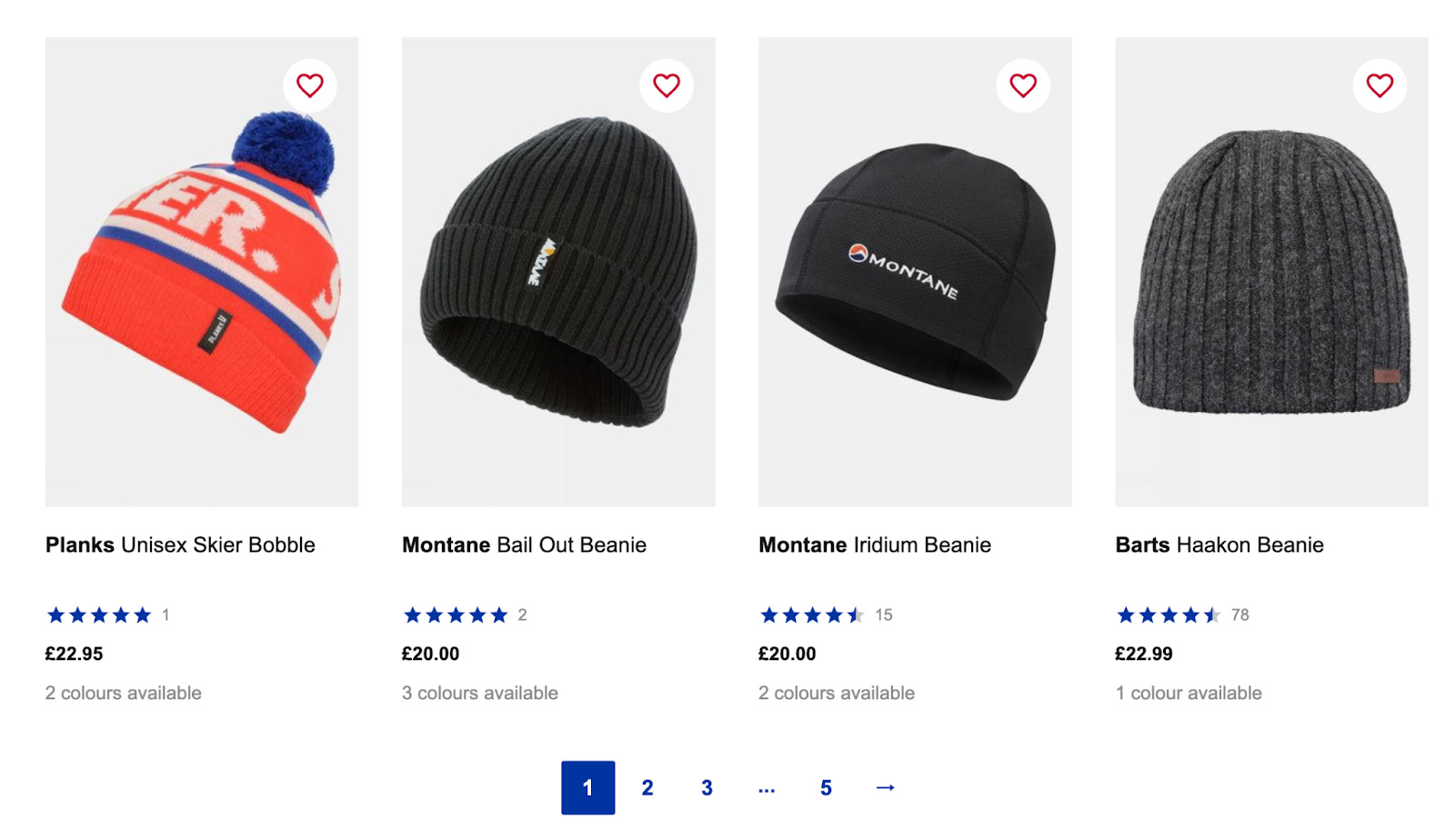
This is great news, as selecting the next button on every page will be easier than cycling through each page number. Still, let’s see how the URL changes when clicking on the second page.
Here’s what we’ve found:
- Page 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
- Page 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
- Page 3: https://www.snowandrock.com/c/mens/accessories/hats.html?page=2&size=48
Notice that the page one URL changes when you go back to the page using the navigation, changing to page=0. Although we’re going to use the next button to navigate this website’s pagination, it is not as simple in every case.
Understanding this structure will help us build a function to change the page parameter in the URL and increase it by 1, allowing us to go to the next page without a next button.
Note: not all pages follow this same structure so make sure to always check which parameters change and how.
Now that we know the initial URL for the request we can create a custom spider.
4. Sending the Initial Request Using the Start_Requests() Method
For the initial request we’ll create a Spider class and give it the name of Pagi:
</p>
class PaginationScraper(scrapy.Spider):
name = "pagi"
<p>Then, we define the start_requests() method:
</p>
def start_requests(self):
start_urls = ['https://www.snowandrock.com/c/mens/accessories/hats.html']
for url in start_urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
<p>Now, after running our script, it will send each new URL found to this method, where the new URL will merge with the result of the get_scraperapi_url() method, sending the request through the ScraperAPI severs and bullet-proofing our project.
5. Building Our Parser
After testing our selectors with Scrapy Shell, these are the selectors we came up with:
</p>
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': hats.css('a').attrib['href'],
}
<p>If you’re not familiar with Scrapy Shell or with Scrapy in general, it might be a good idea to check our full Scrapy tutorial where we cover all the basics you need to know.
However, we’re basically selecting all the divs containing the information we want (response.css('div.as-t-product-grid__item') and then extracting the name, the price, and product’s link.
6. Make Scrapy Move Through the Pagination
Great! We have the information we need from the first page, now what? Well, we’ll need to tell our parser to find the new URL somehow and send it to the start_requests() method we defined before. In other words, we need to find an ID or class we can use to get the link inside the next button.
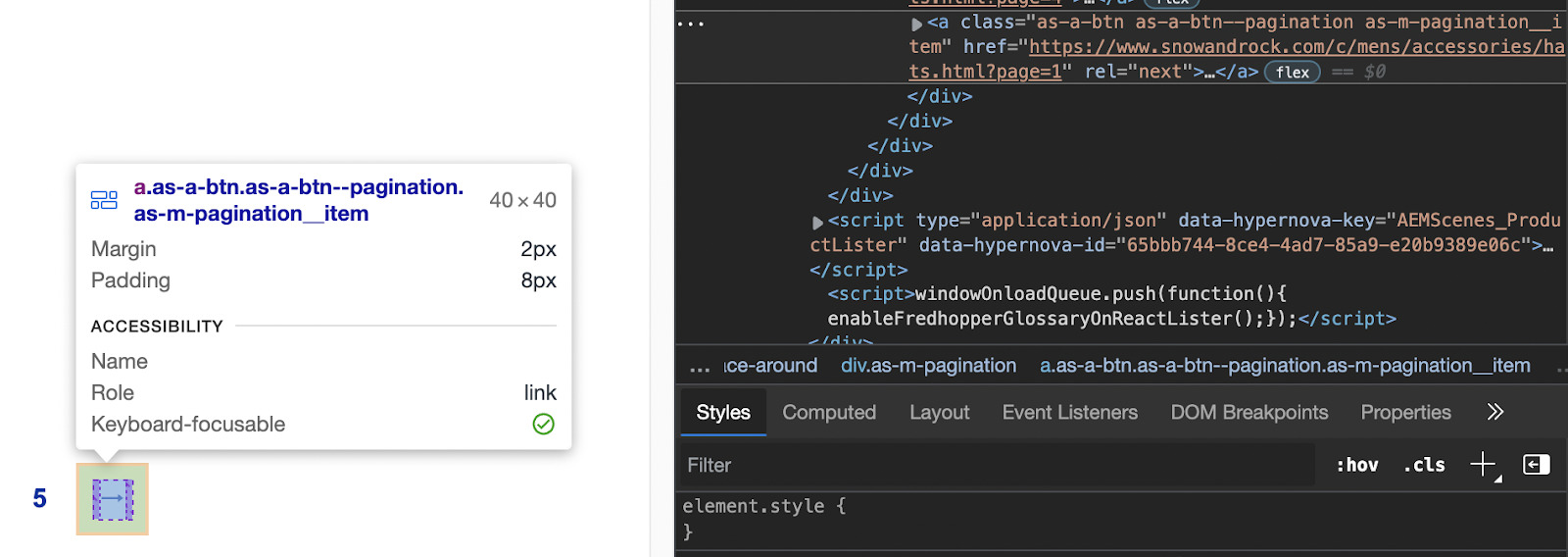
Technically we could use the class ‘.as-a-btn.as-a-btn--pagination as-m-pagination__item’ but lucky for us, there’s a better target: rel=next. It won’t get confused with any other selectors and picking an attribute with Scrapy is simple.
</p>
next_page = response.css('a[rel=next]').attrib['href']
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
<p>Now it will iterate between pages until there are no more pages in the pagination – so we don’t need to set any other stop mechanism.
If you’ve been following along, your file should look like this:
</p>
import scrapy
from urllib.parse import urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxx'
def get_scraperapi_url(url):
payload = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class PaginationScraper(scrapy.Spider):
name = "pagi"
def start_requests(self):
start_urls = ['https://www.snowandrock.com/c/mens/accessories/hats.html']
for url in start_urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': hats.css('a').attrib['href'],
}
next_page = response.css('a[rel=next]').attrib['href']
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
<p>It is now ready to run!
Dealing With Pagination Without Next Button
So far we’ve seen how to build a web scraper that moves through pagination using the link inside the next button – remember that Scrapy can’t actually interact with the page so it won’t work if the button has to be clicked in order for it to show more content.
However, what happens when it isn’t an option? In other words, how can we navigate a pagination without a next button to rely on.
Here’s where understanding the URL structure of the site comes in handy:
- Page 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
- Page 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
- Page 3: https://www.snowandrock.com/c/mens/accessories/hats.html?page=2&size=48
The only thing changing between URLs is the page parameter, which increases by 1 for each next page. What does it mean for our script? Well, first of all, we’ll have to change the way we’re sending the initial request by adding a new variable:
</p>
class PaginationScraper(scrapy.Spider):
name = "pagi"
page_number = 1
start_urls = ['http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48']
<p>In this case we’re also using the direct cURL structure of ScraperAPI because we’re just changing a parameter- meaning there’s no need to construct a whole new URL. This way every time it changes, it will still send the request through ScraperAPI’s servers.
Next, we’ll need to change our condition at the end to match the new logic:
</p>
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&size=48'
if PaginationScraper.page_number < 6:
PaginationScraper.page_number += 1
yield response.follow(next_page, callback=self.parse)
<p>What’s happening here is that we’re accessing the page_number variable from the PaginationScraper() method to replace the value of the page parameter inside the URL.
Afterwards, it will check if the value of page_number is less than 6 – because after page 5 there are no more results.
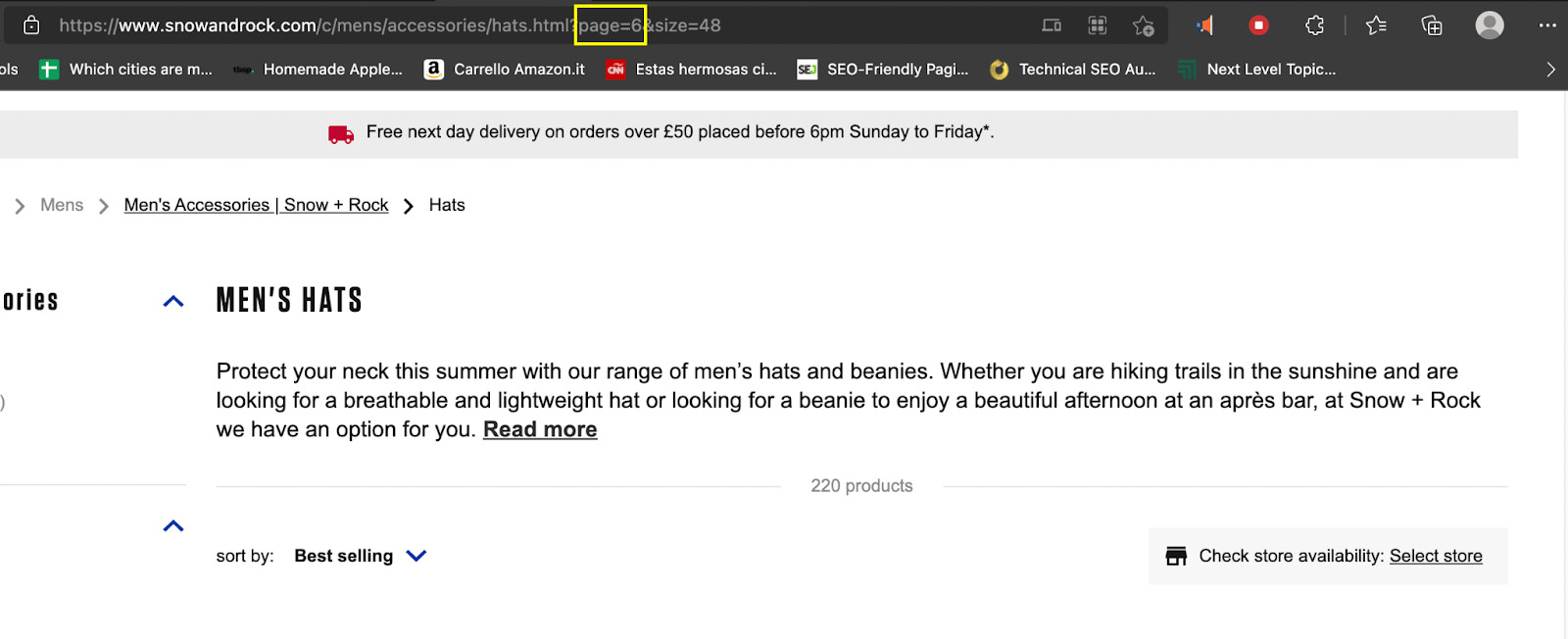
As long as the condition is met, it will increase the page_number value by 1 and send the URL to be parsed and scraped, and so on until the page_number is 6 or more.
Here’s the full code to scrape paginated pages without a next button:
</p>
import scrapy
class PaginationScraper(scrapy.Spider):
name = "pagi"
page_number = 1
start_urls = ['http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48']
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': 'https://www.snowandrock.com/' + hats.css('a').attrib['href']
}
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660fc6ee44&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&size=48'
if PaginationScraper.page_number < 6:
PaginationScraper.page_number += 1
yield response.follow(next_page, callback=self.parse)
<p>Wrapping Up
Whether you’re compiling real estate data or scraping eCommerce platforms like Etsy, dealing with pagination will be a common occurrence and you need to be prepared to get creative.
Alternative data has become a must-have for almost every industry in the world, and having the ability to create complex and efficient scrapers will give you a huge competitive advantage.
No matter if you’re a freelance developer or a business owner ready to invest in web scraping, ScraperAPI has all the tools you need to collect data effortlessly by handling all the roadblocks automatically for you.
Until next time, happy scraping!





