



Train a large language model to figure out how to extract entities, and provide a key piece of information about that entity (its Wikipedia URL)
When search engines crawl websites they try their best to get as much information as possible from those pages. Even though there have been massive developments on that front, they are still making guesses at best, using probabilities about the information they are extracting.
Providing search engines (or any other apps using our web pages) with structured data makes things much easier, and allows for very interesting applications and usage of our data.
In many cases, we are faced with a situation where we have numerous pages that don’t contain structured data, but it needs to be done. We can of course take the manual route and classify/tag our content one by one. We can also explore recent advances uses large language models, and training them for the specific task of extracting certain data from our pages, and creating the desired additional markup in the form of JSON-LD scripts. But we are not restricted to that format, once we have access to the data, we can format it any way we want.
Here is a quick overview of the problem we might be faced with and the suggested steps to solve it:
- We have a large website with (tens or hundreds) of thousands of pages that do not have any structured markup (JSON-LD, Twitter, OpenGraph for example).
- We want to create structured markup for those pages.
- We want to do this on a large scale.
- We will train an LLM to extract entities from articles, and provide a link to the Wikipedia page of each entity.
To make things clear, we will provide ChatGPT with an input like the following, which is the summary part a Wikipedia page, “Basketball” in this case. Only the first few lines are displayed, and we will later work through the full example:
</p>
<pre>Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender’s hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three…</pre>
<p>And we want to get a response as follows:
| idx | entity | url |
| 0 | James Naismith | https://en.wikipedia.org/wiki/James_Naismith |
| 1 | Springfield, Massachusetts | https://en.wikipedia.org/wiki/Springfield,_Massachusetts |
| 2 | National Basketball Association | https://en.wikipedia.org/wiki/National_Basketball_Association |
| 3 | NBA | https://en.wikipedia.org/wiki/National_Basketball_Association |
| 4 | EuroLeague | https://en.wikipedia.org/wiki/EuroLeague |
| 5 | Basketball Champions League Americas | https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas |
| 6 | FIBA Basketball World Cup | https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup |
| 7 | EuroBasket | https://en.wikipedia.org/wiki/EuroBasket |
| 8 | FIBA AmeriCup | https://en.wikipedia.org/wiki/FIBA_AmeriCup |
| 9 | FIBA Women’s Basketball World Cup | https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup |
| 10 | WNBA | https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association |
| 11 | NCAA Women’s Division I Basketball Championship | https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament |
| 12 | EuroLeague Women | https://en.wikipedia.org/wiki/EuroLeague_Women |
It’s quite an ambitious goal to automate the process of extracting entities, and not only that, we will also get their respective Wikipedia URLs.
Once we have those URLs, it becomes easier to get more information about each entity, as we can scrape that page, search Google, and so on. But we first need that initial starting page. We won’t go beyond that step in this article, and we will focus on the process up to this point.
Before getting started with coding, let’s first make a distinction between normal prompting, and fine-tuned models. Regular prompts are simple instructions or questions, instructing the model to complete a certain task, answer a question, or create some content. It aims to be a universal question/answer machine that can function as your personal assistant. When we fine-tune a model on the other hand, we are training the LLM for a particular task which it will perform much better than a regular prompt, with the limitation of knowing how to perform that task only. It’s kind of like the difference between a regular car (normal prompting) and a metro train (fine-tuned models). Your car can be used for various tasks, and can satisfy almost all our transportation needs. A metro train can only do one thing, go from point A to point B and back. It is very limited, but it performs this task extremely well, way better than a car, and on a much larger scale. Here is a quick comparison between these two approaches:
| Area | Normal prompting | Fine-tuned model |
| Scope | General | Specific |
| Training process | Included in prompt | Done by providing many similar consistent examples |
| Generality | Jack of all trades | Very specific tool |
You have probably already experimented with normal prompts, and for the above task, is would be something like the following:
"Extract the main entities of the following text, and provide the Wikipedia URL for each, format the response as a table:
FULL TEXT GOES HERE"
These days you are stuck with a paradoxical situation here, which arises from the limitations on prompt length. If you want to get a good response, you need to provide a very detailed prompt with examples, and clear instructions. But the more examples and instructions you provide, the less space you have to provide the content that needs to be processed. The opposite is also true. With a fine tuned model, you only send a piece of text which will function as the prompt. Our trained model will not think about it, or try anything else other than what it was trained for (the above task).
Let’s quickly go through a simple process of training the LLM with a fine-tuned model:
| prompt | response |
| blue | be |
| flower | fr |
| book | bk |
| sea | sa |
| window | ww |
| car | cr |
| bag | ?? |
Having gone through the examples above, it was probably easy for you to figure out how to complete the last prompt “bag”, because the examples before it were consistent and clear. Each response has only two letters, and when related to its respective prompt, you can clearly see that it is basically the first and last characters of that prompt. The more examples we provide, the more confident you would be that this is indeed the pattern we are after. The key here then, is to provide numerous, clear, and most importantly, consistent prompt:response pairs.
This is exactly how we will train ChatGPT to extract the required entities. Our “prompt” will simply be an article and it will figure out what to do with it (provided we did a good job in the training phase).
In this sense, our prompts are going to be extremely easy. They would not contain any instructions or clarifications. But the difficulty is in providing a large-enough number of examples where the LLM would be able to clearly get the pattern we are after.
The Training Plan
We need to provide a dataset with the following conditions:
- A large number of articles (hundreds)
- Those articles need to have entities identified and extracted from them by humans
- Not only do we want to get the entities, we need each entity’s Wikipedia URL as well
Where might we find such a dataset? On Wikipedia itself. It satisfies all those conditions. That was easy. Now the implementation. Fortunately, the Wikipedia API provides a few convenient features to make our job easier. For each article we can download the text along with various interesting elements. We will focus on two of them:
- Summary: This is the first few paragraphs that we see at the beginning of each article.
- Links: A list of all links in the article, with
</p>
<pre>import re
import json
import advertools as adv
import pandas as pd
import wikipediaapi
pd.options.display.max_columns = None
from IPython.display import display_html, display_markdown, IFrame
import openai
openai.api_key = 'YOUR OPEN AI API KEY'</pre>
<p>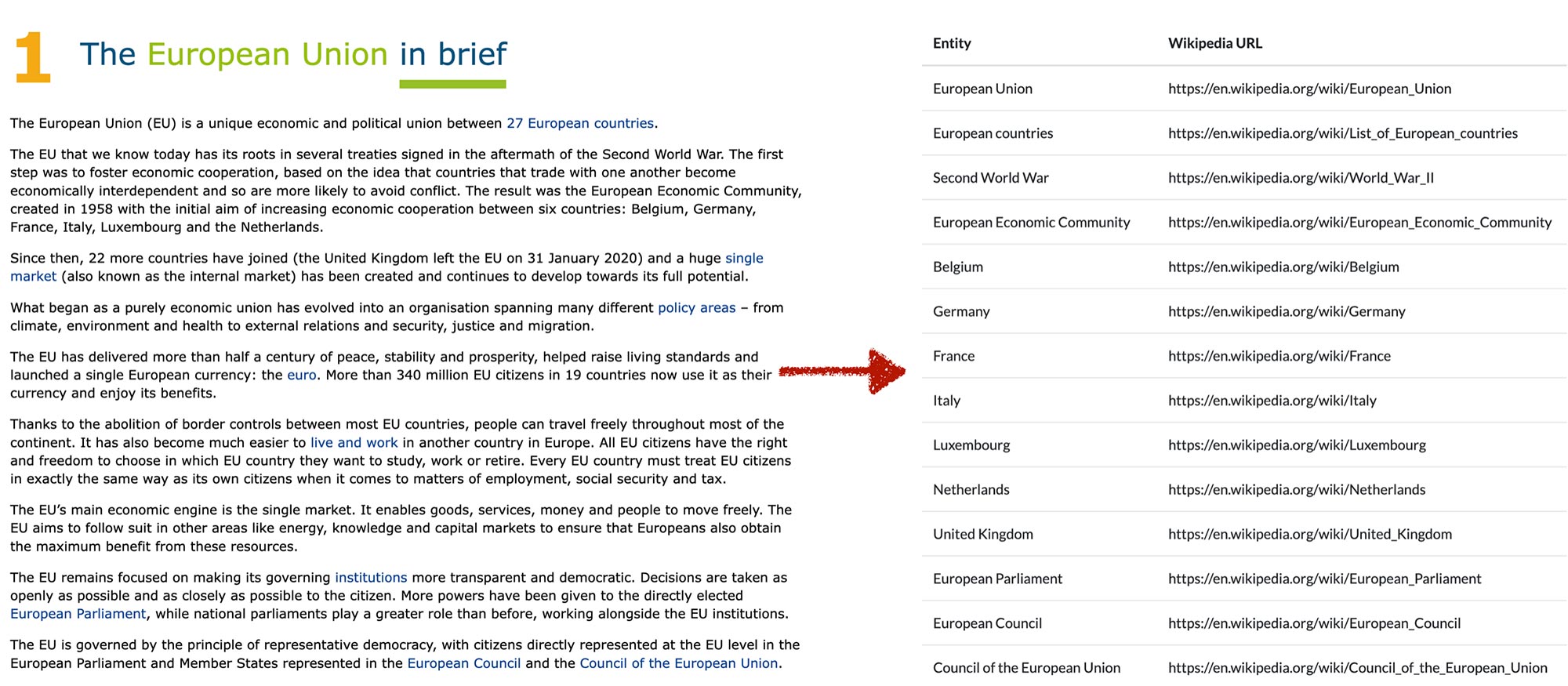
Getting data from the Wikipedia API
We will first go through the process step-by-step for one Wikipedia article, and then generalize.
We first initiate the Wikipedia object and then use it to get data for any page. To specify the page we need its slug, the final folder of path part of the URL https://en.wikipedia.org/wiki/Article_title “Article_title” in this case. This is very important because it is not always easy to infer this part of the URL. In some cases it is straightforward, like /Pizza or /Music, but in many cases it’s not, like /FIBA_Women's_Basketball_World_Cup
We now create a variable for the page that we want:
</p>
<pre>wiki_wiki = wikipediaapi.Wikipedia('en')
page_basketball = wiki_wiki.page('Basketball')
print(page_basketball.summary[:1500])</pre>
<p></p>
<pre>Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops and the player fouled or designated to shoot a technical foul is given one, two or three one-point free throws. The team with the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period of play (overtime) is mandated.
Players advance the ball by bouncing it while walking or running (dribbling) or by passing it to a teammate, both of which require considerable skill. On offense, players may use a variety of shots – the layup, the jump shot, or a dunk; on defense, they may steal the ball from a dribbler, intercept passes, or block shots; either offense or defense may collect a rebound, that is, a missed shot that bounces from rim or backboard. It is a violation to lift or drag one's pivot foot without dribbling the ball, to carry it, or to hold the ball with both hands then resume dribbling.
The five players on each side fall into five playing posi</pre>
<p>As you can see, we can request the summary attribute of that object to the summary text. Above we have the first few paragraph of the summary.
Another interesting attribute that we can get is the link attribute. This give us the text of each link, as well as additional information about each link. Here we can see the first few links, and we also print the total number of links to get an idea.
Getting an article’s links
</p>
<pre>print(len(page_basketball.links))
list(page_basketball.links.items())[:20]</pre>
<p>1309
</p>
<pre>[('16-inch softball', 16-inch softball (id: ??, ns: 0)),
('1936 Summer Olympics', 1936 Summer Olympics (id: ??, ns: 0)),
('1979 NBL Season', 1979 NBL Season (id: ??, ns: 0)),
('1992 Summer Olympics', 1992 Summer Olympics (id: ??, ns: 0)),
("1992 United States men's Olympic basketball team",
1992 United States men's Olympic basketball team (id: ??, ns: 0)),
('1998 NBL Season', 1998 NBL Season (id: ??, ns: 0)),
('1998–99 NBL season', 1998–99 NBL season (id: ??, ns: 0)),
('1–2–1–1 zone press', 1–2–1–1 zone press (id: ??, ns: 0)),
('1–3–1 defense and offense', 1–3–1 defense and offense (id: ??, ns: 0)),
('2000–01 FIBA SuproLeague', 2000–01 FIBA SuproLeague (id: ??, ns: 0)),
('2004 Summer Olympics', 2004 Summer Olympics (id: ??, ns: 0)),
('2006 FIBA World Championship for Women',
2006 FIBA World Championship for Women (id: ??, ns: 0)),
('2007 Asian Indoor Games', 2007 Asian Indoor Games (id: ??, ns: 0)),
("2008 United States men's Olympic basketball team",
2008 United States men's Olympic basketball team (id: ??, ns: 0)),
('2009 Asian Youth Games', 2009 Asian Youth Games (id: ??, ns: 0)),
('2010 FIBA World Championship',
2010 FIBA World Championship (id: ??, ns: 0)),
('2010 Youth Olympics', 2010 Youth Olympics (id: ??, ns: 0)),
('2011 FIBA 3x3 Youth World Championships',
2011 FIBA 3x3 Youth World Championships (id: ??, ns: 0)),
('2012 FIBA 3x3 World Championships',
2012 FIBA 3x3 World Championships (id: ??, ns: 0)),
('2014 FIBA Basketball World Cup',
2014 FIBA Basketball World Cup (id: ??, ns: 0))]</pre>
<p>Those links are scattered all over the article, and what we want now is to find the ones that are present in the summary part of the article. We can do that with a simple regular expression.
Creating a regular expression to extract links which are important entities
Since we have the anchor text of each link on the article, the regex will simply be a concatenation of all the links’ text, separated by the pipe “or” operator. The only other thing we need to cater for, is to sort our links by length. Here is a simple example to illustrate this point. Assume we want to extract any instance of the word “won” or “wonderful” from a piece of text. Let’s first test the regex won|wonderful:
</p>
<pre>import re
text = 'I won the game at the wonderful tournament'
re.findall('won|wonderful', text)</pre>
<p></p>
<pre>['won', 'won']</pre>
<p>What just happened?
The first instance of “won”, which is the second word in the sentence was extracted correctly, but the second wasn’t. Actually it was, but it wasn’t what we intended. Because we first specified “won”, the regex engine starts to look for that pattern, if it doesn’t find it, it looks for the other option. In our case it found the second instance of “won” right before “derful”. Once the regex engine extracted the second “one”, it is now at the “d”, and from there there aren’t any other instances of “won”. Let’s try the same regex, but place the longer pattern before the shorter one:
</p>
<pre>re.findall('wonderful|won', text)</pre>
<p></p>
<pre>['won', 'wonderful']</pre>
<p>It now works as intended. For that reason we will make our link extraction regex sorted by length, in order to avoid this situation.
The other thing we want to make sure of is that we want to extract whole words. Assume we want to extract the pattern “rest”. If the regex engine finds the word “restaurant” in the supplied text, it will extract it as a legitimate match for the pattern. But we don’t want that. We only want “rest” as a complete word. For this, we can use the word boundary pattern in regular expressions \b. Because the backslack is a special character in regex, we escape it by adding another one. Our regex will look like this:
pattern_1\\b|\\bpattern_2\\b|\\bpattern_3 and so on.
The following code creates the desired regex by:
- Concatenating all anchor texts of our links
- Sorting them by length, in descending order (longer patterns before shorter ones)
- Joining them by the pipe
|as well as word the word boundary character\\bfrom both sides
</p>
<pre>page_basketball_linksregex = '\\b|\\b'.join(sorted(page_basketball.links.keys(), key=len, reverse=True))
page_basketball_linksregex[:400]</pre>
<p></p>
<pre>"List of U.S. high school basketball national player of the year awards\\b|\\bList of basketball players who have scored 100 points in a single game\\b|\\bYoung Men's Christian Association Building (Albany, New York)\\b|\\bCategory:Articles with dead external links from February 2021\\b|\\bCategory:Articles with disputed statements from January 2019\\b|\\bCategory:Articles with disputed statements from Janua"</pre>
<p>Here are the first few lines from our summary text, with the anchor text of the entities highlighted so you can get an idea on how this will end up working:
Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender’s hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops and the player fouled or designated to shoot a technical foul is given one, two or three one-point free throws. The team with the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period of play (overtime) is mandated.
Players advance the ball by bouncing it while walking or running (dribbling) or by passing it to a teammate, both of which require considerable skill. On offense, players may use a variety of shots – the layup, the jump shot, or a dunk; on defense, they may steal the ball from a dribbler, intercept passes, or block shots; either offense or defense may collect a rebound, that is, a missed shot that bounces from rim or backboard. It is a violation to lift or drag one’s pivot foot without dribbling the ball, to carry it, or to hold the ball with both hands then resume dribbling.
The five players on each side fall into five playing positions. The tallest player is usually the center, the second-tallest and strongest is the power forward, a slightly shorter but more agile player is the small forward, and the shortest players or the best ball handlers are the shooting guard and the point guard, who implements the coach’s game plan by managing the execution of offensive and defensive plays (player positioning). Informally, players may play three-on-three, two-on-two, and one-on-one.
Invented in 1891 by Canadian-American gym teacher James Naismith in Springfield, Massachusetts, in the United States, basketball has evolved to become one of the world’s most popular and widely viewed sports. The National Basketball Association (NBA) is the most significant professional basketball league in the world in terms of popularity, salaries, talent, and level of competition (drawing most of its talent from U.S. college basketball). Outside North America, the top clubs from national leagues qualify to continental championships such as the EuroLeague and the Basketball Champions League Americas. The FIBA Basketball World Cup and Men’s Olympic Basketball Tournament are the major international events of the sport and attract top national teams from around the world. Each continent hosts regional competitions for national teams, like EuroBasket and FIBA AmeriCup.
The FIBA Women’s Basketball World Cup and Women’s Olympic Basketball Tournament feature top national teams from continental championships. The main North American league is the WNBA (NCAA Women’s Division I Basketball Championship is also popular), whereas the strongest European clubs participate in the EuroLeague Women.
We now want to get the link text that have matches in the summary of our article, and place them in a simple dictionary. The keys will be the matched anchor text. The values will the request page from Wikipedia (containing all the relevant data).
While setting the values, we will be sending a request to Wikipedia to get new data about the matched page. The end result, which is the links_wikis dictionary will contain the full information on each extracted match. We are mainly interested in the name of the entity and its URL, so we can create a simple DataFrame to show the end result that we are looking for.
</p>
<pre>links_wikis = {}
for match in re.finditer(page_basketball_linksregex, page_basketball.summary):
links_wikis[match.group()] = wiki_wiki.page(match.group())</pre>
<p>Structure the entites and their links (extracted from the aritcle’s summary)
</p>
<pre>ent_link = pd.DataFrame({
'entity': links_wikis.keys(),
'url': [link.fullurl for link in links_wikis.values()]})
ent_link.style.set_caption('</pre>
<p> </p>
<h3>Entities in the summary section of the <code>/Basketball</code> wiki</h3>
<p> </p>
<p>‘)</p>
<p> </p>
<p>Entities in the summary section of the /Basketball wiki
| entity | url | |
| 0 | James Naismith | https://en.wikipedia.org/wiki/James_Naismith |
| 1 | Springfield, Massachusetts | https://en.wikipedia.org/wiki/Springfield,_Massachusetts |
| 2 | National Basketball Association | https://en.wikipedia.org/wiki/National_Basketball_Association |
| 3 | NBA | https://en.wikipedia.org/wiki/National_Basketball_Association |
| 4 | EuroLeague | https://en.wikipedia.org/wiki/EuroLeague |
| 5 | Basketball Champions League Americas | https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas |
| 6 | FIBA Basketball World Cup | https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup |
| 7 | EuroBasket | https://en.wikipedia.org/wiki/EuroBasket |
| 8 | FIBA AmeriCup | https://en.wikipedia.org/wiki/FIBA_AmeriCup |
| 9 | FIBA Women’s Basketball World Cup | https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup |
| 10 | WNBA | https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association |
| 11 | NCAA Women’s Division I Basketball Championship | https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament |
| 12 | EuroLeague Women | https://en.wikipedia.org/wiki/EuroLeague_Women |
Given the “Basketball” page, we ended up with a DataFrame that contains entities in its summary part, together with each URL that belongs to each entity.
The next step is to format this response in a consistent way so ChatGPT can know exactly how to format the responses for us. The format will be as follows.
Format the GPT completion in a clear and consistent way
</p>
<pre>Entity_1: https://en.wikipedia.org/wiki/Entity_1
Entity_2: https://en.wikipedia.org/wiki/Entity_2
Entity_3: https://en.wikipedia.org/wiki/Entity_3
...</pre>
<p></p>
<pre>completion = '@@'.join([': '.join(entity) for entity in ent_link.values])
print(*completion.split('@@'), sep='\n')</pre>
<p></p>
<pre>James Naismith: https://en.wikipedia.org/wiki/James_Naismith
Springfield, Massachusetts: https://en.wikipedia.org/wiki/Springfield,_Massachusetts
National Basketball Association: https://en.wikipedia.org/wiki/National_Basketball_Association
NBA: https://en.wikipedia.org/wiki/National_Basketball_Association
EuroLeague: https://en.wikipedia.org/wiki/EuroLeague
Basketball Champions League Americas: https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas
FIBA Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup
EuroBasket: https://en.wikipedia.org/wiki/EuroBasket
FIBA AmeriCup: https://en.wikipedia.org/wiki/FIBA_AmeriCup
FIBA Women's Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup
WNBA: https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association
NCAA Women's Division I Basketball Championship: https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament
EuroLeague Women: https://en.wikipedia.org/wiki/EuroLeague_Women</pre>
<p>We now want to place the prompt/completion pair in the standard JSON format that ChatGPT requires, which is
{"prompt": "prompt text goes here", "completion": "completion text goes here"}
Combine prompts and their completions in a JSON format saved in a jsonlines file (this is our “training”)
</p>
<pre>print(json.dumps({"prompt":page_basketball.summary,"completion":completion}))</pre>
<p></p>
<pre>{"prompt": "Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops and the player fouled or designated to shoot a technical foul is given one, two or three one-point free throws. The team with the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period of play (overtime) is mandated.\nPlayers advance the ball by bouncing it while walking or running (dribbling) or by passing it to a teammate, both of which require considerable skill. On offense, players may use a variety of shots \u2013 the layup, the jump shot, or a dunk; on defense, they may steal the ball from a dribbler, intercept passes, or block shots; either offense or defense may collect a rebound, that is, a missed shot that bounces from rim or backboard. It is a violation to lift or drag one's pivot foot without dribbling the ball, to carry it, or to hold the ball with both hands then resume dribbling.\nThe five players on each side fall into five playing positions. The tallest player is usually the center, the second-tallest and strongest is the power forward, a slightly shorter but more agile player is the small forward, and the shortest players or the best ball handlers are the shooting guard and the point guard, who implements the coach's game plan by managing the execution of offensive and defensive plays (player positioning). Informally, players may play three-on-three, two-on-two, and one-on-one.\nInvented in 1891 by Canadian-American gym teacher James Naismith in Springfield, Massachusetts, in the United States, basketball has evolved to become one of the world's most popular and widely viewed sports. The National Basketball Association (NBA) is the most significant professional basketball league in the world in terms of popularity, salaries, talent, and level of competition (drawing most of its talent from U.S. college basketball). Outside North America, the top clubs from national leagues qualify to continental championships such as the EuroLeague and the Basketball Champions League Americas. The FIBA Basketball World Cup and Men's Olympic Basketball Tournament are the major international events of the sport and attract top national teams from around the world. Each continent hosts regional competitions for national teams, like EuroBasket and FIBA AmeriCup.\nThe FIBA Women's Basketball World Cup and Women's Olympic Basketball Tournament feature top national teams from continental championships. The main North American league is the WNBA (NCAA Women's Division I Basketball Championship is also popular), whereas the strongest European clubs participate in the EuroLeague Women.", "completion": "James Naismith: https://en.wikipedia.org/wiki/James_Naismith@@Springfield, Massachusetts: https://en.wikipedia.org/wiki/Springfield,_Massachusetts@@National Basketball Association: https://en.wikipedia.org/wiki/National_Basketball_Association@@NBA: https://en.wikipedia.org/wiki/National_Basketball_Association@@EuroLeague: https://en.wikipedia.org/wiki/EuroLeague@@Basketball Champions League Americas: https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas@@FIBA Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup@@EuroBasket: https://en.wikipedia.org/wiki/EuroBasket@@FIBA AmeriCup: https://en.wikipedia.org/wiki/FIBA_AmeriCup@@FIBA Women's Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup@@WNBA: https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association@@NCAA Women's Division I Basketball Championship: https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament@@EuroLeague Women: https://en.wikipedia.org/wiki/EuroLeague_Women"}</pre>
<p></p>
<pre># for link, name in links_wikis.items():
# display_markdown(f'### {link}', raw=True)
# display_markdown(name.summary, raw=True)
# print()</pre>
<p>Now that we have done this for one Wikipedia page, we are ready to combine all these steps into one function. This function will take a Wikipedia page as an input, and returns the JSON object as we did in the last step.
Important note on formatting prompts and responses: There needs to be a clear indication on where the prompt ends, and where the completion ends. It can be anything, and a highly unlikely text pattern to use is a good choice, for example two newlin characters following by a bunch of dollar signs.
Create a function that take a Wikipedia slug e.g. /Basketball and returns the desired JSON string
This combines all steps taken so far. In the function “ner” stands for “named entity recognition”.
</p>
<pre>prompt_end = '\n\n%%%%%\n'
completion_end = '\n\n^^^^^\n'
def wikipedia_ner(page):
wikipage = wiki_wiki.page(page)
page_links_regex = '\\b|\\b'.join(sorted(wikipage.links.keys(), key=len, reverse=True))
links_wikis = {}
for match in re.finditer(page_links_regex, wikipage.summary):
links_wikis[match.group()] = wiki_wiki.page(match.group())
ent_link = pd.DataFrame({
'entity': links_wikis.keys(),
'url': [link.fullurl for link in links_wikis.values()]})
completion = ' ' + '@@'.join([': '.join(entity) for entity in ent_link.values])
training_dict = {
'prompt': wikipage.summary + prompt_end,
'completion': completion + completion_end}
return json.dumps(training_dict)</pre>
<p>Test it again with /Basketball
Now that we have abstracted away all the steps into one command, let’s see how it works with the same page that we started with.
</p>
<pre>basketball = wikipedia_ner('Basketball')</pre>
<p></p>
<pre>print(json.loads(basketball)['prompt'])</pre>
<p></p>
<pre>Basketball is a team sport in which two teams, most commonly of five players each, opposing one another on a rectangular court, compete with the primary objective of shooting a basketball (approximately 9.4 inches (24 cm) in diameter) through the defender's hoop (a basket 18 inches (46 cm) in diameter mounted 10 feet (3.048 m) high to a backboard at each end of the court), while preventing the opposing team from shooting through their own hoop. A field goal is worth two points, unless made from behind the three-point line, when it is worth three. After a foul, timed play stops and the player fouled or designated to shoot a technical foul is given one, two or three one-point free throws. The team with the most points at the end of the game wins, but if regulation play expires with the score tied, an additional period of play (overtime) is mandated.
Players advance the ball by bouncing it while walking or running (dribbling) or by passing it to a teammate, both of which require considerable skill. On offense, players may use a variety of shots – the layup, the jump shot, or a dunk; on defense, they may steal the ball from a dribbler, intercept passes, or block shots; either offense or defense may collect a rebound, that is, a missed shot that bounces from rim or backboard. It is a violation to lift or drag one's pivot foot without dribbling the ball, to carry it, or to hold the ball with both hands then resume dribbling.
The five players on each side fall into five playing positions. The tallest player is usually the center, the second-tallest and strongest is the power forward, a slightly shorter but more agile player is the small forward, and the shortest players or the best ball handlers are the shooting guard and the point guard, who implements the coach's game plan by managing the execution of offensive and defensive plays (player positioning). Informally, players may play three-on-three, two-on-two, and one-on-one.
Invented in 1891 by Canadian-American gym teacher James Naismith in Springfield, Massachusetts, in the United States, basketball has evolved to become one of the world's most popular and widely viewed sports. The National Basketball Association (NBA) is the most significant professional basketball league in the world in terms of popularity, salaries, talent, and level of competition (drawing most of its talent from U.S. college basketball). Outside North America, the top clubs from national leagues qualify to continental championships such as the EuroLeague and the Basketball Champions League Americas. The FIBA Basketball World Cup and Men's Olympic Basketball Tournament are the major international events of the sport and attract top national teams from around the world. Each continent hosts regional competitions for national teams, like EuroBasket and FIBA AmeriCup.
The FIBA Women's Basketball World Cup and Women's Olympic Basketball Tournament feature top national teams from continental championships. The main North American league is the WNBA (NCAA Women's Division I Basketball Championship is also popular), whereas the strongest European clubs participate in the EuroLeague Women.
%%%%%</pre>
<p></p>
<pre>print(*json.loads(basketball)['completion'].split('@@'), sep='\n')</pre>
<p></p>
<pre>James Naismith: https://en.wikipedia.org/wiki/James_Naismith
Springfield, Massachusetts: https://en.wikipedia.org/wiki/Springfield,_Massachusetts
National Basketball Association: https://en.wikipedia.org/wiki/National_Basketball_Association
NBA: https://en.wikipedia.org/wiki/National_Basketball_Association
EuroLeague: https://en.wikipedia.org/wiki/EuroLeague
Basketball Champions League Americas: https://en.wikipedia.org/wiki/Basketball_Champions_League_Americas
FIBA Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Basketball_World_Cup
EuroBasket: https://en.wikipedia.org/wiki/EuroBasket
FIBA AmeriCup: https://en.wikipedia.org/wiki/FIBA_AmeriCup
FIBA Women's Basketball World Cup: https://en.wikipedia.org/wiki/FIBA_Women%27s_Basketball_World_Cup
WNBA: https://en.wikipedia.org/wiki/Women%27s_National_Basketball_Association
NCAA Women's Division I Basketball Championship: https://en.wikipedia.org/wiki/NCAA_Division_I_women%27s_basketball_tournament
EuroLeague Women: https://en.wikipedia.org/wiki/EuroLeague_Women
^^^^^</pre>
<p>Now let’s do this on a large scale.
Get a thousand Wikipedia URLs/slugs of popular pages, extract entities and links
We want to find a random list of Wikipedia URLs and get their summary text, together with the extracted entities (and their URLs). For this we will be using advertools, which is a Python package that has, among other things an SEO crawler.
We will prefer to get the data for popular Wikipedia pages. The reason is that the more popular a page, the more people will be working on editing it, and therefore the quality of the extracted entities will be better. The following code starts with the listing of the most viewed twenty five Wikipedia pages, and follows links from there. I have included comments on each line explaining a bit more about what it does.
</p>
<pre>adv.crawl(
url_list='https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report',
output_file='wiki_crawl.jl',
# for each crawled page, should the crawler follow discovered links?
# this is also known as "spider mode" as opposed to "list mode" where
# only the given URLs are crawled
follow_links=True,
# out of the disovered links, which ones should the crawler follow?
# follow links that match the following regex:
include_url_regex='https://en.wikipedia.org/wiki/[A-Z].+',
# same as the previous parameter, but for exclusion, this is to prevent
# following fragments
exclude_url_regex='#',
# further customization of the crawling process
custom_settings={
# stop crawling after a certain number of pages
'CLOSESPIDER_PAGECOUNT': 1500,
# save the logs of the crawl process in this file (good for debugging)
'LOG_FILE': 'wiki_crawl.jl',
# save the details of the current crawl job to a folder, so we can
# pause/resume the crawl without having to re-crawl the same pages again
'JOBDIR': 'wikicrawl_job'
})</pre>
<p>Crawl dataset overview:
</p>
<pre>wiki_crawl = pd.read_json('wiki_crawl.jl', lines=True)
wiki_crawl.head(3)</pre>
<p>| url | title | viewport | charset | h1 | h2 | h3 | canonical | alt_href | og:title | … | jsonld_1_author.name | jsonld_1_publisher.@type | jsonld_1_publisher.name | jsonld_1_publisher.logo.@type | jsonld_1_publisher.logo.url | resp_headers_set-cookie | request_headers_referer | h4 | img_usemap | h5 | |
| 0 | https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report | Wikipedia:Top 25 Report – Wikipedia | width=1000 | UTF-8 | Wikipedia:Top 25 Report | Most Popular Wikipedia Articles of the Week (April 16 to 22, 2023)[edit] | Exclusions[edit] | https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report | //en.m.wikipedia.org/wiki/Wikipedia:Top_25_Report@@/w/index.php?title=Wikipedia:Top_25_Report&action=edit@@/w/index…. | Wikipedia:Top 25 Report – Wikipedia | … | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | https://en.wikipedia.org/wiki/ChatGPT | ChatGPT – Wikipedia | width=1000 | UTF-8 | ChatGPT | Contents@@Training@@Features and limitations@@Service@@Reception@@Implications@@Ethical concerns@@Cultural impact@@C… | Features@@Limitations@@Basic service@@Premium service@@Software developer support@@March 2023 security breach@@Other… | https://en.wikipedia.org/wiki/ChatGPT | //en.m.wikipedia.org/wiki/ChatGPT@@/w/index.php?title=Special:RecentChanges&feed=atom | ChatGPT – Wikipedia | … | Contributors to Wikimedia projects | Organization | Wikimedia Foundation, Inc. | ImageObject | https://www.wikimedia.org/static/images/wmf-hor-googpub.png | WMF-DP=46f;Path=/;HttpOnly;secure;Expires=Mon, 01 May 2023 00:00:00 GMT | https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report | NaN | NaN | NaN |
| 2 | https://en.wikipedia.org/wiki/Wikipedia:Humor | Wikipedia:Humor – Wikipedia | width=1000 | UTF-8 | Wikipedia:Humor | Contents@@Humor needs indicators[edit]@@Why responsible humor is important[edit]@@Humor in articles[edit]@@Humor out… | How humor can be included[edit] | https://en.wikipedia.org/wiki/Wikipedia:Humor | //en.m.wikipedia.org/wiki/Wikipedia:Humor@@/w/index.php?title=Wikipedia:Humor&action=edit@@/w/index.php?title=Specia… | Wikipedia:Humor – Wikipedia | … | NaN | NaN | NaN | NaN | NaN | NaN | https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report | NaN | NaN | NaN |
3 rows × 107 columns
Extract URL slugs from crawled pages.
</p>
<pre>wikipedia_slugs = wiki_crawl[~wiki_crawl['url'].str.contains('[a-zA-Z]:[a-zA-Z]')]['url'].str.rsplit('/').str[-1].tolist()
wikipedia_slugs[:30]</pre>
<p></p>
<pre>['ChatGPT',
'Mario',
'Netflix',
'GPT-3',
'Language_models',
'LLaMA',
'Meta_AI',
'Bard_(chatbot)',
'Ambedkar_Jayanti',
'The_Greatest_Indian',
'The_Matrix',
'Dalai_Lama',
'Academic_plagiarism',
'Hyderabad',
'B._R._Ambedkar',
'Bon_Jovi',
'Mahatma_Gandhi',
'Mario_Bros.',
'Satoru_Iwata',
'San_Diego_Comic-Con',
'A_Perfect_Crime_(TV_series)',
'If',
'V_Wars',
'When_They_See_Us',
'AJ_and_the_Queen',
'Unbelievable_(miniseries)',
'Trinkets_(TV_series)',
'Trailer_Park_Boys:_The_Animated_Series',
'Twelve_Forever',
'Turn_Up_Charlie']</pre>
<p>Go through the slugs, and extract entities and links
</p>
<pre>entity_responses = []
errors = []
for i, slug in enumerate(wikipedia_slugs):
try:
print(f'{i:>4}Getting: /{slug}', end='\r')
wikipage = wikipedia_ner(slug)
entity_responses.append(wikipage)
except Exception as e:
err = (slug, str(e))
errors.append(err)
print('Error: ', err)</pre>
<p>Create the training file
</p>
<pre>with open('training_data_wikipedia_ner.jsonl', 'w') as file:
for resp in entity_responses:
prompt = json.loads(resp)['prompt']
completion = json.loads(resp)['completion']
if prompt:
print(json.dumps({'prompt': prompt, 'completion': completion}), file=file)</pre>
<p>With this, our training model is ready, which is a simple set of prompt/completion pairs that can be uploaded and used with ChatGPT.
You can test it out on this live entity extraction app, and see how it works.





