



In this article, we’ll show you a simple, effective way to bypass CAPTCHAs while scraping Amazon product data, allowing you to gain a competitive advantage in your industry.
But before we jump into the code, you first need to understand what they are.
What are CAPTCHAs?
CAPTCHA is an acronym for Completely Automated Public Turing test to tell Computers and Humans Apart. In other words, it’s a test designed to determine if a user accessing a website is a human or a bot.
The CAPTCHA protects the website from abuse, such as:
- Spamming comment forms, contact forms, and sign-up pages, to mention a few
- Harmful, not compliant scraping bots
- Automated bots attempting to use stolen or leaked usernames and passwords
- Automated purchase of goods using stolen credit card information
And many more “blackhat” practices.
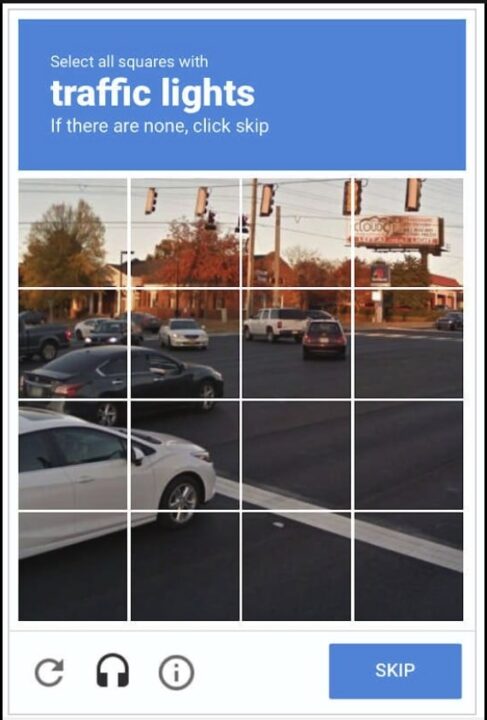
The efficiency of the CAPTCHA test comes from the fact that challenges are easy to solve for humans and difficult for computers. Some examples of CAPTCHA tests are:
- Text-based CAPTCHA: Identify stretched text containing letters and numbers.
- Image-based CAPTCHA: Identify similar pictures among a grid of pictures by clicking on their location in the grid.
- Audio-based CAPTCHA: Listen to the audio and transcribe the output in a text input. It is helpful for users having difficulty with visual challenges.
- Social media login: It is less common, but they must authenticate with one of their social media accounts.
How CAPTCHAs Prevent Web Scraping
Web scraping is a data collection technique consisting of automatically extracting information from a website.
However, not all web scrapers are built equally.
As alternative data becomes more valuable, more people are trying to get access to it through automation.
The problem is that, in a lot of cases, scrapers are not configured correctly, harming their targeted websites by, for example, overloading the server, making them unable to serve requests coming from real users and thus altering the end-user experience.
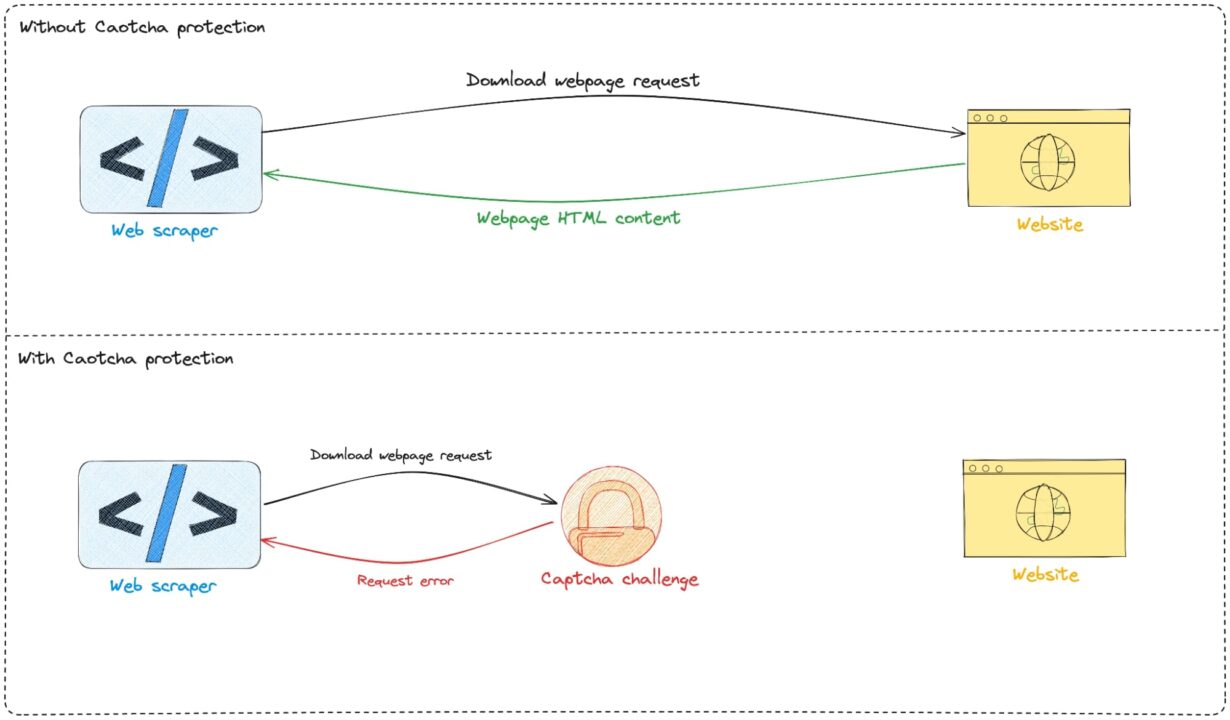
To protect themselves from bot abuse, many websites rely on CAPTCHA tests that are difficult to solve for most bots because they require Human interaction. This makes it impossible for bots to access the site, as they cannot interpret and solve these challenges effectively.
When are CAPTCHA Tests Triggered on Amazon?
Here are some patterns that trigger a CAPTCHA test:
- Higher than average clicking rate
- The IP address used exists in a database of blacklisted IP addresses
- The client doesn’t load CSS, JavaScript, or images
- The client loads the same pages many times without navigating to other pages from time to time
- The client makes multiple unsuccessful login attempts in a short period of time
- High request frequency or very consistent request pattern (a request every 10 seconds using the same IP)
There are many other ways Amazon can tell a bot is accessing their site – in most cases, without proper IP rotation, you won’t even be able to get the initial successful request.
So, what should you do? Coding a behavior for every potential scenario is not only time consuming but almost impossible. It’s just a metter of time for your scrapers to get blocked.
The good news is you don’t need to create this solution from scratch.
Preventing Amazon CAPTCHAs with ScraperAPI
Being the most visited e-commerce website in the world and having a large database of products, Amazon uses CAPTCHAs to prevent bot activities and data Web scraping.
For Web Scrapers, solving the Amazon CAPTCHA test in a reasonable time is essential.
ScraperAPI helps by providing a simple, yet powerful API for bypassing CAPTCHAs with a near 100% success rate, giving you access to data in a matter of seconds.
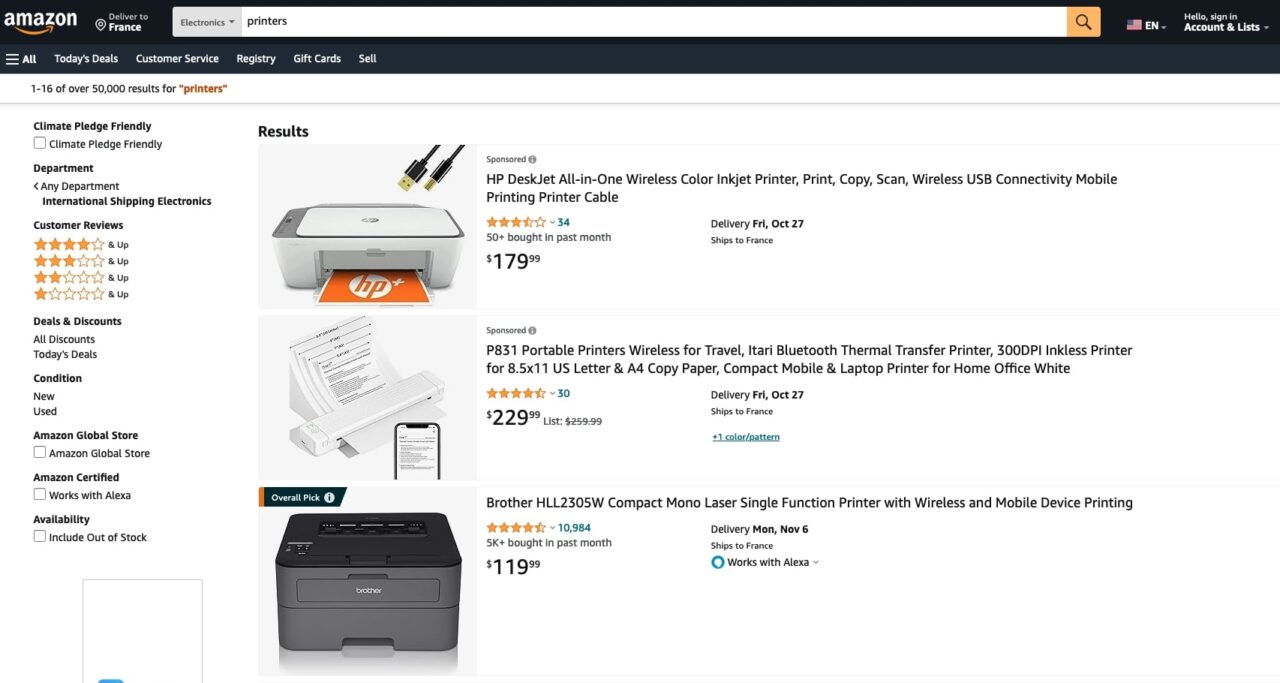
For this tutorial, we’ll use ScraperAPI’s standard API and Node.js to scrape the page below.
Prerequisites
You must have these tools installed on your computer to follow this step.
- Node.js 18+ and NPM – Download link
- Knowledge of JavaScript and Node.js API
- A ScraperAPI account – create an account and get 5,000 free API credits to get started
Set Up the Project
Let’s create the folder and initialize a new Node.js project.
mkdir amazon-captcha-bypass
cd amazon-captcha-bypass
npm init -y
touch index.js
Send Your Request Through ScraperAPI
The ScraperAPI standard API is accessible at https://api.scraperapi.com.
To send the request to the standard API, we’ll use Axios, so let’s install it first:
npm install axios
Open the index.js file and add the code below:
const axios = require('axios');
const AMAZON_PAGE_URL = 'https://www.amazon.com/s?crid=2S8Z5MXHF5A2&i=electronics-intl-ship&k=printers&ref=glow_cls&refresh=3&sprefix=printers%2Celectronics-intl-ship%2C174';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = 'YOUR_API_KEY' // <--- Enter your API key here
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: AMAZON_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}/?${queryParams.toString()}`);
const html = response.data;
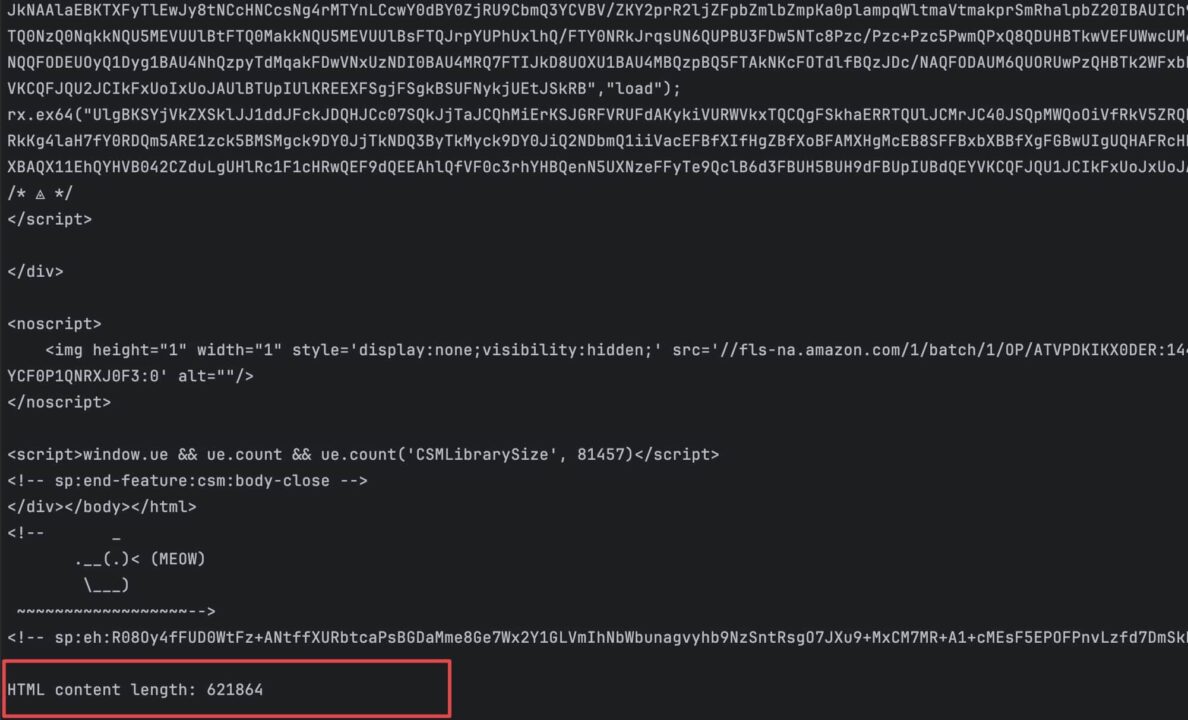
console.log(html);
console.log("HTML content length: %d", html.length);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
Note: Remember to add your API key. You can find it in your ScraperAPI dashboard.
Run the command node index.js to run the code. You will get a similar output to the one below:
When the API receives the request, it uses machine learning and statistical analysis to determine the best combination of IPs and headers to prevent triggering Amazon’s CAPTCHA test.
In case the Amazon product or search page sends the CAPTCHA test, ScraperAPI will generate a new combination of IP address and Headers to make a new request and will do so until it succeeds or reaches the maximum time defined for the execution.





