

Challenges of large-scale Amazon scraping
Like every other business, Amazon tries to prevent unauthorized data extraction using advanced techniques to protect its data. These techniques include:
1. IP Blacklisting
There is a high chance that when scraping, you will need to make multiple requests to obtain data for multiple page types on Amazon. Unfortunately, Amazon will detect this action, blacklist, and block your IP address for suspicious activity or making too many requests in a short period.
2. Rate Limiting
Whenever Amazon discovers your IP address is sending too many requests within a particular time frame, it automatically flags your address. This is because you have exceeded the number of requests you can make within a timeframe. Exceeding these limits leads to delays or temporary blocks from accessing their site.
3. CAPTCHA Systems
When visiting some websites, you might have noticed a pop-up asking you to prove you are human. Most of these are called CAPTCHAs. Amazon uses CAPTCHAs to verify that visitors are human and prevent bot-like activities. These checks add a layer of complexity, making it difficult for bots to scrape data successfully.
Although some challenges might seem simple to you, mimicking a person’s behavior while resolving the CAPTCHA, and resolving the CAPTCHA challenge itself programmatically, is quite a tough endeavor.
4. Machine Learning-Based Bot Detection
For Amazon to successfully detect a bot, it uses machine learning to analyze user behavior patterns to differentiate between humans and bots. Once an unusual activity is detected, the bot is automatically restricted from extracting data.
Why Do You Need Proxies to Scrape Amazon at Scale?
To successfully scrape data from Amazon at a large scale, you need either a proxy or a dedicated scraping tool.
A proxy is a middleman between your device and the internet. It works by sending your requests through its own IP address to the website you want to visit. When the website responds, the proxy sends the data back to you.
Proxies play a major role in ensuring continuous access to data by masking your true IP address and evading detection. Specifically, residential proxies are effective for this purpose, as they blend in with regular traffic by using IP addresses assigned by the Internet Service Providers (ISPs) to real users. This makes it harder for Amazon to detect and block them, allowing for better data extraction.
Of course, you’ll need more than one IP address. The best approach is to use rotating residential proxies to distribute the workload through thousands or even millions of IPs, making it harder for Amazon’s bot blockers to identify your scraper.
Top Proxy Providers for Large-Scale Amazon Scraping
To pick the five best proxy providers for high-volume Amazon scraping, we’ve decided to take into account factors like:
- Specific tools and features geared toward scraping Amazon
- Bypassing capabilities
- Rating scores (G2 or Trustpilot)
- Pricing
Before diving into each proxy provider, here’s a quick overview for those in a hurry:
| Provider | Proxy Type | Pool Size | Success Rate | Process | Pricing | Additional Features | Ratings |
| ScraperAPI | Full Scraping Tool (Residential/Mobile/Datacenter) | 40M+ | 99%+ | Automated |
$/successful request | CAPTCHA Handling, Machine Learning (ML) | G2 – 4.27 Trustpilot – 4.7 |
| ProxyRack | Residential/Datacenter | 2M+ | 96% | Manual | $5/GB | Unlimited Bandwidth, Simple Setup | G2 – Nill Trustpilot – 3.9 |
| ProxyLite | Residential/Datacenter | 72M+ | 95% | Manual | $1.20/GB | Affordable Pricing | G2 – Nill Trustpilot – 4.6 |
| Soax | Residential | 151M+ | 99% | Manual | $2.2/GB | Clean IP Pool | G2 – 4.8 Trustpilot – 4.7 |
| SmartProxy | Residential/Datacenter | 65M+ | 99.99% | Manual | $2.2/GB | Chrome Proxy Extension | G2 – 4.6 Trustpilot – 4.6 |
| ProxyEmpire | Residential/Datacenter | 100M+ | 99.9% | Manual | $3/GB | Over 9.5M+ IPs | G2 – 5.0 Trustpilot – 4.7 |
1. ScraperAPI (best proxies and tools for large Amazon scraping projects)

To effectively scrape Amazon on a large scale, you need an all-in-one automated tool because it saves you time and allows you to focus on other tasks. This is where ScraperAPI excels.
ScraperAPI is an all-in-one web scraping tool designed to handle the complexities of scraping websites like Amazon on a large scale with minimal setup. Unlike other proxy services, ScraperAPI goes further by automating the entire scraping process, so you don’t have to manage the infrastructure yourself.
ScraperAPI stands out as the top proxy provider for large-scale Amazon scraping for two important reasons:
1. Dedicated Amazon structured data endpoints (SDEs)
ScraperAPI’s Amazon SDEs are dedicated endpoints designed to turn Amazon product, search, and review pages into ready-to-use JSON or CSV.
With a single API call, you can scrape details like:
- Product details like name, pricing, number of reviews, etc.
- Shipping information
- Search rankings
- Product searches
- Product reviews
- Multiple offers for the same product,
And more, by submitting a search query or product ID (based on the SDE you’re using) alongside your GET request.
Want to test our Amazon endpoint? Create a free ScraperAPI account to get access to your API key, and copy the code snippet below to see ScraperAPI in action:
import requests
import json
payload = {
'api_key': 'YOUR_API_KEY', #add your API key here
'query': 'drawing pencils',
'country': 'us'
}
#send your request to scraperapi
response = requests.get(
'https://api.scraperapi.com/structured/amazon/search', params=payload)
products = response.json()
#export the JSON response to a file
with open('amazon-products.json', 'w') as f:
json.dump(products, f)
2. DataPipeline Amazon scraping scheduler
DataPipeline is ScraperAPI’s built-in scraping scheduler. It allows you to automate the entire scraping process from beginning to end using a visual interface or dedicated DataPipeline endpoints. These endpoints let you create, schedule, and manage hundreds of scraping projects programmatically without logging in to your dashboard.
What makes this tool even better is its integration with ScraperAPI’s Amazon SDEs. Using these tools, you can set recurrent Amazon scraping jobs to monitor product pages, search results, product reviews, and more without spending hundreds of hours building or maintaining complex infrastructures and parsers.
You can access your extracted data in formats like JSON, CSV, or via Webhooks, making it easy to integrate into your project.
Main Features
- Machine learning: ScraperAPI uses machine learning and statistical analysis to choose the best proxy per request, generating headers and cookies to match the IP address and handle other complexities to ensure a high success rate.
- Captcha handling and bypassing anti-bot mechanisms: ScraperAPI automatically handles CAPTCHAs by preventing them from being triggered – retrying requests that trigger a CAPTCHA challenge – and bypasses Amazon’s anti-bot mechanisms without extra configurations.
- Geo-targeting: ScraperAPI supports geo-targeted proxies, allowing you to access region-specific Amazon data and simulate user requests from different geographic locations.
- JS rendering: Enables scraping of websites with dynamic content by rendering JavaScript to capture fully loaded pages – most recently, it also offers the ability to interact with dynamic sites using rendering instruction sets.
- Automated retries: Automatically retries failed requests to ensure high success rates and reduce manual intervention.
- Premium proxy pool: Utilizes a high-quality pool of residential, mobile, and datacenter proxies for maximum reliability and lower chances of detection.
- Desktop and mobile user agents: Allows you to rotate between desktop and mobile user agents, mimicking real-world browsing behavior for more accurate data extraction.
Pricing
ScraperAPI uses a straightforward pricing model based on successful requests, offering more predictability and scalability compared to providers that charge by bandwidth or GB.
The number of credits consumed depends on the domain, the level of protection on the website, and the specific parameters you include in your request.
In the case of Amazon, being an ecommerce platform, ScraperAPI charges 5 API credits per successful request, making it simple to calculate the number of pages you can scrape with your plan:
| Plan | Pricing | API Credits | Successful Amazon Requests |
| Free Trial [7 – days] | – | 5000 | 1,000 |
| Hobby | $49 | 100,000 | 20,000 |
| Startup | $149 | 1,000,000 | 200,000 |
| Business | $299 | 3,000,000 | 600,000 |
| Enterprise | Custom | Custom | Custom |
Note: Visit the ScraperAPI Credits and Requests page to see credit usage in detail.
2. ProxyRack [reliable, fast & quality proxies]

ProxyRack is a reliable proxy provider that provides you with a range of proxy services, including residential and datacenter proxies, making it a good option for scraping large data from sites like Amazon. It doesn’t just provide proxies for scraping; it also offers proxies for various industries and use cases, such as:
- Gaming
- Ad verification
- Multilogin
- SEO Monitoring
- Price aggregation and comparison
This broad applicability makes ProxyRack a flexible solution for both simple and complex scraping tasks across industries.
Main Features
- Unmetered bandwidth: ProxyRock allows unrestricted data usage without bandwidth limitations, making it ideal for high-volume scraping.
- Residential and datacenter proxies: Unlike other proxies, ProxyRack provides you the flexibility to choose between residential (better for anonymity) and datacenter (faster > 0.6 seconds, more affordable) proxies.
- Geo-targeting: ProxyRack geo-targeting would be useful when your task requires you to scrape data from a specified location.
- Rotating proxies: ProxyRack offers you a large pool of over 2 million IPs across 140 locations, ideal for large-scale data extraction and crawling
- Flexible pricing plans: ProxyRack offers you a range of pricing options based on bandwidth, number of ports, or concurrent threads, making it convenient for both small and large-scale projects.
Pricing
If you need flexible proxy services with high bandwidth and concurrent threads, especially for targeting Amazon from multiple geographic locations, ProxyRack stands out as the most cost-effective option – only surpassed by ScraperAPI’s offerings.
Although, in a lot of cases, it’s hard to compare per-usage pricing models, ProxyRack offers a simple tool to calculate the cost of using residential proxies in your project.
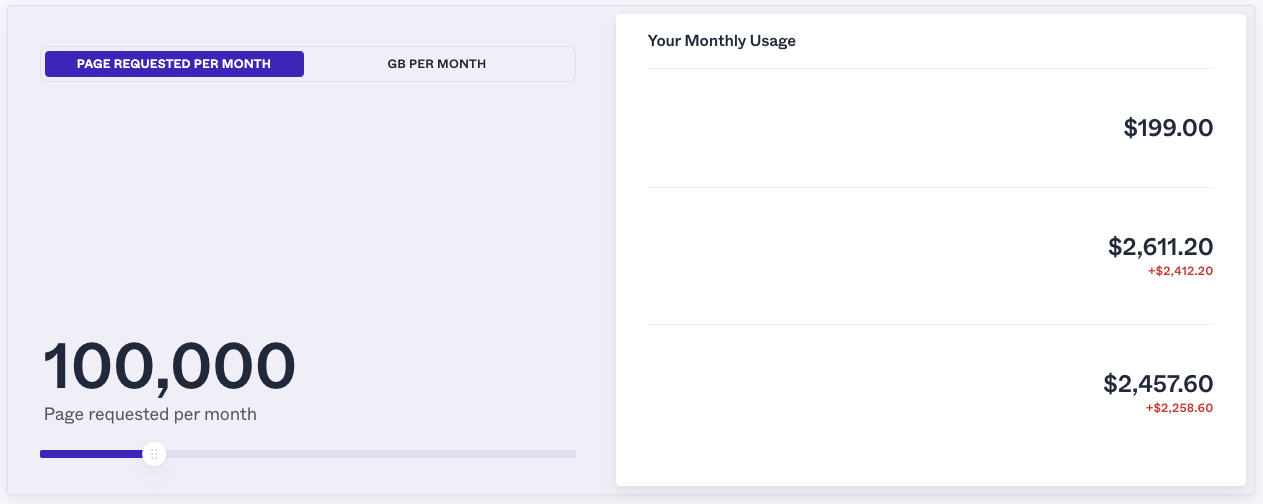
However, the tool jumps from 100k requests to 1M requests, so we’ll need to stay at the 100k successful requests range.
When using ProxyRack, you’d be paying $199/month to scrape up to 100,000 pages, while ScraperAPI’s $149/month plan would allow you to scrape up to 200,000 Amazon pages.
Note: This is just an estimation based on ProRack’s tool. However, it’s not clear what the other two numbers ($2,611 and $2,457) mean, as they are not referred to in their documentation.
3. ProxyLite [competitive pricing and customizable plans]

Another proxy provider to consider when trying to extract data from Amazon is ProxyLite, a commercial residential and Static (ISP) Residential proxy provider that prioritizes privacy and performance. It ensures anonymity and reduces ban risk, making it ideal for secure and reliable web activity.
Features
- Residential proxies: ProxyLite provides you access to a large pool of residential IP addresses, offering high anonymity and reducing the risk of detection.
- Static residential proxies: You may have come across tasks that require stable and long-term IPs, ProxyLite static residential proxies provide you with consistent IP addresses from residential networks that remain static and allow you to scrape data effortlessly.
- Global IP coverage: With ProxyLite you have access to a network of over 72 million IP addresses across various locations worldwide, enhancing geographic diversity and access to public data.
- Easy integration: ProxyLite provides you with ready-to-use endpoints and APIs that simplify the integration process with existing systems and applications.
Pricing
ProxyLite pricing model is based on data usage (GBs). This makes it more expensive for large-scale projects like Amazon scraping, compared to ScraperAPI.
| Plan | Pricing |
| Residential Proxy | From $4 Per Month($1.20/GB) |
| ISP Proxy | From $5.50/IP |
| Unlimited Residential Proxies | From $68.79 Per Day |
4. Soax [clean residential proxy pool]

Soax is a proxy provider with different proxy types, including residential, mobile, datacenter, and US ISP proxies. Soax datacenter proxies offer major advantages in speed, uptime, and scalability, making them suitable for large-scale Amazon scraping.
Features
- Clean residential proxy pool: Soax gives you access to a constantly refreshed pool of residential IPs, ensuring high anonymity and reducing the risk of bans or blocks.
- US ISP proxy: For projects where you need to use one IP for a long period of time, Soax provides reliable static IPs from US-based ISPs for consistent and trustworthy connections.
- Mobile proxies: Soax provides you with mobile proxies that rotate through real mobile IPs to simulate genuine mobile traffic, ideal for location-specific tasks.
- Datacenter proxies: High-speed and cost-effective proxies for tasks that require fast and efficient data extraction.
- Web unlocker: With Soax web unlocker, bypassing CAPTCHAs and other anti-bot measures becomes easy, enabling unrestricted access to even the most protected websites – however, it doesn’t offer any dedicated endpoints for Amazon.
Pricing
Amazon’s advanced anti-scraping systems make it hard for scrapers to collect data at scale using datacenter proxies, as these will easily be identifiable, getting your scraper blocked.
For large-scale Amazon projects, consider that you’ll need to work primarily with residential and mobile proxies (having mobile proxies as a default to avoid overspending).
In this scenario, ScraperAPI’s smart proxy rotation makes it more affordable and easy to use, as it automates the entire process for you and keeps the fixed 5 API credits per successful request structure.
Here’s the cost breakdown for Soax’s residential plans:
| Plan | Traffic | Pricing/month |
| Residential 15 | 15GB | $99 |
| Residential 29 | 29GB | $179 |
| Residential 65 | 65GB | $369 |
| Residential 15 | 150GB | $739 |
6. SmartProxy [24/7 customer support]
Another ideal proxy for scraping Amazon is SmartProxy, thanks to its ecommerce Scraping API, which integrates proxies with a web scraper and parser, ensuring a high success rate for extracting product data, prices, and reviews efficiently.
Features
- Residential and datacenter proxies: Like any good proxy, SmartProxy provides a vast pool of residential IPs and datacenter proxies for reliable, undetectable scraping across various sites, including ecommerce platforms.
- 24/7 customer support: Unlike competitors, SmartProxy offers free round-the-clock customer support to assist you with any proxy-related issues even if you subscribe to its lowest package.
- Unlimited connections and threads: You can run an unlimited number of concurrent connections and threads, making it ideal for large-scale scraping projects.
- Ecommerce scraping API: SmartProxy API is specifically tailored for scraping large websites like Amazon, combining web scrapers and parsers with proxy management to ensure a high success rate.
- Rotating proxies: SmartProxy gives you an automatic IP rotation that allows you to send multiple requests from different IPs, preventing blocks and throttling during scraping.
Pricing
SmartProxy’s pricing model is relatively competitive, especially for residential proxies, with several plans to accommodate different data usage levels.
For example, Pay-As-You-Go pricing for residential proxies is flexible if you need proxies on-demand without a long-term commitment.
That said, SmartProxy’s ecommerce API has a very clear pricing structure based on 1K requests – paying only for successful requests:
| Plan | Cost/1k Requests | Pricing/month |
| 15k Requests | $2 | $30 |
| 50k Requests | $1,60 | $80 |
| 100k Requests | $1,40 | $140 |
| 250k Requests | $1,20 | $300 |
As you can see, after getting to 250,000 requests per month, SmartProxy becomes more expensive than ScraperAPI – which lets you scrape up to 600,000 Amazon pages for $299. This gap would only increase the larger the project.
Still, it’s a good choice for companies working on small projects.
7. ProxyEmpire [allows rollover of unused data]
Another top proxy for large-scale Amazon scraping worth mentioning is ProxyEmpire. It has a different selection of proxies, including rotating residential, static residential, and mobile proxies, designed to meet a range of data collection.
Their rotating residential proxies span over 170 countries with a large pool of IPs and high success rates, making them suitable for tasks like web scraping, price monitoring, and SEO.
They also provide dedicated mobile proxies for specific needs and datacenter proxies for cost-effective, simple tasks – although these are not suited for large Amazon scraping projects.
Features
ProxyEmpire offers several key features tailored to various online activities like web scraping, ad verification, and price monitoring. Here are its main features:
- Rotating residential proxies: ProxyEmpire offers over 9 million rotating residential IPs in more than 170 countries, with geographically precise targeting options by country, region, city, or ISP, making it ideal for tasks that require high levels of localization.
- Static residential proxies: ProxyEmpire has static residential proxies that are available in over 20 countries, making them ideal if you need a dedicated, stable residential IP for extended use.
- Rotating mobile proxies: ProxyEmpire offers over 5 million mobile IPs with 4G and 5G options, providing accurate mobile carrier targeting for more flexibility in tasks such as ad verification and social media automation.
- Rotating datacenter proxies: ProxyEmpire offers you a budget-friendly solution for simpler scraping tasks, with over 40k+ IPs across 10+ countries.
Pricing
Just like other proxy services, ProxyEmpire provides a range of pricing plans for residential and mobile proxies, based on GB and bandwidth usage. One unique thing about ProxyEmpire is its rollover bandwidth feature, allowing unused data to carry over to the next billing cycle, which adds value for users with fluctuating data needs.
| Plan | Pricing |
| Rotating Residential Proxies | From $3/GB |
| Static Residential Proxies | From $2/IP and $3/GB |
| Rotating Mobile Proxies | From $8/GB |
| Dedicated Mobile Proxies | From $125/month |
| Rotating Datacenter Proxies | From $0.35 per GB |
Note: For large Amazon scraping, you’ll want to use rotating residential proxies with rotating mobile proxies as a default in case of multiple failed requests.
Choosing the Right Proxies for Large-Scale Amazon Scraping
Choosing the right proxy for a project like large-scale Amazon scraping is important because It saves you time and can make your task easier. Here are some key features to look for to help you make the right decision:
- Proxy pool size and rotation: Your proxy should automatically and frequently rotate IP addresses. Doing IP rotations can help you minimize the risk of detection and ensure you stay within the rate limits. With a large pool, you have more proxy options to rotate through, giving you a better chance of bypassing detection systems.
- CAPTCHA handling: When scraping Amazon, a good proxy or scraping tool must avoid triggering captchas to ensure smooth data extraction. ScraperAPI handles captcha by automatically preventing captchas from appearing in the first place.
- Request retries: In case of temporary blocks or errors, your proxy should be able to retry failed requests. This way, you can perform continuous and reliable scraping of site data.
- Success rate and speed: The ideal proxy solution should offer a high success rate for requests while minimizing downtime. Fast proxies ensure efficient data extraction without unnecessary delays. This is even more important for large-scale projects, as a small delay at a scale of millions of requests can become hours or even days of lost time.
- Pricing models: Proxy providers offer different pricing models, such as charging per GB or successful request. The right choice depends on the scale of your scraping project, with per-successful-request pricing often proving more cost predictability for large-scale operations.
- Geolocation support: When trying to extract location-specific data, you need a proxy with geolocation capabilities that allow you to access region-specific Amazon data. For example, if you want to compare competitor product pricing across multiple countries.
- Additional features: A good proxy solution should offer advanced features like built-in CAPTCHA solving, session management, and easy-to-use proxy management tools. These features ensure a smoother, more efficient scraping process with minimal manual intervention.
Understanding your need for these features is the easy part. Building it is where things become complex and time-consuming for you. You can save time and stress by using an already-built tool like ScapperAPI with all the features you need to scrape Amazon at large effortlessly.
To get started, create a free ScraperAPI account to access your API key and receive 5,000 API credits for a seven-day trial, starting whenever you’re ready.
Wrapping Up: Why ScraperAPI is the Best Solution for Amazon Web Scraping
ScraperAPI stands out as the best solution for scraping Amazon because it simplifies the entire scraping process by providing a complete, automated package.
Unlike other proxy services that require you to manage complex scraping infrastructure, ScraperAPI handles everything, allowing you to focus on data extraction without worrying about technical complexities.
Let’s dive into the main reasons you should consider ScraperAPI for your next project:
1. Success rate and reliability
ScraperAPI offers one of the highest success rates in the industry due to its advanced features. By automatically rotating proxies, managing CAPTCHA challenges, and retrying failed requests, ScraperAPI ensures uninterrupted Amazon data extraction.
2. Cost-effectiveness for large-scale operations
ScraperAPI has a simple pricing model that charges per successful request rather than per GB, making costs easy to manage and forecast. You don’t have to worry about bandwidth usage or unexpected costs. ScraperAPI’s predictable pricing allows for better budget planning and scalability without compromising performance.
3. Automates the entire process
Besides retries, CAPTCHAs, and IP rotation, ScraperAPI further streamlines Amazon scraping by reducing the need to build and maintain complex parsers thanks to its Amazon structured data endpoints (SDEs). These endpoints let you collect Amazon data in JSON or CSV format, reducing data cleaning time.
At the same time, its built-in scheduler (DataPipeline) makes it easy to schedule and manage recurrent scraping jobs in a couple of minutes, letting you set custom intervals.
4. Machine learning optimization
ScraperAPI uses machine learning to enhance scraping efficiency by analyzing and optimizing each request. It adjusts proxies, headers, cookies, and retries based on real-time conditions to maximize success rates and minimize detection. ScraperAPI’s machine learning capability ensures efficient use of resources, reducing the chances of being blocked and increasing the speed of data collection.
5. Full-scale solution
ScraperAPI provides an entire scraping infrastructure. Unlike typical proxy providers, ScraperAPI automatically manages all aspects of the scraping process, including proxy rotation, CAPTCHA solving, request retries, user-agent management, parsing, and more, allowing you to scrape Amazon at scale without the need for complex setups or third-party tools.




