


TL;DR: Google Maps Python Scraper
For those in a hurry, here’s the full code for the scraper we’ll build in this article. This code uses Selenium with ScraperAPI in proxy mode to scrape business data from Google Maps’ search results:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
# Selenium Wire configuration to use a proxy
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
# URL of the web page
url = "https://www.google.com/maps/search/pizza+in+new+york"
# Open the web page
driver.get(url)
try:
button = driver.find_element(By.XPATH,'//*[@id="yDmH0d"]/c-wiz/div/div/div/div[2]/div[1]/div[3]/div[1]/div[1]/form[2]/div/div/button/div[3]')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
# Set an implicit wait time to wait for JavaScript to render
driver.implicitly_wait(30) # Wait for max 30 seconds
# Scrolls within a specific panel by simulating Page Down key presses.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
# Find the panel element
panel_element = driver.find_element(By.XPATH, panel_xpath)
# Ensure the panel is in focus by clicking on it
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
# Send the Page Down key to the panel element
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
# Get the page HTML source
page_source = driver.page_source
# Parse the HTML using BeautifulSoup
soup = BeautifulSoup(page_source, "lxml")
# Find all elements using its class
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
# Print the number of places found
elements_count = len(titles)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'maps_pizza_places.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(['Place', 'Rating', 'Reviews', 'Service options'])
# Write the extracted data
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings[i].text + "/5") if i < len(ratings) else 'N/A' # Ensure we have a rating and reviews for each title, default to 'N/A' if not found
review_count = reviews[i].text if i < len(reviews) else 'N/A'
service = services[i].text if i < len(services) else 'N/A'
# Write a row to the CSV file
if title:
csv_writer.writerow([title, rating, review_count, service])
print(f"Data has been saved to '{csv_file_path}'")
# Release the resources and close the browser
driver.quit()
Note: Replace 'YOUR_SCRAPERAPI_KEY' with your unique API key from your ScraperAPI dashboard. Don’t have an account? Sign up today and get 5000 free scraping credits to start scraping data in minutes!
This code will scrape business names, ratings, review counts, and service options for pizza places in New York off Google Maps and save the data to a CSV file.
Scraping Google Maps with Python and Selenium [Headless Approach]
One way to retrieve Google Maps data is via the official API, but this method has several downsides. Getting the API key is complex as you need to set up a Google Cloud project. Its limitations include data access restrictions, query limits, and potential costs associated with high-volume usage.
Developing your own Google Maps scraping tool might be a big challenge if you don’t have a few years of experience behind you. You will need to be prepared for plenty of challenges from Google, including IP protection (proxies), cookies and sessions, browser emulation, site updates, etc.
Fortunately, there are some good third-party tools we can employ. We’ll use Selenium to interact with Google Maps just like a real user. Our target will be Google Maps results for restaurants in New York that serve pizza. To handle proxy management, JavaScript rendering, and bypass Google Maps’ anti-scraping mechanisms, we’ll integrate ScraperAPI into our setup.
Requirements To Scrape Google Maps Reviews and Ratings
To follow this tutorial, ensure you have the following tools installed on your computer:
- Python: Download and install the latest version of Python from the official website.
- Google Chrome Browser.
- Libraries: Install the required Python libraries using pip:
pip install selenium selenium-wire webdriver-manager beautifulsoup4 lxml
This installs:
- Selenium: Used to automate web browser interaction with Python
- Selenium Wire: A powerful extension for Python Selenium that gives you access to the underlying requests made by your Selenium browser. Useful for proxy integration.
- Webdriver Manager: Simplifies management of binary drivers for different browsers.
- BeautifulSoup: Parses HTML and XML data.
- LXML: An XML parsing library often used alongside BeautifulSoup for improved speed and performance.
You’ll also need a ScraperAPI account. If you don’t have one, you can sign up here to obtain an API key to authenticate your requests.
Google Maps Layout Overview
Before we start scraping, we need to understand where and in what form the data is. For this article, we will attempt to scrape for “pizza in New York.”
Clicking on any listing or the map will lead you to the main Google Maps interface. Here, you’ll see that all the search results are listed on the left panel, with more detailed map information displayed on the right.
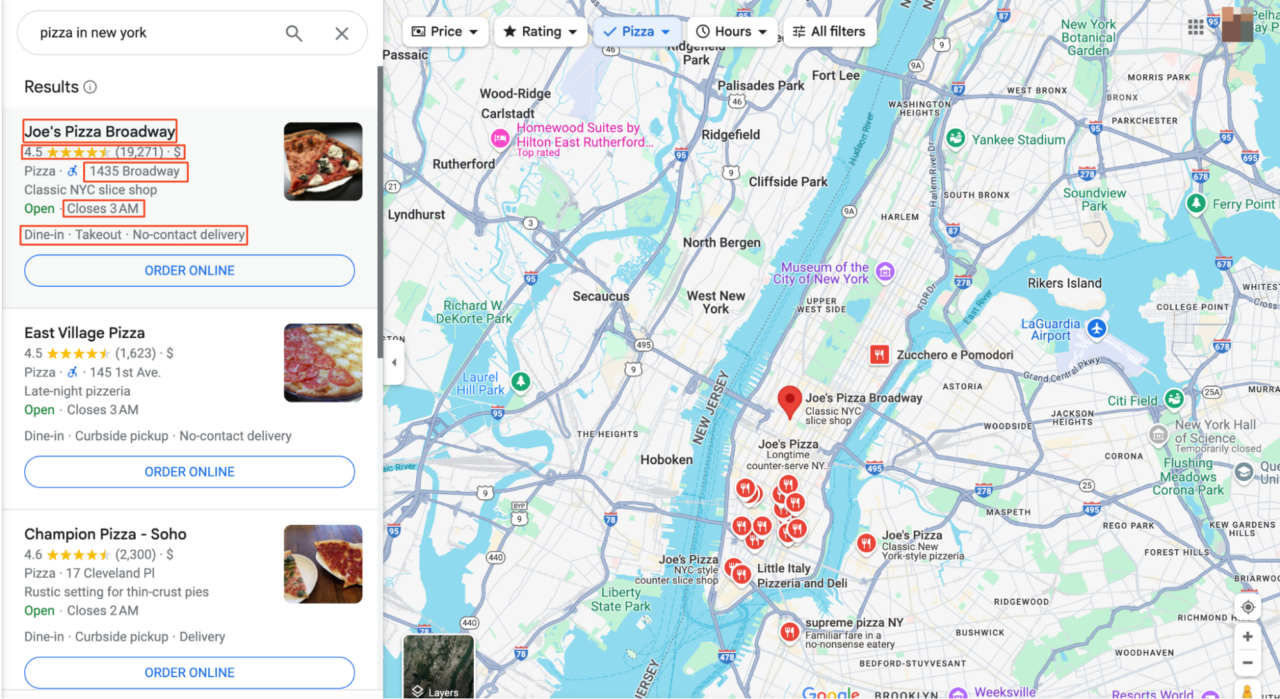
To identify which parts of the page contain the information we need, open DevTools (F12, or right-click on the page and select “Inspect“). Using the DevTools, you can hover over different parts of the webpage to see the corresponding HTML elements.
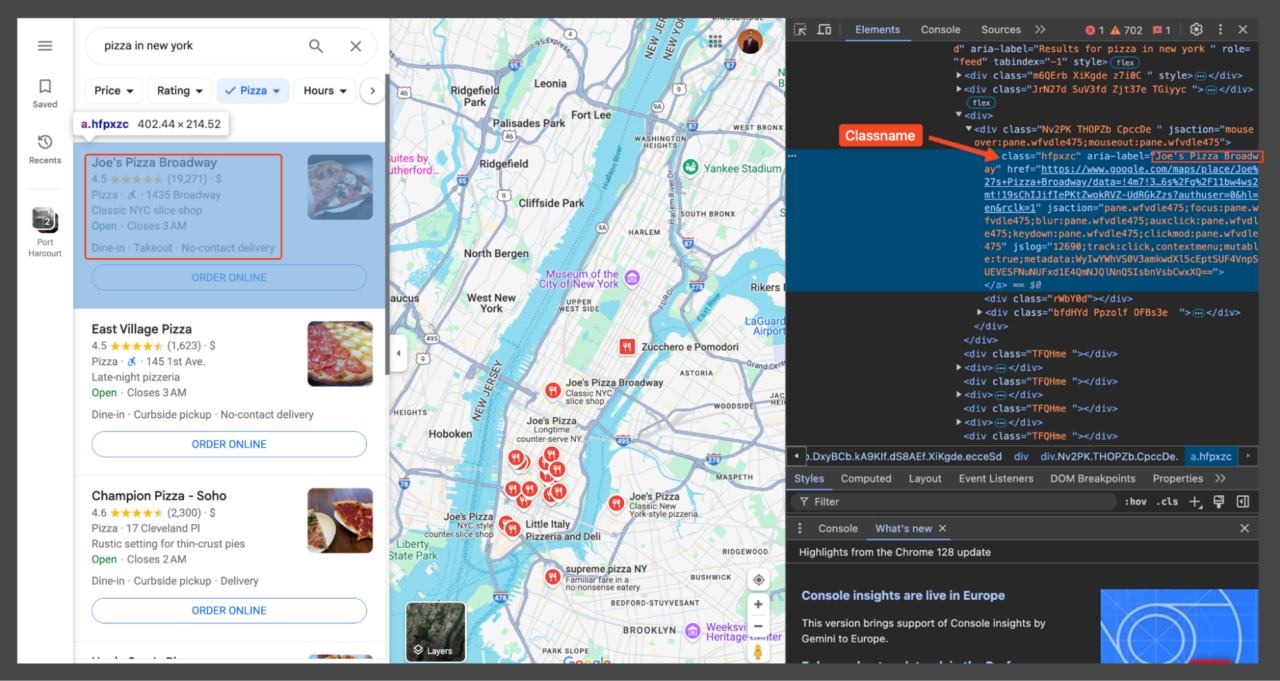
Each element on the page can be targeted using CSS selectors. For instance, the place titles (e.g., “Joe’s Pizza”) are typically wrapped within an element with a specific class (hfpxzc). Then, we’ll use Beautiful Soup to find all the elements with this class.
Additionally, Google Maps doesn’t use traditional pagination. Instead, it continuously loads more results as you scroll down the list. By understanding this layout and the relevant selectors, we can now proceed to write our scraping script that targets these specific elements to extract the information we need.
Step 1: Setting Up Your Environment
Firstly, we’ll prepare our Python environment with the necessary libraries for web scraping Google Maps. Open the project file in your respective code editor and import the libraries we have installed above.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
Here, we’re using:
seleniumwireinstead of regular Selenium to allow for easy proxy integration- The
webdriver_managerpackage will automatically download and manage the appropriate ChromeDriver version for us - The
By,ActionChains, andKeysimports from Selenium will help us interact with the page, such as scrolling and clicking elements - Finally, we import
timefor adding delays andcsvfor saving our scraped data.
Step 2: Configuring Selenium and ScraperAPI
Next, we’ll configure Selenium to work with ScraperAPI, a powerful web scraping service that helps us bypass Google’s strict anti-scraping mechanisms by rotating proxies, handling CAPTCHAs, generating matching headers and cookies, and more.
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
Note: Create a free ScraperAPI account and replace 'YOUR_SCRAPERAPI_KEY' with your API key.
Here, we’re setting up selenium-wire to use ScraperAPI as our proxy. To correctly use Selenium with ScraperAPI, you should use our proxy mode, as you would any other proxy. The username for the proxy is scraperapi and the password is your API key.
To enable extra functionality whilst using the API in proxy mode, you can pass parameters to the API by adding them to the username, separated by periods. The proxy URL includes parameters like render=true, which ensures JavaScript is executed, and country_code=us to geotarget our requests to the United States.
The headless mode allows our script to run without opening a visible browser window, improving performance and reducing resource usage. We’re also using ChromeDriverManager to automatically manage Chrome driver installations and updates.
Resource: Check out our proxy-port documentation to learn more.
Step 3: Accessing Google Maps
Now, we will direct our browser to navigate to the Google Maps page for our desired search term, which, in this example, is “pizza in New York.” This action loads the page as if a user had manually typed the query in the Google search bar.
url = "https://www.google.com/maps/search/pizza+in+new+york"
driver.get(url)
Step 4: Bypassing The Cookies Pop-Up
Google Maps might display a cookies consent pop-up when Selenium tries to open the link.
To bypass this, we need to programmatically accept this pop-up.
try:
button = driver.find_element(By.XPATH, '//*[@id="yDmH0d"]/c-wiz/div/div/div/div[2]/div[1]/div[3]/div[1]/div[1]/form[2]/div/div/button/div[3]')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
We will attempt to locate and click the “Accept all” button on the cookie consent pop-up. We use a try-except block since the pop-up might not always appear. Inside the try block, driver.find_element(By.XPATH, '...') searches for the button element using its XPath. If found, button.click() simulates a click on the button. If the element isn’t found (meaning the pop-up is not present), the except block executes, printing a message to the console.
Note: Using ScraperAPI should prevent CAPTCHAs challenges to appear but it’s a good practice to have this in place, just in case.
Step 5: Scrolling and Loading More Results
Google Maps dynamically loads more results as you scroll down the page. We’ll simulate this scrolling behavior to load more data.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
panel_element = driver.find_element(By.XPATH, panel_xpath)
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
Here, panel_xpath identifies the panel containing the search results. The scroll_panel_down() function is defined to send a series of Page Down key presses to this panel, forcing it to load additional results. The parameters presses=5 and pause_time=1 specify the number of times to press the key and the time to wait between each press, respectively. This method ensures we can access all available data by simulating a user’s scroll action.
Step 6: Parsing Data with BeautifulSoup
With the results loaded, the next step is to parse the HTML and extract relevant information such as business names, ratings, reviews, and service options using BeautifulSoup.
page_source = driver.page_source
soup = BeautifulSoup(page_source, "lxml")
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
We first get the entire page source using driver.page_source. This gives us the HTML content of the page after all our interactions (scrolling, etc.) have been performed. We then create a BeautifulSoup object, passing in the page source, and specify “lxml” to parse the content.
Next, we use BeautifulSoup’s find_all method to locate all elements with specific class names corresponding to the data we want to extract.
Step 7: Saving Data to a CSV File
Finally, we store the extracted data into a CSV file using Python’s file-handling capabilities.
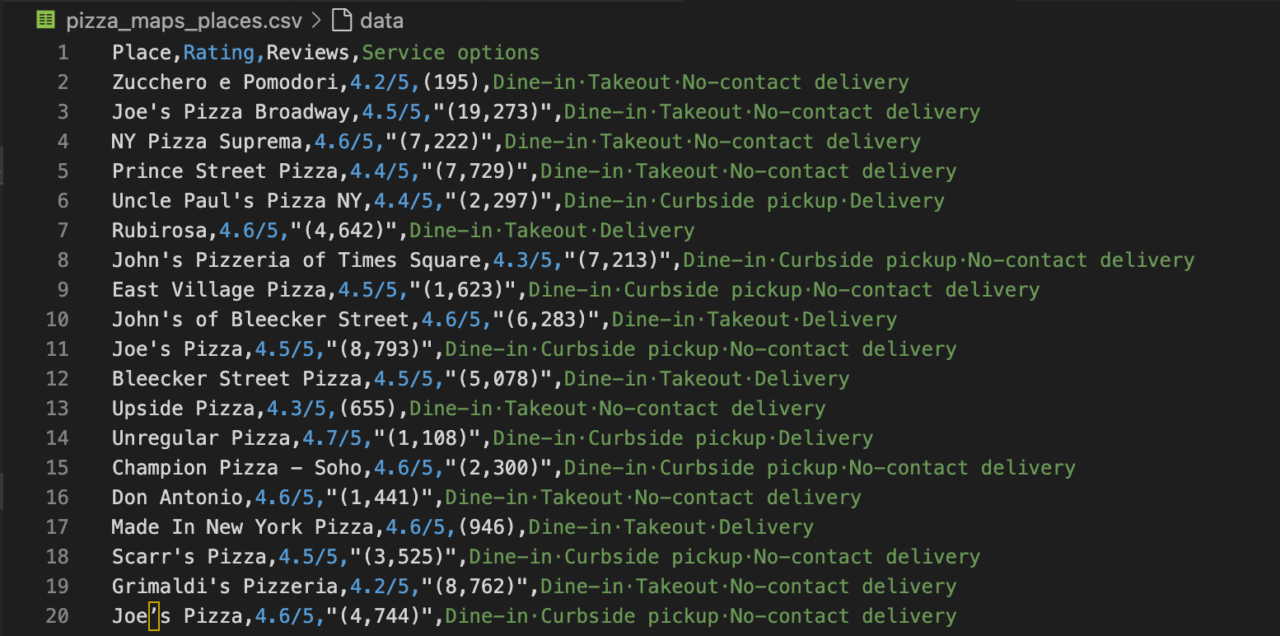
csv_file_path = 'pizza_maps_places.csv'
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(['Place', 'Rating', 'Reviews', 'Service options'])
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings[i].text + "/5") if i < len(ratings) else 'N/A'
review_count = reviews[i].text if i < len(reviews) else 'N/A'
service = services[i].text if i < len(services) else 'N/A'
if title:
csv_writer.writerow([title, rating, review_count, service])
print(f"Data has been saved to '{csv_file_path}'")
driver.quit()
At this stage, it is usually about saving the data and performing data cleaning. For example, this may involve removing unnecessary characters, correcting data errors, or eliminating empty strings.
- We open a file named ‘
pizza_maps_places.csv‘ in write mode, ensuring we useutf-8encoding to handle any special characters. - Then, we iterate through our scraped data. For each restaurant, we extract the title from the ‘
aria-label‘ attribute of the title element. - We get the rating text and append “
/5” to it or use ‘N/A‘ if no rating is found. - Similarly, we extract the review count and service options, using ‘
N/A‘ as a fallback if the data is missing. - We then proceed to write each restaurant’s data as a row in our CSV file.
- After the loop, we print a confirmation message with the file path.
- Finally, we call
driver.quit()to close the browser and end the Selenium session, freeing up system resources.
Full Google Maps Scraper with Selenium
Here’s our full script for scraping Google Maps to find Pizza places in New York.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
# Selenium Wire configuration to use a proxy
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
# URL of the web page
url = "https://www.google.com/maps/search/pizza+in+new+york"
# Open the web page
driver.get(url)
try:
button = driver.find_element(By.XPATH,'//*[@id="yDmH0d"]/c-wiz/div/div/div/div[2]/div[1]/div[3]/div[1]/div[1]/form[2]/div/div/button/div[3]')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
# Set an implicit wait time to wait for JavaScript to render
driver.implicitly_wait(30) # Wait for max 30 seconds
# Scrolls within a specific panel by simulating Page Down key presses.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
# Find the panel element
panel_element = driver.find_element(By.XPATH, panel_xpath)
# Ensure the panel is in focus by clicking on it
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
# Send the Page Down key to the panel element
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
# Get the page HTML source
page_source = driver.page_source
# Parse the HTML using BeautifulSoup
soup = BeautifulSoup(page_source, "lxml")
# Find all elements using its class
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
# Print the number of places found
elements_count = len(titles)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'maps_pizza_places.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(['Place', 'Rating', 'Reviews', 'Service options'])
# Write the extracted data
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings[i].text + "/5") if i < len(ratings) else 'N/A' # Ensure we have a rating and reviews for each title, default to 'N/A' if not found
review_count = reviews[i].text if i < len(reviews) else 'N/A'
service = services[i].text if i < len(services) else 'N/A'
# Write a row to the CSV file
if title:
csv_writer.writerow([title, rating, review_count, service])
print(f"Data has been saved to '{csv_file_path}'")
# Release the resources and close the browser
driver.quit()
After running this script, the terminal will show you if it had to accept any cookies, how many places were extracted, and where the CSV file with all the scraped information was saved.
Want to do this with Javascript? Check out our comprehensive guide on How to build a Google Maps Scraper [In Javascript]
Scraping Google Maps with ScraperAPI’s Render Instructions [API Approach]
In the previous sections, we used Selenium to scrape data from Google Maps. While this method is effective, it involves handling browser automation directly, which can be complex and resource-intensive.
ScraperAPI offers an easier approach by using its Render Instruction Set. This allows us to perform similar automation tasks, such as scrolling through an infinitely loading page or clicking buttons with less code and effort.
How to Use ScraperAPI’s Render Instructions
The Render Instruction Set allows you to send instructions to a headless browser via ScraperAPI, guiding it on what actions to perform during page rendering. These instructions are sent as a JSON object in the API request headers.
Here’s how we can use ScraperAPI to scrape Google Maps for pizza places in New York, replicating what we achieved with Selenium but in a more efficient manner
import requests
from bs4 import BeautifulSoup
import csv
api_key = 'YOUR_SCRAPERAPI_KEY'
url = 'https://api.scraperapi.com/'
# Define the target Google Maps URL
target_url = 'https://www.google.com/maps/search/pizza+in+new+york'
# div.VfPpkd-RLmnJb
# Construct the instruction set for Scraper API
headers = {
'x-sapi-api_key': api_key,
'x-sapi-render': 'true',
'x-sapi-instruction_set': '[{"type": "loop", "for": 5, "instructions": [{"type": "scroll", "direction": "y", "value": "bottom" }, {"type": "click", "selector": {"type": "css", "value": "div.VfPpkd-RLmnJb"}}, { "type": "wait", "value": 5 }] }]'
}
payload = {'url': target_url, 'country_code': 'us'}
response = requests.get(url, params=payload, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
# Find all listing elements using the class "Nv2PK"
listings = soup.find_all("div", class_="Nv2PK")
# Print the number of places found
elements_count = len(listings)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'render_map_results.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(['Place', 'Rating', 'Reviews', 'Service options'])
# Iterate through each listing and extract information
for listing in listings:
title_tag = listing.find("a", class_="hfpxzc")
rating_tag = listing.find("span", class_="MW4etd")
review_tag = listing.find("span", class_="UY7F9")
service_tags = listing.find_all("div", class_="Ahnjwc")
title = title_tag.get('aria-label') if title_tag else 'N/A'
rating = rating_tag.text if rating_tag else 'N/A'
reviews = review_tag.text if review_tag else 'N/A'
service_options = ', '.join([service.text for service in service_tags]) if service_tags else 'N/A'
# Write a row to the CSV file
csv_writer.writerow([title, rating, reviews, service_options])
print(f"Data has been saved to '{csv_file_path}'")
Note: To learn more about using the Render Instruction Set and see additional examples, check out the ScraperAPI documentation.
The key part of this setup is the headers dictionary, which includes:
- The
x-sapi-api_keyto authenticate with ScraperAPI x-sapi-renderset to true to enable JavaScript rendering, andx-sapi-instruction_setwhich contains the instructions for the browser.
In our instruction set, we click on any elements matching the selector div.VfPpkd-RLmnJb if it exists. We do this to bypass the cookies popup, then we proceed to use a loop to scroll the page five times, and wait for five seconds between each action. This approach effectively loads more results dynamically, similar to scrolling behavior.
Wrapping Up: What Can You Do with Google Maps Data?
This article has guided you through scraping data from Google Maps, showcasing how to collect valuable information such as business names, ratings, reviews, and service options. Here are some potential applications for your newly acquired data:
- Market Research
- Competitor Analysis
- Customer Sentiment Analysis
- Location-Based Service Optimization
- Trend Identification
Are you tired of getting continuously blocked by Google? Try ScraperAPI for free and experience effortless and scalable scraping in minutes!
To learn more, check out the following resources:




