



TL;DR: Full GitHub Repos Scraper
Here’s the completed GitHub Repository scraper for those in a hurry:
import requests
from bs4 import BeautifulSoup
import json
url = 'https://github.com/psf/requests'
payload = {
'api_key': 'YOUR_API_KEY',
'url': url,
'render': 'true',
}
page = requests.get('https://api.scraperapi.com', params=payload)
soup = BeautifulSoup(page.text, 'html.parser')
repo = {}
name_html_element = soup.find('strong', {"itemprop": "name"})
repo['name'] = name_html_element.get_text().strip()
relative_time_html_element = soup.find('relative-time')
repo['latest_commit'] = relative_time_html_element['datetime']
branch_element = soup.find('span', {"class": "Text-sc-17v1xeu-0 bOMzPg"})
repo['branch'] = branch_element.get_text().strip()
commit_element = soup.find('span', {"class": "Text-sc-17v1xeu-0 gPDEWA fgColor-default"})
repo['commit'] = commit_element.get_text().strip()
stars_element = soup.find('span', {"id": "repo-stars-counter-star"})
repo['stars'] = stars_element.get_text().strip()
forks_element = soup.find('span', {"id": "repo-network-counter"})
repo['forks'] = forks_element.get_text().strip()
description_html_element = soup.find('p', {"class":"f4 my-3"})
repo['description'] = description_html_element.get_text().strip()
main_branch = repo['branch']
readme_url = f'https://raw.githubusercontent.com/psf/requests/{main_branch}/README.md'
readme_page = requests.get(readme_url)
if readme_page.status_code != 404:
repo['readme'] = readme_page.text
print(repo)
with open('repo.json', 'w') as file:
json.dump(repo, file, indent=4)
print('Data saved to repo.json')
Before running the code, add your API key to the
api_key parameter within the payload.
Note: Don’t have an API key? Create a free ScraperAPI account to get 5,000 API credits to try all our tools for seven days.
Want to see how we built it? Keep reading!
Scraping GitHub Repos with Python
Step 1: Set Up Your Project
Start by setting up your project environment. Create a new directory for your project and a new file for your script.
Run these in your terminal:
mkdir github-scraper
cd github-scraper
touch app.py
Step 2: Install the Required Libraries
To scrape data from GitHub, you’ll need two essential libraries: requests and BeautifulSoup. These libraries will handle fetching the webpage and parsing its content.
requests allows you to send HTTP requests easily in Python, and
BeautifulSoup is used to parse HTML and XML documents.
Install both libraries using pip:
pip install requests beautifulsoup4
Step 3: Download the Target Page with ScraperAPI
Select a GitHub repository from which you want to retrieve data. For this example, we’ll use the requests repository.
First, we import the necessary libraries: requests,
BeautifulSoup, and JSON; then, we set the URL of the
GitHub repository we want to scrape by storing it in the
url variable.
import requests
from bs4 import BeautifulSoup
import json
url = 'https://github.com/psf/requests'
Next, we prepare the payload dictionary, which holds your ScraperAPI API key, the URL, and the render parameter.
The render parameter ensures that the content rendered by JavaScript is included in the response.
Note: Don’t have an API key? Create a free ScraperAPI account to get 5,000 API credits to try all our tools for 7 days.
payload = {
'api_key': 'YOUR_API_KEY',
'url': url,
'render': 'true',
}
We use requests.get() to send a GET request to ScraperAPI,
passing the payload as a parameter. ScraperAPI processes the request, handles
IP rotation to bypass anti-scraping measures, and returns the HTML content.
page = requests.get('https://api.scraperapi.com', params=payload)
Important
We’re sending our requests through ScraperAPI to avoid getting blocked by GitHub’s anti-bot detection systems.
ScraperAPI uses machine learning and years of statistical analysis to choose the right combination of IP and headers, smartly rotating these two when needed to ensure a successful request.
Step 4: Parse the HTML Document
After downloading the target page, the next step is to parse the HTML document to extract the needed data.
We’ll pass the HTML content to BeautifulSoup to create a parse tree. This allows you to navigate and search the HTML structure easily:
soup = BeautifulSoup(page.text, 'html.parser')
Step 5: Understanding Github Repository Page Layout
Before extracting the data, we need to identify the HTML elements on the webpage that contain the data we need.
To do that, open the repository page in your browser and use DevTools to inspect the HTML structure. This will help us understand how to select elements and extract data effectively. By exploring the page layout and identifying the tags and attributes, we’ll be better equipped to scrape the data we need.
The first element we’ll be locating is the repository’s name. When you inspect
the page, you’ll see the repository name is stored within a
<strong> tag with the attribute
itemprop="name".
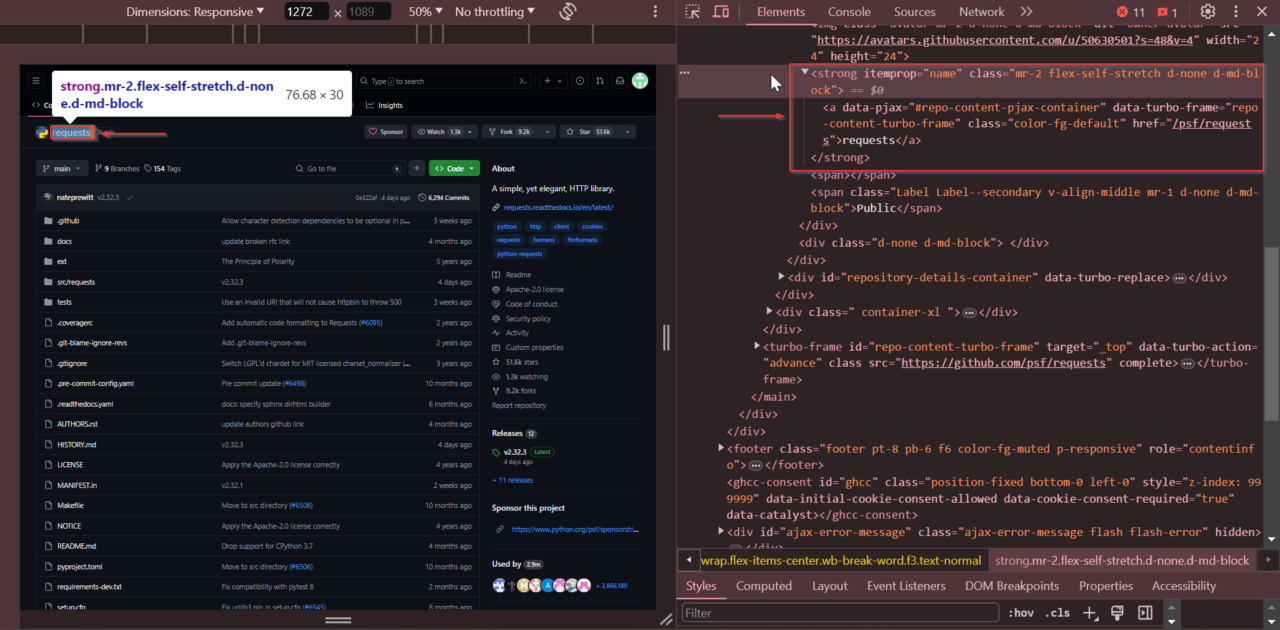
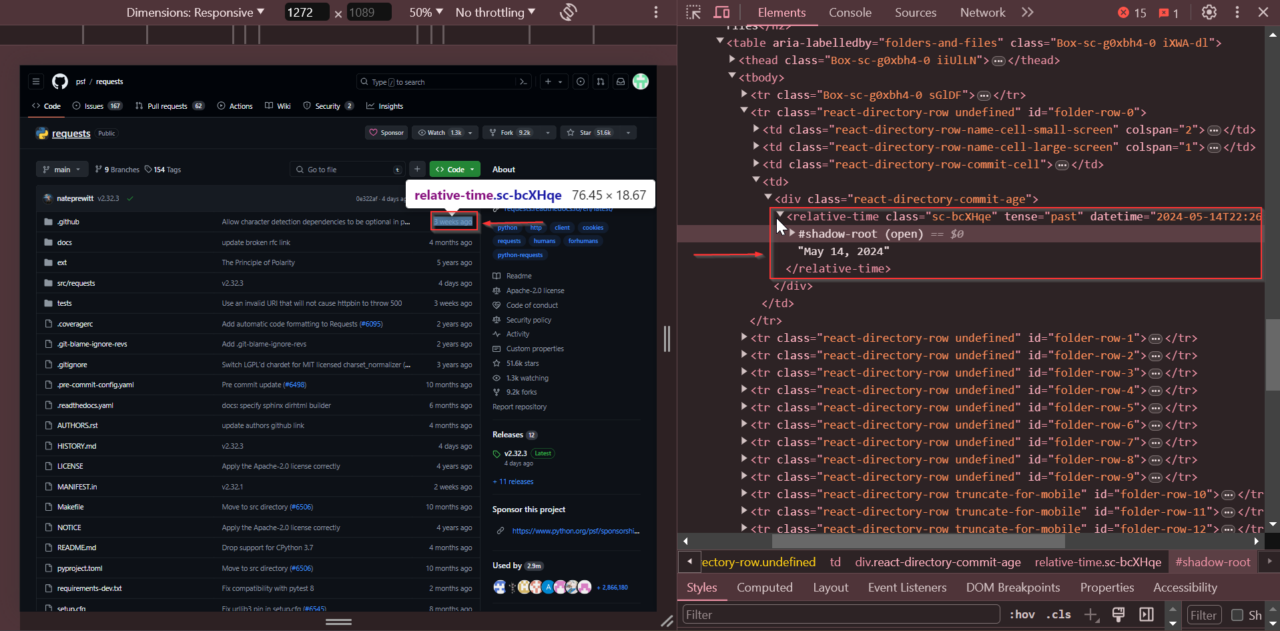
Next, we’ll find the repository’s latest commit time. Scroll to the commit history section, right-click on the latest commit date, and select “Inspect.”
The latest commit time is found within the first
<relative-time> tag.
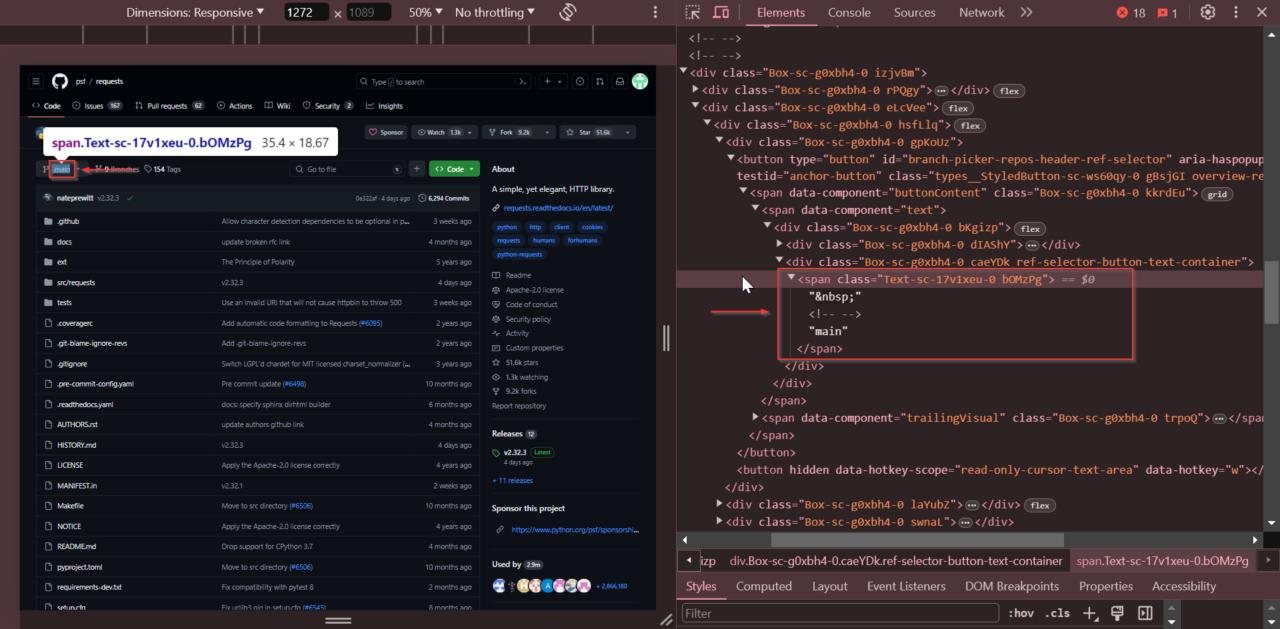
After that, we’ll locate the current branch name. Look at the branch selector dropdown, right-click on the branch name, and select “Inspect.”
The branch name is stored within a <span> tag with the
class Text-sc-17v1xeu-0 bOMzPg.
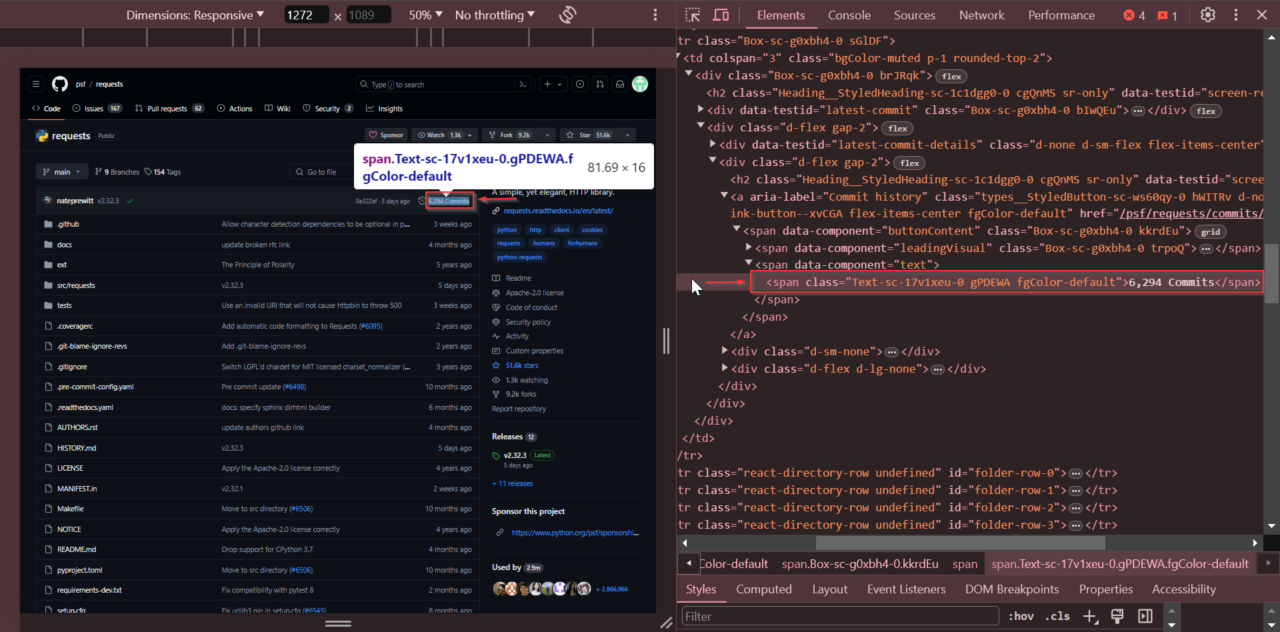
Next, we’ll locate the total number of commits. Find the section showing the total number of commits. Right-click on the commit count and select “Inspect”.
The number of commits is stored within a <span> tag with
the class Text-sc-17v1xeu-0 gPDEWA fgColor-default.
Next, we’ll locate the star count. Locate the star count near the top of the repository page. Right-click on the star count and select “Inspect”.
The star count is within a <span> tag with the id
repo-stars-counter-star.
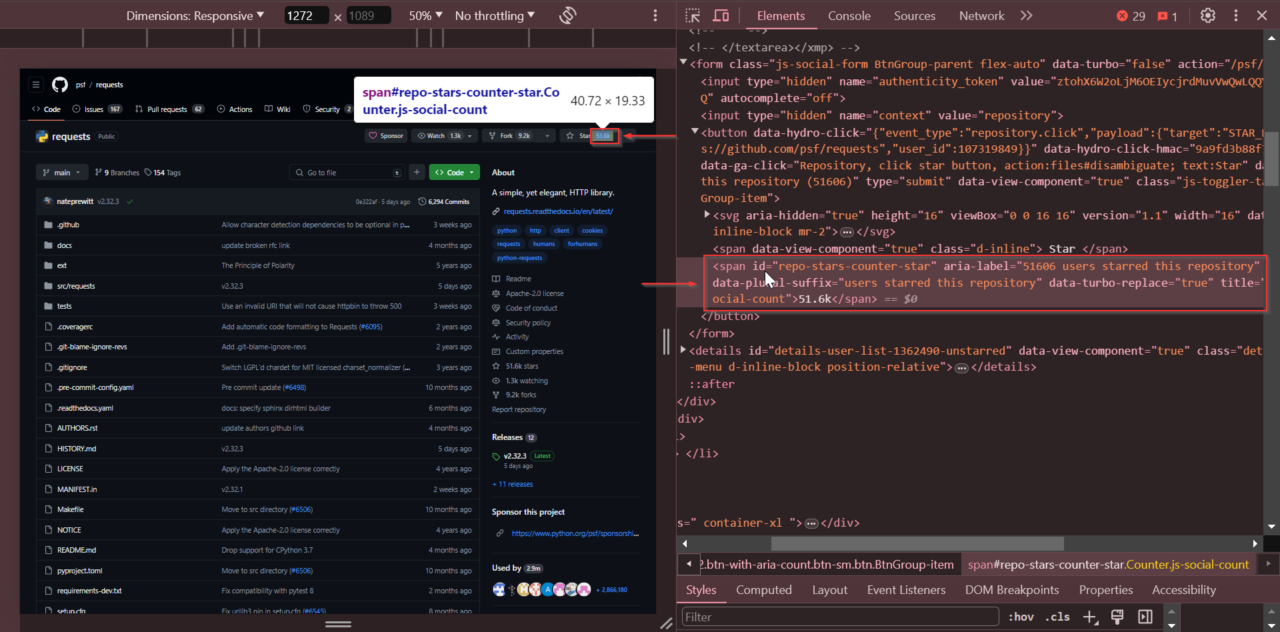
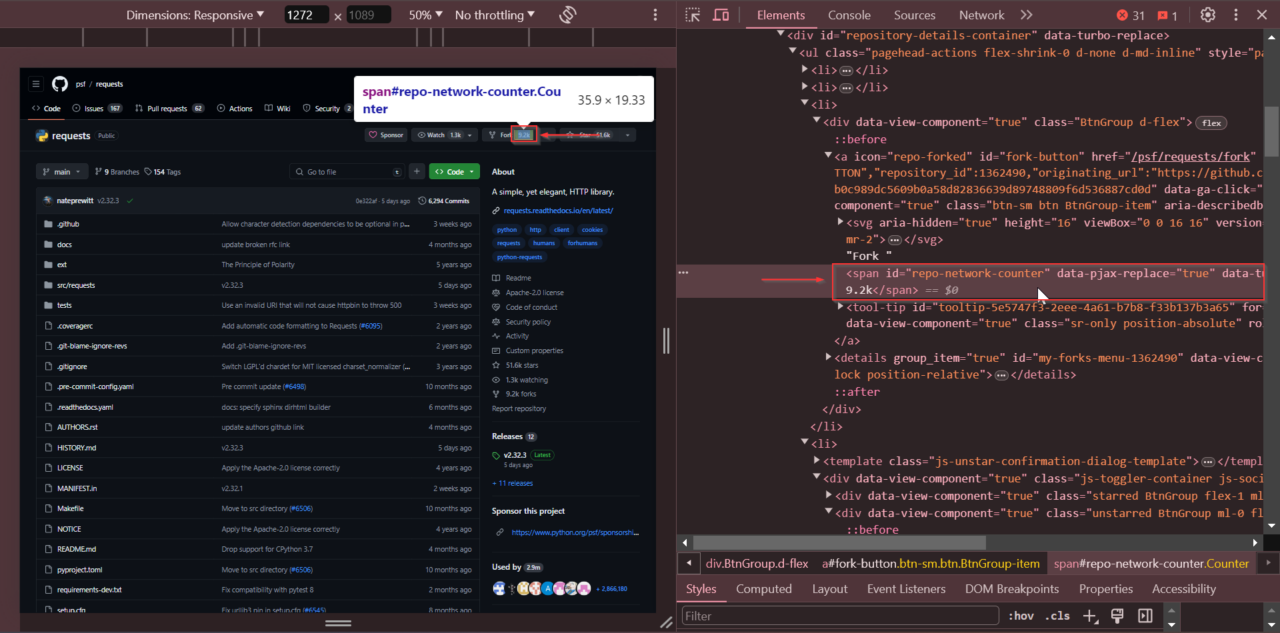
Also, right-click on the forks count and select “Inspect” to get the number of
forks. The forks count is stored within a <span> tag with
the id repo-network-counter.
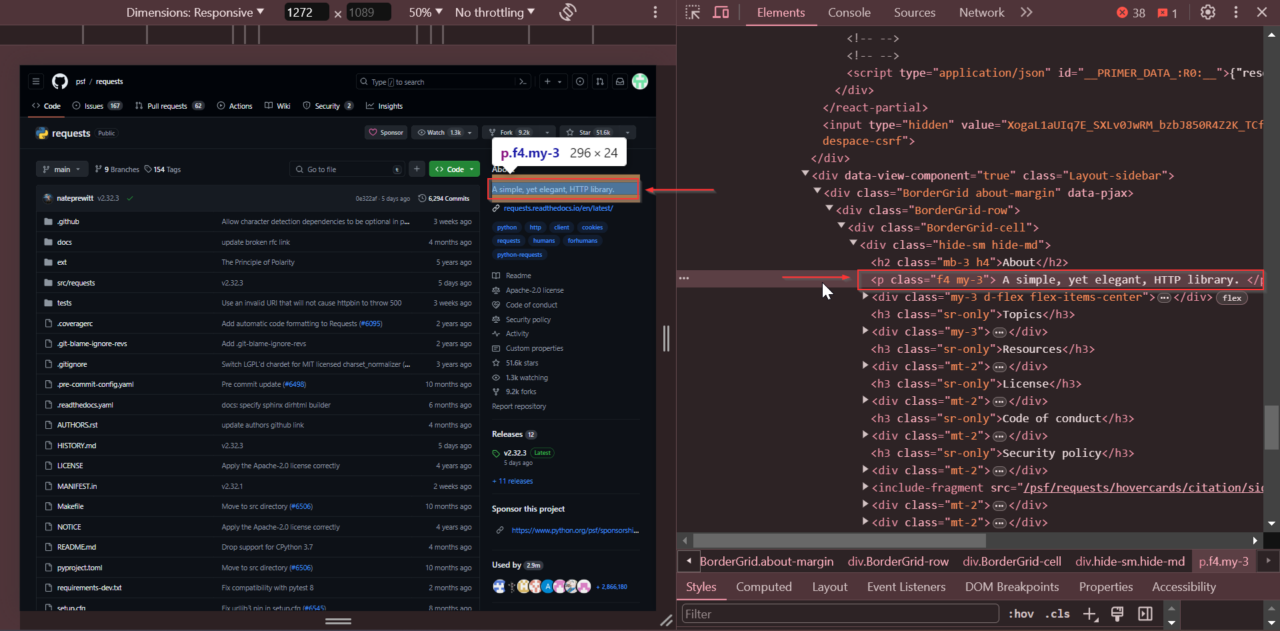
Next, we’ll locate the repository description. Look for it near the top of the page in the “About” section. Right-click on it and select “Inspect.”
The description is stored within a <p> tag with the class
f4 my-3.
Using DevTools to inspect these elements, we can identify the exact tags and attributes needed to extract the desired data.
Now that we know where to find everything, we can code the extraction process.
Step 6: Extract GitHub Repository Data
Now that we’ve familiarized ourselves with the HTML structure of the GitHub repository page, let’s extract the relevant data.
We’ll initialize a dictionary to store the scraped data and then extract each piece of information step by step.
First, we create an empty dictionary called repo to hold the
extracted data.
repo = {}
To extract the repository name, we locate the <strong> tag
with the attribute itemprop="name". We
use soup.find()
to find the tag, then get its text content with get_text() and
store it in the repo dictionary under the key name.
name_html_element = soup.find('strong', {"itemprop": "name"})
repo['name'] = name_html_element.get_text().strip()
Next, we extract the latest commit time by looking for the
<relative-time> tag. We use soup.find() to
locate this tag, extract its datetime attribute to get the exact
timestamp, and store it in the repo dictionary under the
latest_commit key.
The find() method will locate the first
<relative-time> tag it encounters, which will always be the
most recent commit based on the page’s structure we inspected earlier.
relative_time_html_element = soup.find('relative-time')
repo['latest_commit'] = relative_time_html_element['datetime']
Next, we find the <span> tag with the id
repo-stars-counter-star to extract the star count. Similarly, we
find the <span> tag with the id
repo-network-counter for the fork count.
Then, we use soup.find() to locate each tag, then get their text
content with get_text() and store it in the
repo dictionary under the keys stars and
forks, respectively.
stars_element = soup.find('span', {"id": "repo-stars-counter-star"})
repo['stars'] = stars_element.get_text().strip()
forks_element = soup.find('span', {"id": "repo-network-counter"})
repo['forks'] = forks_element.get_text().strip()
Finally, we extract the repository description by locating the
<p> tag with the class f4 my-3. We use
soup.find() to find the tag, then get its text content with
get_text() and store it in the repo dictionary.
description_html_element = soup.find('p', {"class": "f4 my-3"})
repo['description'] = description_html_element.get_text().strip()




