



Being one of the biggest real estate platforms, you can use Homes.com data to stay ahead of market trends and gain a deeper insight into the housing market, enabling you to devise well-informed strategies in this dynamic industry.
Ready? Let’s get started!
TL;DR: Full Homes.com Scraper
Here’s the completed code for those in a hurry:
import requests
import csv
from bs4 import BeautifulSoup
from time import sleep
# CONSTANTS
API_KEY = 'YOUR_API_KEY' # Replace with your actual API key
BASE_URL = 'https://homes.com/los-angeles-ca/homes-for-rent/'
properties = [] # List to store the properties' information
# Loop through the first 10 pages of the website
for page in range(1, 11):
# Construct the URL for the current page
url = f'{BASE_URL}p{page}/'
print(f"Scraping page {page} of {url}")
# Set up the payload for the request with API key, country code and URL
payload = {
'api_key': API_KEY,
'country_code': 'us',
'url': url
}
# Perform the GET request using the payload
try:
response = requests.get('https://api.scraperapi.com', params=payload)
# Check if the request was successful
if response.status_code == 200:
# Parse the HTML content with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all property listings on the current page
properties_list = soup.find_all('div', attrs={'class': 'for-rent-content-container'})
# Add the found properties to the main PROPERTIES list
properties += properties_list
else:
# Print an error message if the page load was not successful
print(f"Error on page {page}: Received status code {response.status_code}")
except requests.RequestException as e:
# Print an error message if the request failed
print(f"Request failed on page {page}: {e}")
# Sleep for 1 second to respect rate limiting
sleep(1)
# Write the collected data to a CSV file
with open('properties.csv', 'w', newline='') as f:
writer = csv.writer(f)
# Write the header row
writer.writerow(['title', 'address', 'price', 'beds', 'baths', 'description', 'url'])
# Iterate through each property and extract information
for property in properties:
# Use BeautifulSoup to extract each piece of information
title_elem = property.find('p', attrs={'class': 'property-name'})
address_elem = property.find('p', attrs={'class': 'address'})
info_container = property.find('ul', class_='detailed-info-container')
extra_info = info_container.find_all('li') if info_container else []
description_elem = property.find('p', attrs={'class': 'property-description'})
url_elem = property.find('a')
# Extract the text or attribute, or set it to None if the element was not found
title = title_elem.text.strip() if title_elem else 'N/A'
address = address_elem.text.strip() if address_elem else 'N/A'
price = extra_info[0].text.strip() if len(extra_info) > 0 else 'N/A'
beds = extra_info[1].text.strip() if len(extra_info) > 1 else 'N/A'
baths = extra_info[2].text.strip() if len(extra_info) > 2 else 'N/A'
description = description_elem.text.strip() if description_elem else 'N/A'
url = BASE_URL + url_elem.get('href') if url_elem else 'N/A'
# Write the property information to the CSV file
writer.writerow([title, address, price, beds, baths, description, url])
# Print completion message
print(f"Scraping completed. Collected data for {len(properties)} properties.")
Before running the code, add your API key to the
api_key parameter within the payload.
Note: Don’t have an API key? Create a free ScraperAPI account to get 5,000 API credits to try all our tools for 7 days.
Want to see how we built it? Keep reading and join us on this exciting scraping journey!
Scraping Homes.com Properties
In this article, we’ll focus on gathering the latest rental property listings from Homes.com in Los Angeles, CA.
We’ll use a Python script to go through these listings and pull out the information we need. This way, we can collect a lot of data quickly and easily, getting a clear picture of the current real estate market on Homes.com.
Requirements
Before writing our script, we must set up our tools and software. Here’s what you need to do:
- Install Python: Make sure you have Python installed on your computer. It’s best to have version 3.10 or newer.
- Install the Necessary Libraries: Open your terminal or command prompt and type this command to install the libraries we need:
pip install requests beautifulsoup4
- Set Up Your Project: Next, we need to create a folder for our scraping project and a Python file where we’ll write the code. In your terminal, type:
mkdir homes_scraper
cd homes_scraper
touch app.py
This will create a new folder called homes_scraper and a Python file named app.py for our code.
Everything is set up and we are now ready to explore the page and plan the logic to extract all the juicy property listings!
Understanding Homes.com’s Website Layout
To scrape effectively, it’s essential first to get familiar with the layout of Homes.com.
In our project, we’re looking at Los Angeles rentals. The image below is a visual guide for us, showing where these listings appear on the website. By understanding this layout, we can tailor our script well, ensuring it navigates us to the right places and captures the essential data seamlessly.
You’d see this if you search for homes for rent in ‘Los Angeles, CA’ on homes.com; the highlighted URL is what we’ll use in our scraper.
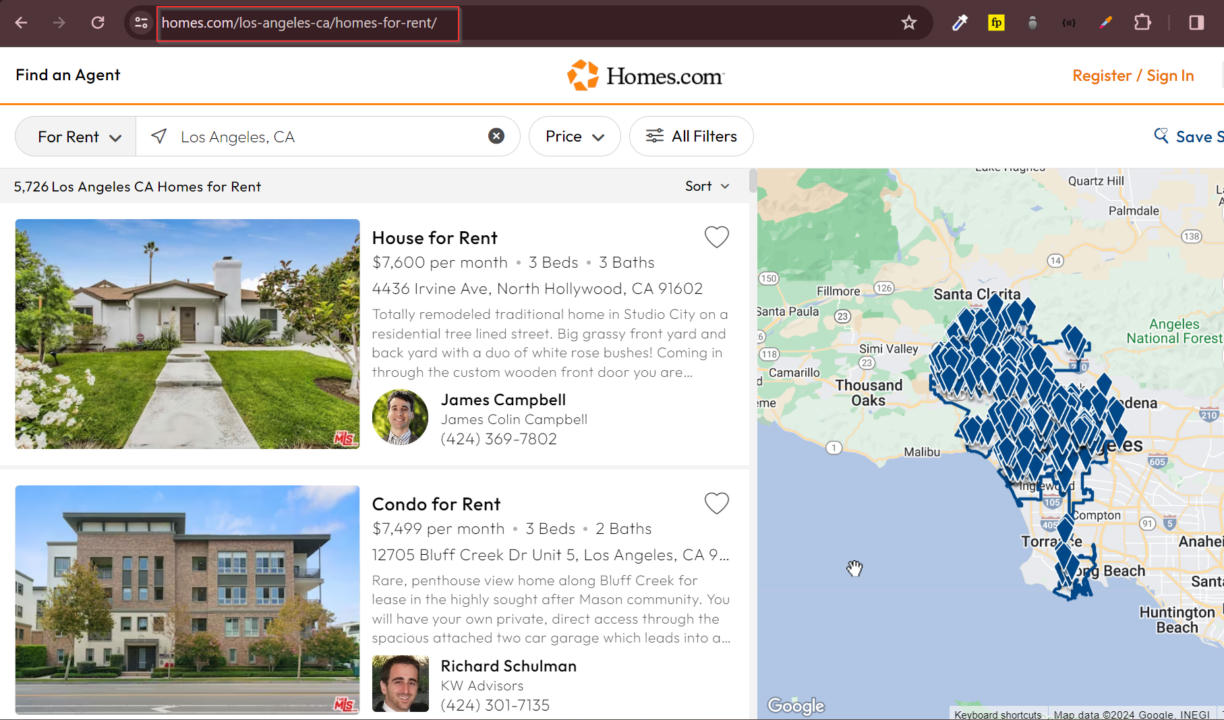
Our goal is to extract specific details from each listing, like:
- The property title
- Its location
- The rental price
- The number of bedrooms and bathrooms
- A description
- The direct link to the complete listing
To do this, we’ll use the developer tools (right-click on the webpage and select ‘inspect’) to examine the HTML structure.
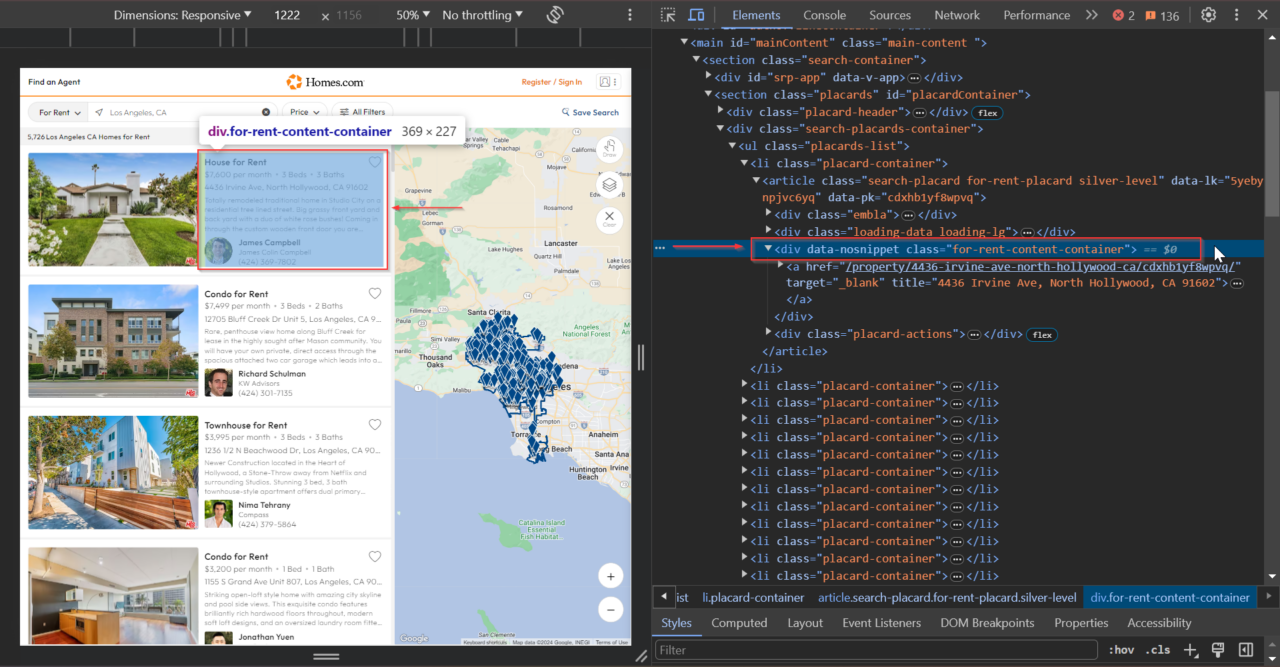
This div tag holds all the information of each individual
property listing: .for-rent-content-container.
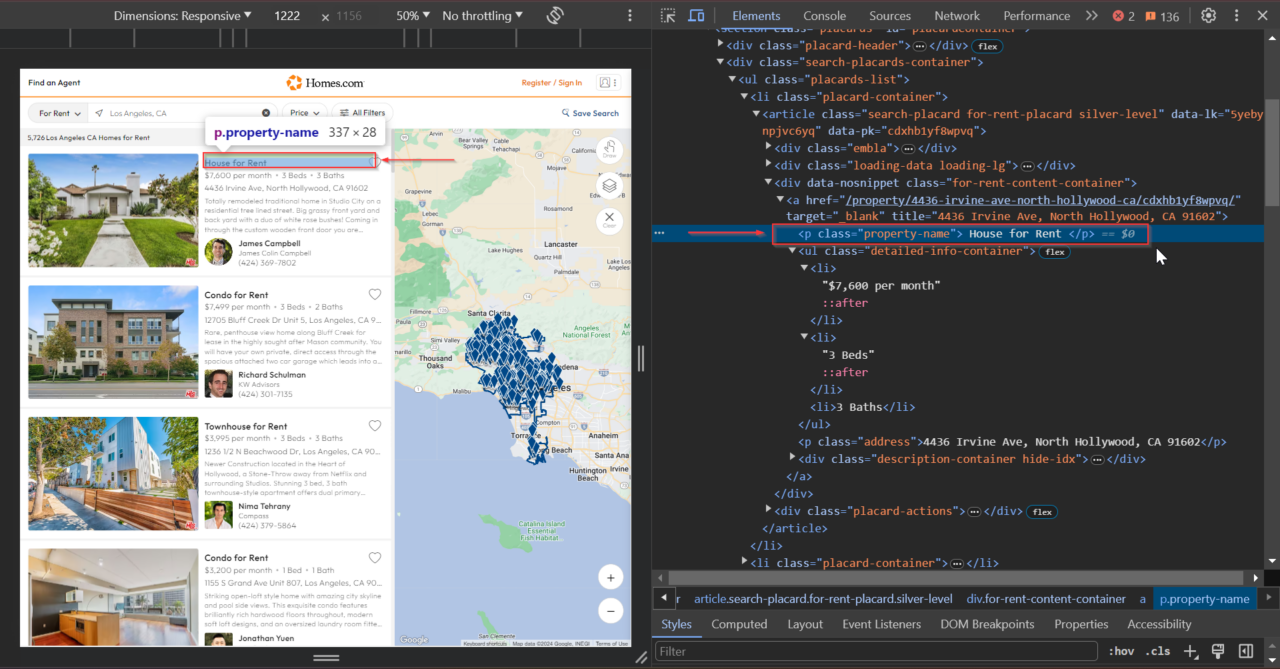
This <p> tag contains the property title: .property-name.
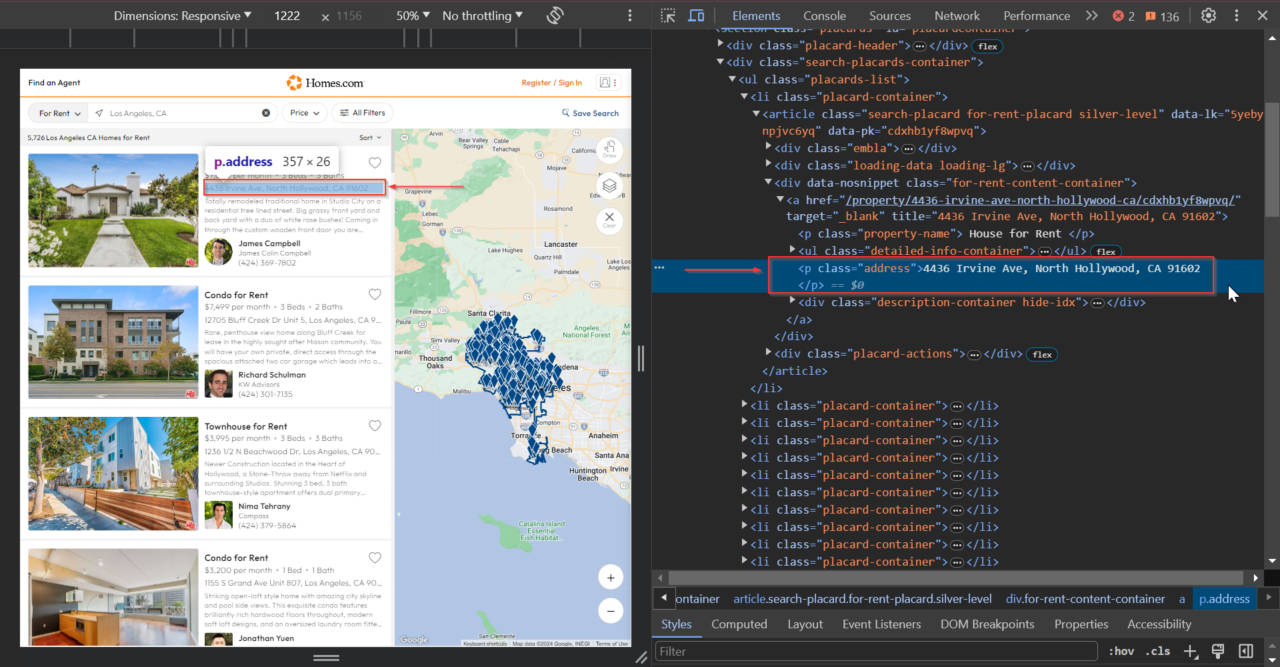
This <p> tag contains the property title: address.
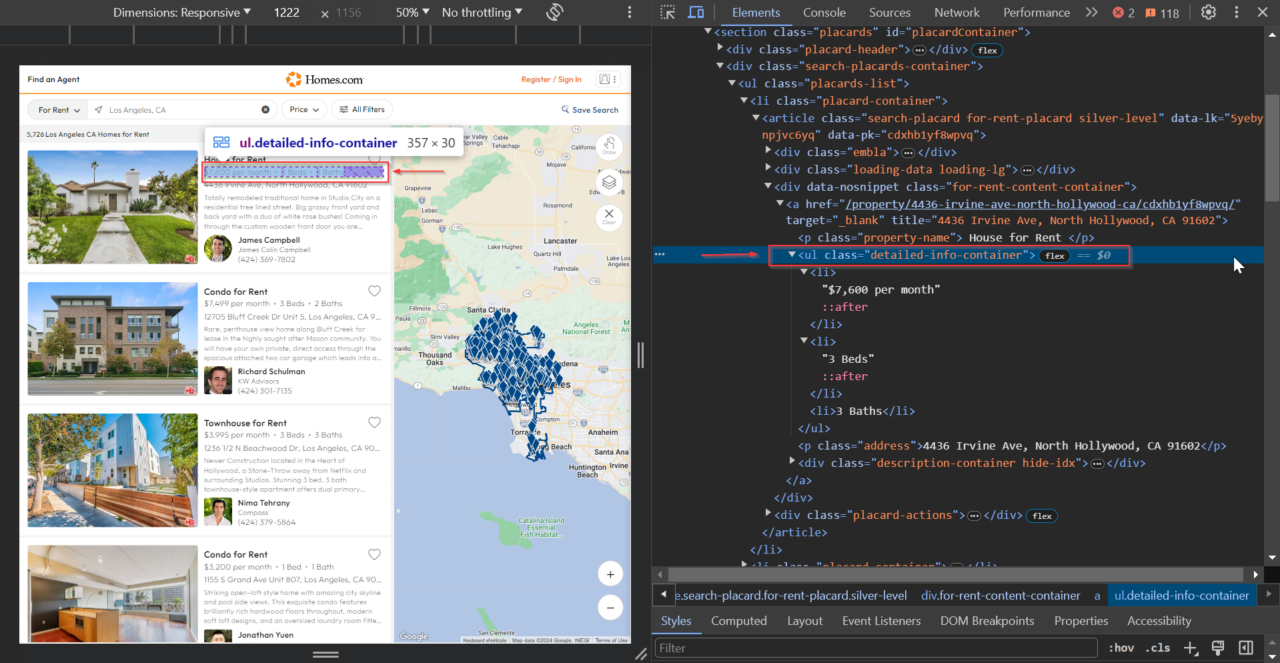
The <li> tags within this <ul> tag contain the price, number of
beds, and baths: detailed-info-container.
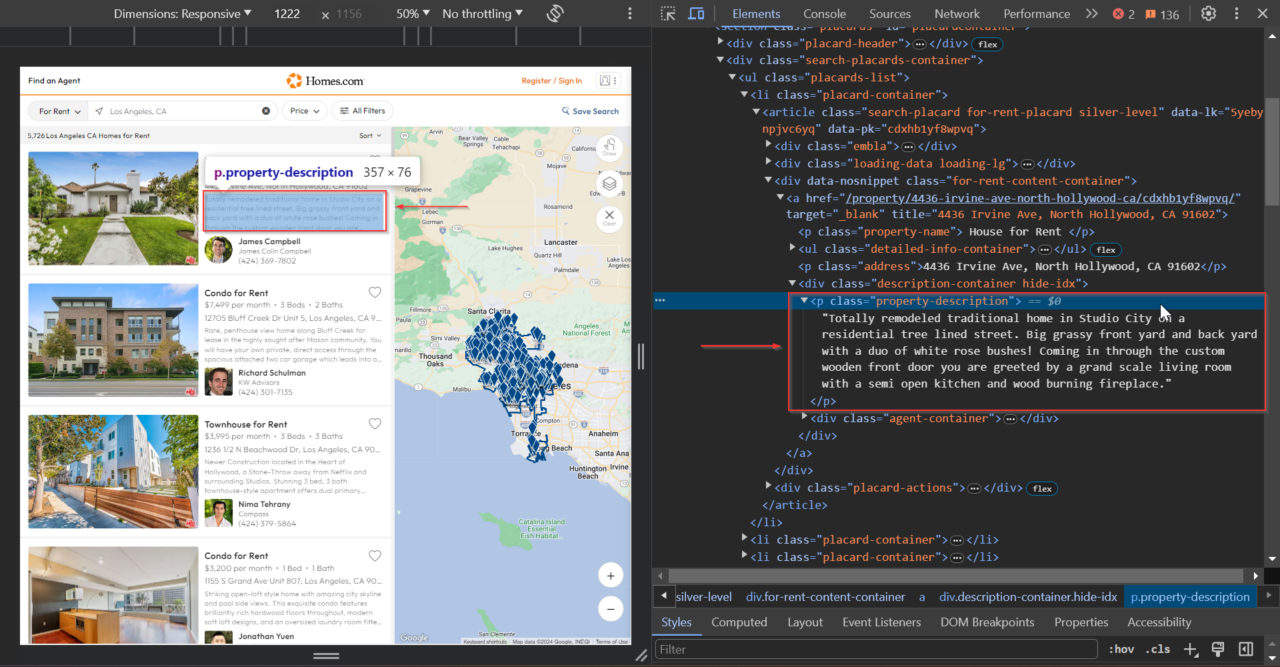
The brief description inside the <p> tag
(.property-description) is vital. It gives us the main points and
ideas of what the property is all about, helping us get the big picture
quickly.
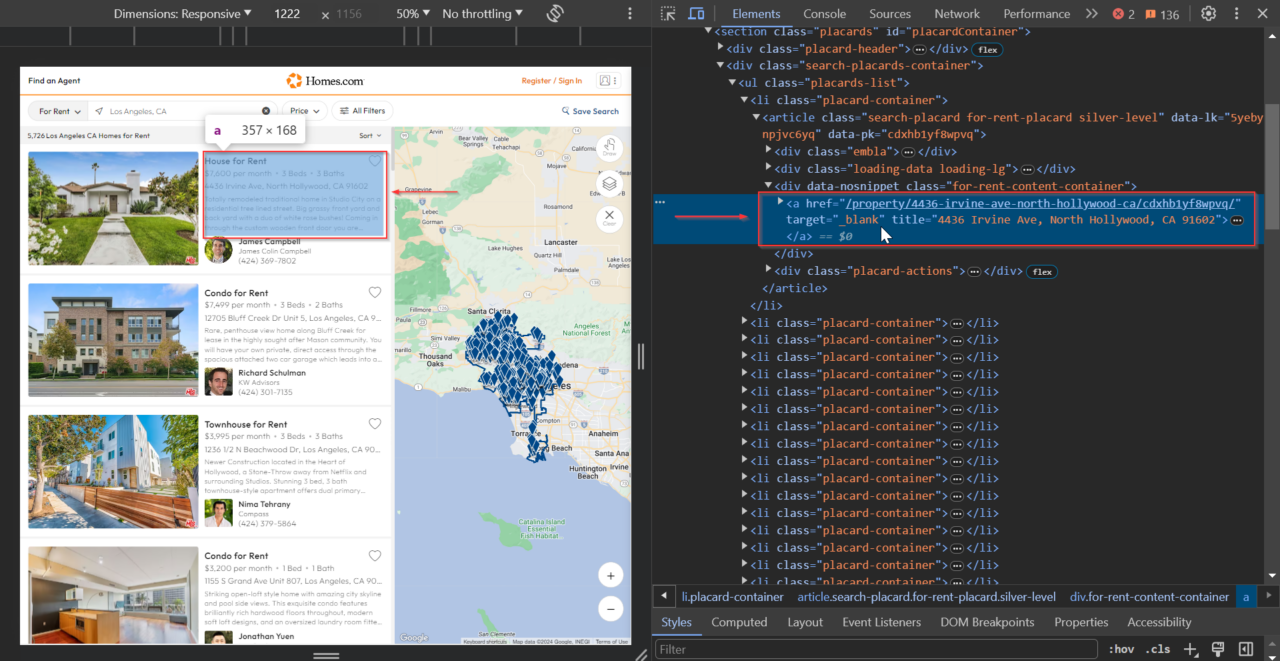
An <a> tag, within the <div> tag with the class
.for-rent-content-container, leads to the complete listing.
Now that we know what we’re looking for, let’s start scraping!
Step 1: Importing Our Libraries
We begin by importing the necessary libraries:
requestsfor making HTTP requests to ScraperAPIcsvfor handling CSV file operations-
BeautifulSoupfrombs4for parsing HTML content -
sleepfromtimeto pace our requests to avoid overloading the server.
import requests
import csv
from bs4 import BeautifulSoup
from time import sleep
Step 2: Setting Up Our Constants
Next, set your API key and the base URL for the Homes.com Los Angeles rentals
section, then define a list named properties where we’ll store
information about each property.
API_KEY = 'YOUR_API_KEY' # Replace with your actual API key
BASE_URL = 'https://homes.com/los-angeles-ca/homes-for-rent/'
properties = []
Step 3: Scraping Multiple Homes.com Pages
To get the most recent listings, we need to loop through the first ten pages of Homes.com.
We’ll construct the URL for each page and make a get() request to
ScraperAPI using our API key. Then, we’ll print out which page we’re scraping
for reference.
for page in range(1, 11):
url = f'{BASE_URL}p{page}/'
print(f"Scraping page {page} of {url}")
Note: Remember that you get 5,000 free API credits to test ScraperAPI, so keep that in mind when setting your scraper up, as every request will consume credits.
Step 4: Sending Requests Via ScraperAPI
The main challenge we’ll face while scraping Homes.com is avoid getting blocked by its anti-scraping mechanisms.
To ensure smooth and efficient scraping, ScraperAPI will:
- Rotate our IP and headers when needed
- Handle CAPTCHAs
- Mimic real traffic using statistical analysis and ML
And more.
That said, another feature we’ll be using is its geotargeting capability,
which we can utilize by specifying the ‘country_code’ parameter
in our payload. This ensures our data is region-specific and accurate.
Here’s how to set it up:
-
Construct your
payloadby including the API key, the constructed URL for the current page, and the country code. This tells ScraperAPI exactly what to fetch and from where.
payload = {
'api_key': API_KEY,
'country_code': 'us',
'url': url
}
-
Send this
payloadto ScraperAPI. This step is like asking ScraperAPI to visit Homes.com on our behalf, but with the added benefit of geotargeting, ensuring we’re focusing on properties in Los Angeles as US visitors would.
response = requests.get('https://api.scraperapi.com', params=payload)
By using ScraperAPI, we not only navigate around potential scraping issues but also ensure our data collection is relevant and focused.
Step 5: Parsing Homes.com HTML with BeautifulSoup
Once we receive a successful response from ScraperAPI, it’s time to parse the HTML.
Each time we go through the ten pages, properties_list grabs the
listings from that page. We keep adding these to our main properties list.
This way, by the end of our loop, properties has all the listings
from each page, giving us a full picture.
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
properties_list = soup.find_all('div', attrs={'class': 'for-rent-content-container'})
properties += propertites_list
Step 6: Exporting Homes.com Properties into CSV File
Now that we’ve successfully collected the property listings we wanted, it’s time to organize them in a CSV file. This step ensures that the property information is easily accessible for analysis or application use.
To get started, we open a 'properties.csv' file for writing. We’ll do
this using Python’s csv.writer, which helps us create a
structured CSV file for storing our scraped data.
with open('properties.csv', 'w', newline='') as f:
writer = csv.writer(f)
Using the csv.writer, we set up the file and define column
headers like 'title', 'address', and
'price'. This prepares our file to neatly store the property
information.
writer.writerow(['title', 'address', 'price', 'beds', 'baths', 'description', 'url'])
From here, we iterate over each property in the properties list. We’ll use
BeautifulSoup to pull out information from each property listing within this
loop and check if each element is present; if not, we use
'N/A' as a placeholder to avoid errors.
We search for the paragraph <p> element with the class
'property-name' to get the title.
title_elem = property.find('p', attrs={'class': 'property-name'})
title = title_elem.text.strip() if title_elem else 'N/A'
Similarly, we’ll obtain the address from a <p> tag with the
class 'address'.
address_elem = property.find('p', attrs={'class': 'address'})
address = address_elem.text.strip() if address_elem else 'N/A'
The <ul> element with the
'detailed-info-container' class contains a list of details, as we saw
in the HTML inspection. We’ll extract the list items for price, beds, and
baths from it.
info_container = property.find('ul', class_='detailed-info-container')
extra_info = info_container.find_all('li') if info_container else []
price = extra_info[0].text.strip() if len(extra_info) > 0 else 'N/A'
beds = extra_info[1].text.strip() if len(extra_info) > 1 else 'N/A'
baths = extra_info[2].text.strip() if len(extra_info) > 2 else 'N/A'
We’ll extract the description from the <p> tag with the
class 'property-description'.
description_elem = property.find('p', attrs={'class': 'property-description'})
description = description_elem.text.strip() if description_elem else 'N/A'
We get the URL from the href attribute of the <a> tag and
append it to the BASE_URL for a complete link.
url_elem = property.find('a')
url = BASE_URL + url_elem.get('href') if url_elem else 'N/A'
Note: It’s important to do this step because the URL showed
in the HTML is fragmented. In other words, you wouldn’t get the complete URL
without appeending BASE_URL to the extract link.

Once we’ve extracted all the details we needed from each property, we’ll write them as a new row in our CSV file. This way, each property’s information is stored in an organized and accessible format.
writer.writerow([title, address, price, beds, baths, description, url])
Step 7: Error Handling and Final Touches
Within our loop, we use a try-except block to catch any
exceptions during the get() request to ScraperAPI. This ensures
our script doesn’t crash if a request fails.
try:
response = requests.get('https://api.scraperapi.com', params=payload)
# Further processing
except requests.RequestException as e:
print(f"Request failed on page {page}: {e}")
We also check the response status before parsing the HTML. If the status code
isn’t 200 (success), we print an error message and skip the
parsing for that page.
if response.status_code == 200:
# Parse HTML
else:
print(f"Error on page {page}: Received status code {response.status_code}")
Finally, we conclude our script with a completion message.
print(f"Scraping completed. Collected data for {len(properties)} properties.")
With this final step, we not only confirm we’ve successfully scraped Homes.com but also provide a quick insight into the volume of data we managed to scrape, making it easier to verify and proceed with further analysis or application of the scraped data.
Wrapping Up
Congratulations, you’ve successfully built your first Homes.com scraper!
To summarize, today you’ve learned how to:
- Use Python and BeautifulSoup to scrape real estate data
- Export property data into a CSV file for easy analysis
- Employ ScraperAPI to bypass anti-scraping measures effectively and focus our scraping on region-specific data
Scraping Homes.com is crucial for staying ahead in the dynamic real estate market, whether for investment analysis, market research, or tailoring marketing strategies.
Note: The selectors in this article are chosen for their current accuracy and should work well. But websites change, so it’s wise to check them now and then to avoid errors. If you notice changes, just tweak your script a bit.
If you have any questions, please contact our support team – we’re eager to help. You can also check our documentation to learn the ins and outs of ScraperAPI.
Until next time, happy scraping!




