



In this article, you’ll learn how to:
- Extract data from AliExpress using Python and BeautifulSoup
- Export the scraped data as a CSV file
- Use ScraperAPI to bypass AliExpress anti-scraping mechanisms
Ready? Let’s get started!
TL;DR: Full AliExpress Scraper
Here’s the completed code for those in a hurry:
from bs4 import BeautifulSoup
import requests
import csv
# Specify the product URL
product_url = "https://www.aliexpress.com/item/1005005095908799.html"
# Set up headers and payload for Scraper API
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'accept-language': 'en-US,en;q=0.9,ur;q=0.8,zh-CN;q=0.7,zh;q=0.6',
}
payload = {'api_key': 'YOUR_API_KEY', 'url': product_url, 'render': 'true', 'keep_headers': 'true'}
# Make a request to Scraper API
response = requests.get('https://api.scraperapi.com', params=payload, timeout=60, headers=headers)
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
result = soup.find('div', attrs={'class': "pdp-info-right"})
# Extract and print product information
if result:
# GET PRODUCT NAME
product_name = result.find('h1', attrs={'data-pl': "product-title"}).text
# GET PRODUCT PRICE
price_div = result.find('div', attrs={'class': "price--current--H7sGzqb product-price-current"})
price_spans = price_div.find_all('span')
price = ''.join(span.text for span in price_spans[1:])
# GET PRODUCT RATING AND NUMBER OF REVIEWS
rating_div = result.find('div', attrs={'data-pl': "product-reviewer"})
rating = rating_div.find('strong').text
reviews = rating_div.find('a').text
# GET ORDER INFORMATION
orders_spans = result.find_all('span')
orders = ''.join(span.text for span in orders_spans)
# Open CSV File and Write Header
with open('aliexpress_results.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(['Product Name', 'Price', 'Rating', 'Reviews', 'Amount Sold'])
# Write data to CSV file
csv_writer.writerow([product_name, price, rating, reviews, orders])
print('Scraping and CSV creation successful!')
else:
print("No product information found!")
Before running the code, add your API key to the 'api_key' parameter within the payload.
Note: Don’t have an API key? Create a free ScraperAPI account to get 5,000 API credits to try all our tools for 7 days.
Want to see how we built it? Keep reading and join us on this exciting scraping journey!
Requirements
To get started with web scraping on AliExpress using Python, you’ll need a few tools and libraries. Follow these steps to set up your environment:
- Python Installation: Make sure you have Python installed, preferably version 3.8 or later.
- Library Installations: Open your terminal or command prompt and run the following command to install the necessary libraries:
pip install requests bs4
Libraries Overview
- Requests: The
requestslibrary serves as our communication tool in the AliExpress scraper. It acts as our agent, delivering requests to the ScraperAPI service, which, in turn, interacts with AliExpress to retrieve the information we seek. So, think of Requests as our way of politely asking ScraperAPI to fetch the data from AliExpress on our behalf. It’s the bridge that helps us connect to the data source seamlessly. - BS4 (BeautifulSoup):
BeautifulSoupis like a smart helper in Python that helps us grab information from websites. It’s excellent at understanding and navigating through web page code (HTML and XML). In our AliExpress scraper, we use BeautifulSoup to easily pick out the data we want from the messy web page code, making our job much simpler. It’s like having a neat and tidy assistant that fetches exactly what we need from the web pages.
Project Structure
- Create a new directory and Python file: Open your terminal or command prompt and run the following commands:
$ mkdir aliexpress_scraper
$ touch aliexpress_scraper/app.py
Now that you’ve set up your environment and project structure, you’re ready to proceed with the next part of the tutorial.
Understanding AliExpress Site Structure
Alright, let’s break down how AliExpress’s website is set up!
Think of this as navigating a big online mall, and we want to figure out how to grab important details. In this article, our focus is on scraping the product listing page of a particular product.
In the image below, we’ve highlighted the key components of the products we’ll be extracting:
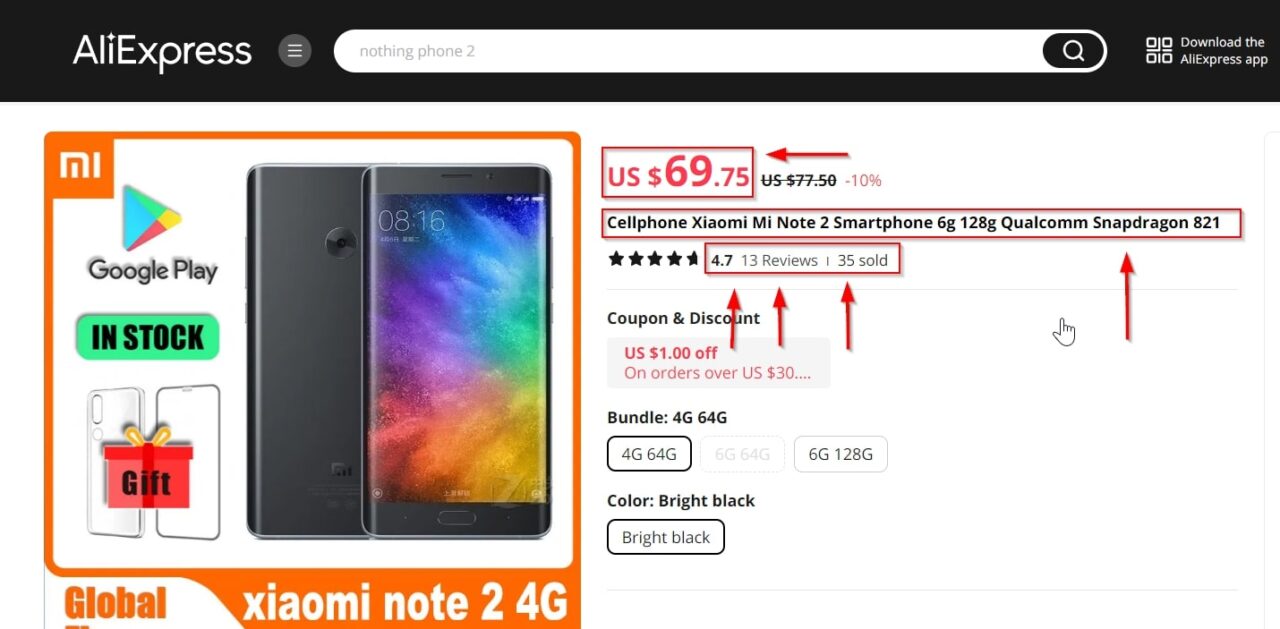
Using the developer tools, we can examine the elements we want to scrape and get the specific tags and their classes that we can use to target the elements we want to scrape.
This div is the main product container holding all the product information: .pdp-info-right
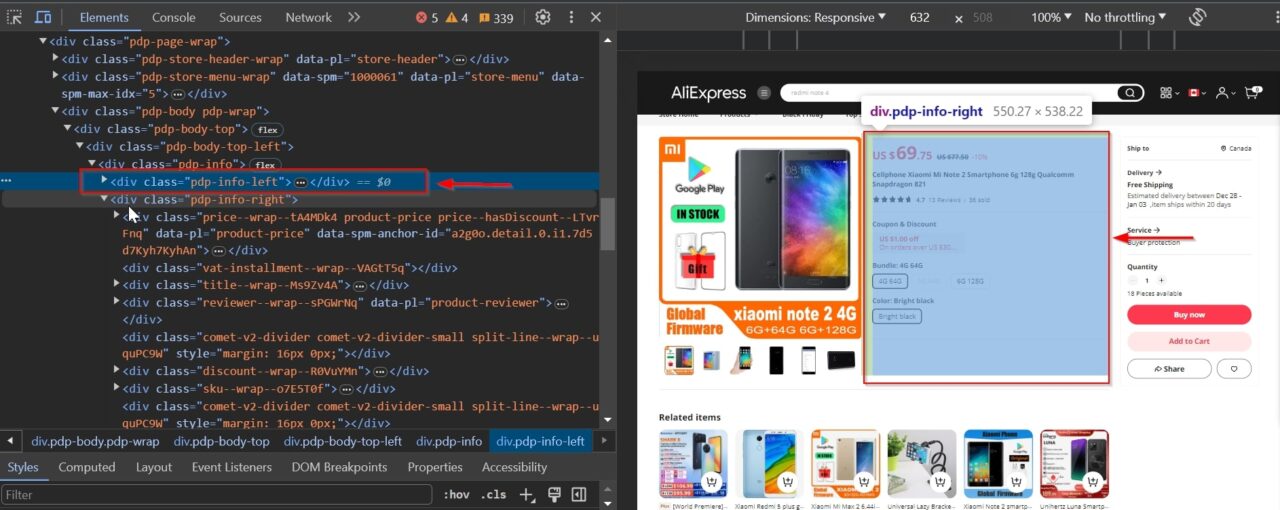
This div tag contains the product name: .product-title
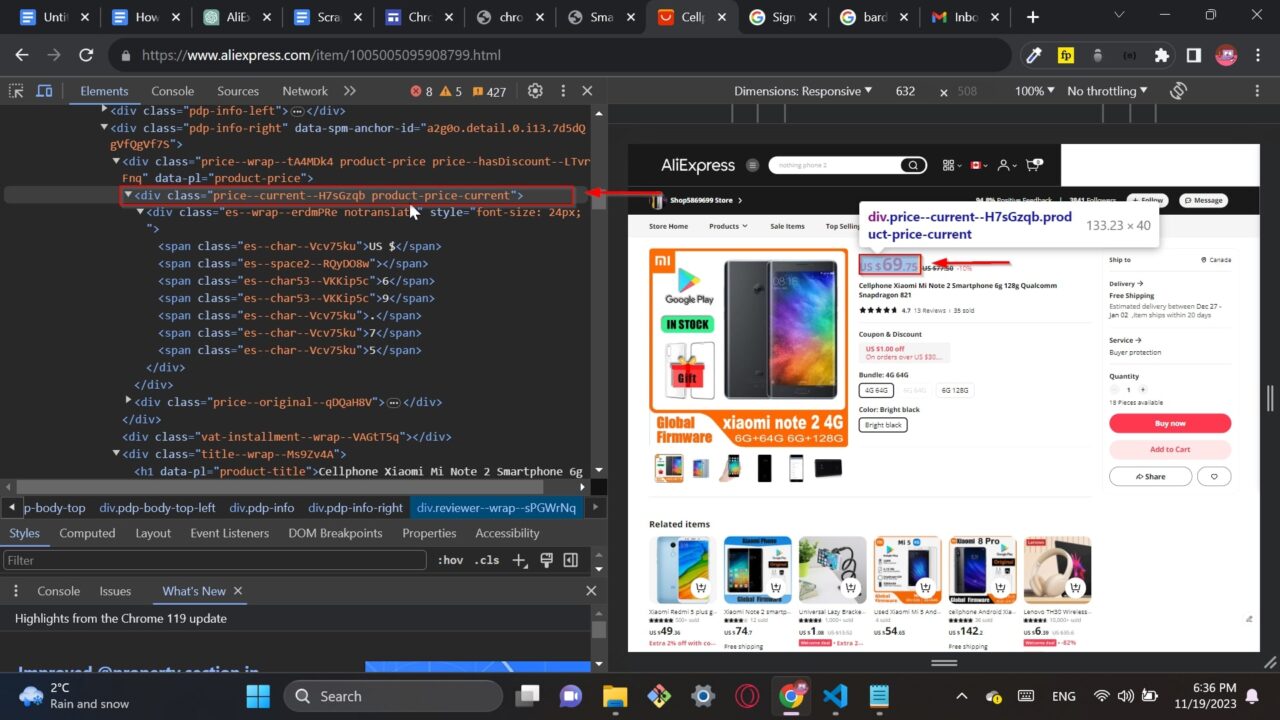
This div tag contains the price information: .price--current--H7sGzqb product-price-current
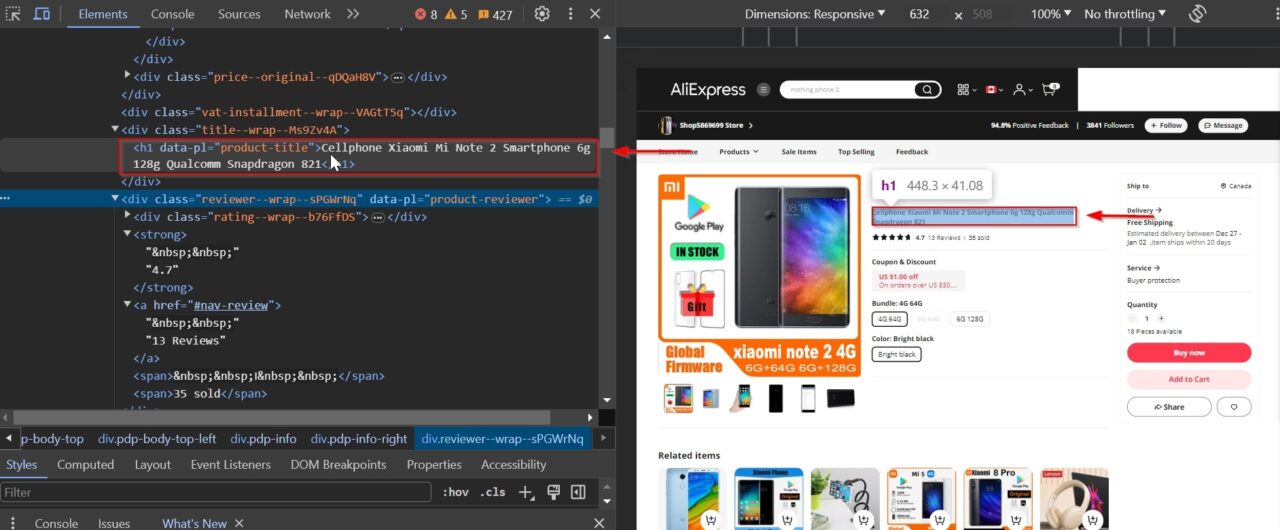
Ratings within reviews offer an additional dimension for evaluating product quality and customer sentiment.
This div contains information about reviews and ratings: .product-reviewer
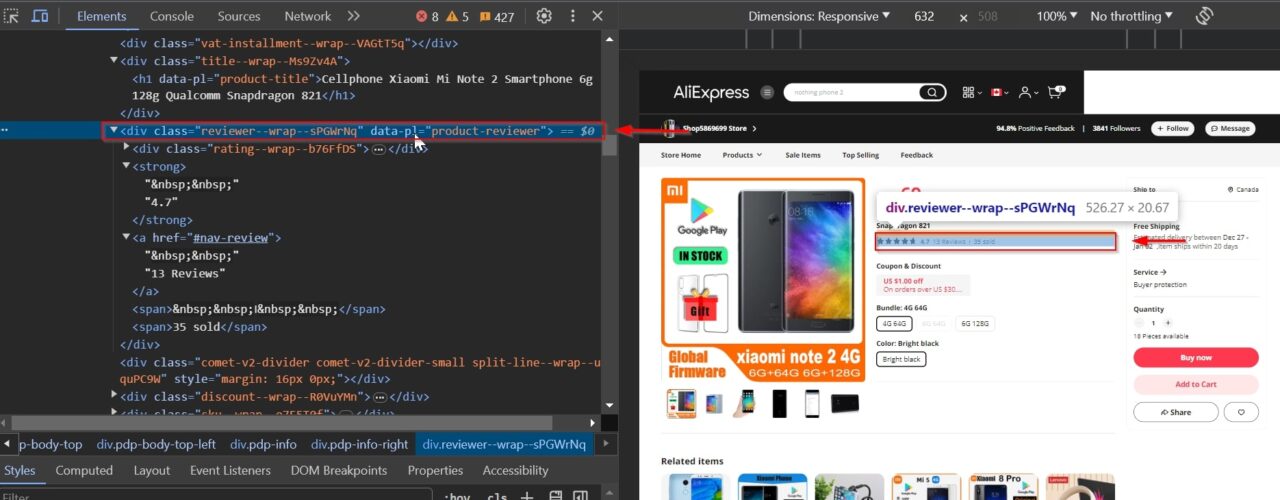
Having a clear understanding of the AliExpress site structure will streamline our data scraping process by helping us identify the elements of interest and the paths to get there.
Now that we have an action, let’s start scraping!
Scraping Target AliExpress Product Data
For this tutorial, we’ll focus on a particular product page, so you can just create a list of product URLs and use the same script to collect all major elements automatically.
Step 1: Setup Your Project
First, we need to import the libraries we plan to use in our scraper and specify the product URL.
from bs4 import BeautifulSoup
import csv
import requests
search_url = "https://www.aliexpress.com/item/1005005095908799.html"
Step 2: Send Your Request Through Scraper API
To be able to scrape AliExpress we’ll need to bypass its anti-bot detection. However, building the infrastructure to prevent getting blocked is both time-consuming and expensive.
Instead, we’ll send our requests through ScraperAPI and let it handle IP rotation, CAPTCHA handling, JavaScript rendering, etc.
Here’s what we’ll do:
- Setup custom “headers” to act as our identification for the server
- Write a “payload” that includes our API key, the specific URL of the product we want data from, enable JS rendering, and tell the API to use our headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'accept-language': 'en-US,en;q=0.9,ur;q=0.8,zh-CN;q=0.7,zh;q=0.6',
}
payload = {'api_key': 'YOUR_API_KEY', 'url': product_url, 'render': 'true', 'keep_headers': 'true'}
💡 Important
AliExpress injects the product information through AJAX, so the page needs to render before we can see the information.
Of course, browsers don’t have any issue with this, but our script will. To access the dynamic data from the page, we tell ScraperAPI to first render the page before returning the data.
Otherwise, we’d just get a blank page.
After that, we send our prepared instructions and details (headers and payload) to the API.
By making this request, we’re essentially asking the API to act on our behalf and fetch the information we’re interested in from the specified product URL.
response = requests.get('https://api.scraperapi.com', params=payload, timeout=60, headers=headers)
Step 3: Parse the Raw HTML with BeautifulSoup
Next, we need to create a BeautifulSoup object to parse the HTML content received from our request using the ‘html.parser’ and pick the main product container we identified earlier – which contains all the product information we need.
soup = BeautifulSoup(response.content, 'html.parser')
result = soup.find('div', attrs={'class': "pdp-info-right"})
Step 4: Extract Product Information
Using the specific tags and classes we identified earlier, we’ll grab the following details:
- Name
- Price
- Rating
- Number of reviews
- Order information
Also, let’s use an if statement to prevent errors if no product information was retrieved.
if result:
# GET PRODUCT NAME
product_name = result.find('h1', attrs={'data-pl': "product-title"}).text
# GET PRODUCT PRICE
price_div = result.find('div', attrs={'class': "price--current--H7sGzqb product-price-current"})
price_spans = price_div.find_all('span')
price = ''.join(span.text for span in price_spans[1:])
# GET PRODUCT RATING AND NUMBER OF REVIEWS
rating_div = result.find('div', attrs={'data-pl': "product-reviewer"})
rating = rating_div.find('strong').text
reviews = rating_div.find('a').text
# GET ORDER INFORMATION
orders_spans = result.find_all('span')
orders = ''.join(span.text for span in orders_spans)
Step 5: Write the Data to a CSV File
Awesome, we got the data! However, printing all this information to the terminal isn’t very useful, right? To finish our project, let’s store it in a CSV file.
Open a CSV file (‘aliexpress_results.csv’) in write mode, initialize a CSV writer, and write the header row to it.
It’s our way of organizing the information neatly before we start filling in the details.
with open('aliexpress_results.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(['Product Name', 'Price', 'Rating', 'Reviews', 'Amount Sold'])
Storing the details we’ve gathered for each product is like noting down key info in a table.
Each row represents one product, and each column holds a specific piece of information. This structured setup makes it easy to read and analyze later on.
Once all is done, we print a success message, signaling the completion of the task.
csv_writer.writerow([product_name, price, rating, reviews, orders])
print('Scraping and CSV creation successful!')
Error Handling
To make it full circle, we complete our if statement with the else part, this just lets us know the process of retrieving the scraped data was not successful.
else:
print("No product information found!")
Wrapping Up
Congratulations, you just scraped AliExpress!
In this journey, we’ve unveiled the essential steps and tools to gather valuable insights from the vast online marketplace by:
- Building an AliExpress scraper using Python and BeautifulSoup
- Using ScraperAPI to bypass bot detection and render the product page
- Exporting the data into a CSV file for later analysis
Scraping AliExpress can serve various purposes, providing essential data for decision-making in the online retail sector. You can use the scraped AliExpress product data for:
- Competitor analysis
- Tracking product prices
- Monitoring product reviews
- Managing product inventory
- Obtaining product images and descriptions
And much more.
If you have any questions, please contact our support team, we’re eager to help or check our documentation to learn the ins and outs of ScraperAPI.
Until next time, happy scraping!




