



Cloudflare-protected websites are perhaps one of the most difficult-to-scrape websites. Its automated bot detection demands you to come up with robust web scraping tool to bypass Cloudflare’s anti-scraping measures and extract its web data.
Today, we’ll show you how to scrape Cloudflare-protected websites using Python and the open-source Cloudscraper library. That said, while effective in some cases, you’ll discover Cloudscraper’s limitations and why a more robust solution like ScraperAPI is often necessary.
How Cloudflare Bot Detection System Works
Before exploring how to use Python and Cloudscraper to break through Cloudflare-protected websites, it’s crucial to understand how Cloudflare detects suspicious bots, including web scrapers.
Cloudflare’s bot management system is crafted to distinguish between malicious bots and legitimate traffic, such as search engine crawlers. By analyzing incoming requests, it identifies unusual patterns and blocks suspicious activity to maintain the integrity of websites and applications.
Cloudflare’s layered security approach combines passive and active detection methods. Passive detection analyzes various factors, such as IP addresses, HTTP headers, and TLS fingerprints. Active detection methods further strengthen the defense by challenging potential bots with dynamic tests using CAPTCHAs and canvas fingerprinting. This two-pronged strategy enables Cloudflare to adapt to the ever-evolving landscape of bot attacks and ensure the security of websites.
Unfortunately, web scrapers are often flagged as malicious bots by Cloudflare’s detection system. If you’ve ever attempted to scrape a Cloudflare-protected website, you might have encountered common bot management errors, such as access denied (Error 1010, 1012, 1020) and rate limiting (Error 1015). These errors are often accompanied by a 403 Forbidden HTTP response.
That said, there are strategies to bypass these protections and successfully extract data. In the following sections, we will explore effective web scraping methods using Python and Cloudscraper to overcome Cloudflare’s strict bot defenses.
How to Use Cloudscraper to Scrape Cloudflare Protected Websites
To give you a practical example on how to easily bypass Cloudflare anti-bot system, we’ll scrape Glassdoor pages at a low scale.
If you are an advanced web scraping user, skip to the “ScraperAPI: A More Powerful Alternative to Cloudscraper.” By using the API from ScraperAPI, you can achieve higher scalability, schedule jobs, and automate the scraping of Cloudflare-protected websites.
Step 1. Setting up the prerequisites
Make sure you have Python installed on your system. You can use Python version 3.6 or higher for this tutorial. Go ahead and create a new directory where all the code for this project will be stored, and create an app.py file within in:
</p>
<pre>$ mkdir web_scraper
$ cd web_scraper
$ touch app.py</pre>
<p>Next, you need to install cloudscraper and requests. You can easily do that via PIP:
</p>
<pre>$ pip install cloudscraper requests</pre>
<p>Step 2. Making a simple request using requests
You will be scraping Glassdoor in this tutorial. Here is what the homepage of Glassdoor looks like:
This website is protected by Cloudflare and can not easily be scraped using requests. You can confirm that by making a simple GET request using requests like this:
</p>
<pre>import requests
html = requests.get("https://www.glassdoor.com/")
print(html.status_code)
# 403</pre>
<p>As expected, Glassdoor returns a 403 Forbidden status code and not the actual search results. This status code is returned by the Cloudflare Bot detection system that Glassdoor is using. You can save the response in a local file and open it up in your browser to get a better understanding of what is going on.
You can use this code to save the response:
</p>
<pre>with open("response.html", "wb") as f:
f.write(html.content)</pre>
<p>When you open the response.html file in your browser, you should see something like this:
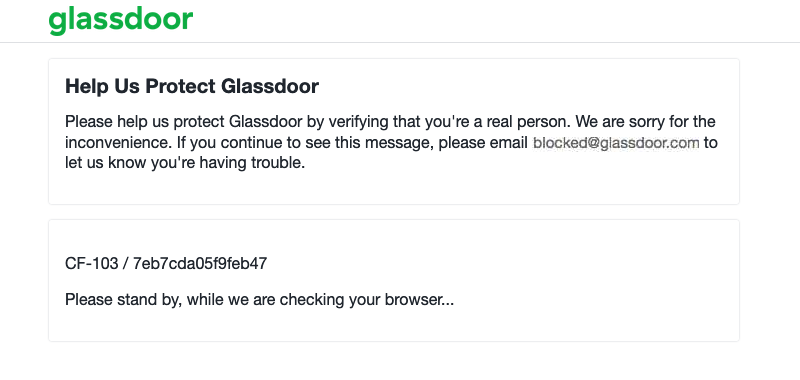
Now that you know your target website is being protected by Cloudflare, do you have any viable options to bypass it?
Step 3. Scraping Glassdoor.com using Cloudscraper
Luckily this is where Cloudscraper comes in. It is built on top of Requests and has some intelligent logic to parse the challenge page returned by Cloudflare and submit the appropriate response to successfully get around it. Its biggest limitation is that it can only bypass Cloudflare bot detection version 1 and not version 2. However, if your target website is using bot detection version 1 then this is a very reasonable solution. We will discuss this limitation in detail in an upcoming step.
Another noteworthy fact is that Cloudscraper does not run a complete browser engine by default. Therefore, it is considerably faster than other similar solutions that rely on headless browsers or browser emulation.
Note: If you are trying to scrape a website that is using version 2 of Cloudflare’s bot detection system, you can save some time and skip to the very end of this tutorial and read about ScraperAPI as that is a potential solution for your use case.
Let’s repeat the same GET request to Glassdoor.com but this time using Cloudscraper. Open up the Python REPL and type this code:
</p>
<pre>import cloudscraper
scraper = cloudscraper.create_scraper()
html = scraper.get("https://www.glassdoor.com/")
print(html.status_code)
# 200</pre>
<p>Sweet! Cloudflare did not block our request this time. Go ahead, save the html into a local file as we did in the previous step, and open it up in your browser. You should see the homepage of Glassdoor. The UI is a bit wonky because of broken CSS and JS links (as we haven’t saved the CSS and JSON locally) but all the data is there:

Just by changing a few lines of code, you were able to bypass Cloudflare’s bot detection system!
Step 4. Using advanced options of Cloudscraper
Cloudscraper provides a ton of configurable options out of the box. Let’s take a look at a few of them.
4.1 Built-in support for captcha solvers
Cloudscraper has built-in support for a few 3rd Party Captcha Solvers in case you might need them. For example, if your requests are hitting a captcha page, you can simply hook up 2captcha with Cloudscraper as a captcha solution provider:
</p>
<pre>scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': 'your_2captcha_api_key'
}
)</pre>
<p>So far, Cloudscraper supports the following captcha services out of the box:
- 2captcha
- anticaptcha
- CapSolver
- CapMonster Cloud
- deathbycaptcha
- 9kw
- return_response
4.2 Using a custom proxy
More often than not, you will want to route all of the scraping traffic through a proxy. This will make sure your real IP is masked and is not banned by the target website for excessive requests. Thankfully, Cloudscraper provides support for using custom proxies. This comes as a side-effect of Cloudscraper being built on top of the amazing requests library.
If you want to use a custom proxy with Cloudscraper, you can define a dictionary containing the HTTP and HTTPS proxy endpoints and Cloudscraper will make sure to use the appropriate one for any future requests. Here is some code that demonstrates this:
</p>
<pre>import cloudscraper
proxies = {"http": "http://localhost:8080", "https": "http://localhost:8080"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://www.glassdoor.com/")
print(html.status_code)
# 200</pre>
<p>You can further enhance this custom proxy setup by adding logic for rotating proxies. Look at this other article on our website to learn how to do that.
4.3 Extracting just the Cloudflare token
When you bypass Cloudflare bot detection, Cloudflare responds with a cookie that has to be passed with all follow-up requests to the target website. This cookie informs Cloudflare that your browser has already passed the bot detection challenge and should be allowed to go through without additional challenges. Cloudscraper provides handy methods to extract this cookie (or the tokens within it). Here is how you can use them:
</p>
<pre>import cloudscraper
tokens, user_agent = cloudscraper.get_tokens("https://www.glassdoor.com/")
print(tokens)
# {
# 'cf_clearance': 'c8f913c707b818b47aa328d81cab57c349b1eee5-1426733163-3600',
# '__cfduid': 'dd8ec03dfdbcb8c2ea63e920f1335c1001426733158'
# }
cookie_value, user_agent = cloudscraper.get_cookie_string("https://www.glassdoor.com/")
print(cookie_value)
# cf_clearance=c8f913c707b818b47aa328d81cab57c349b1eee5-1426733163-3600; __cfduid=dd8ec03dfdbcb8c2ea63e920f1335c1001426733158</pre>
<p>This is very useful as it allows you to use Cloudscraper to bypass the bot detection system and then use the resulting cookies with the follow-up requests from your pre-existing web scraping code. You just need to make sure that the follow-up requests are generated from the same IP as the one used while bypassing the bot detection system. If the IPs are different, Cloudflare will block your request and ask you to re-verify.
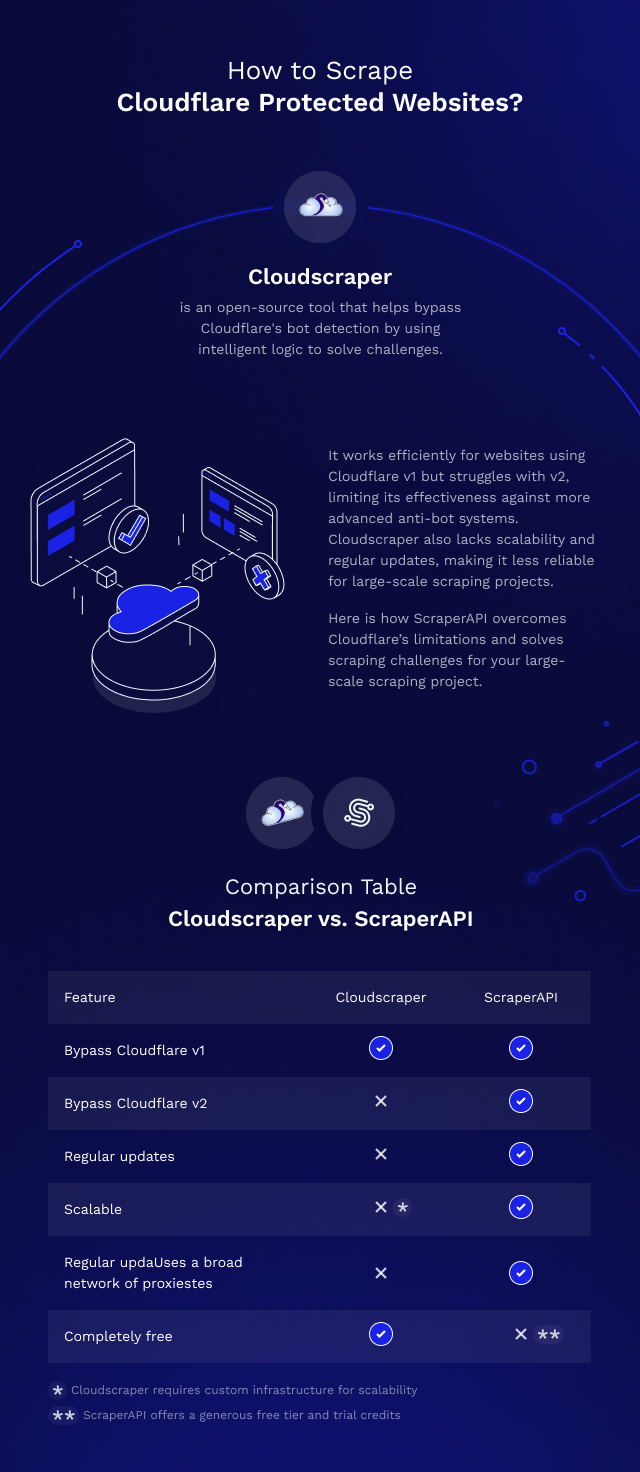
Limitations of Cloudscraper: When Scraping Cloudflare Protected Websites Isn’t Possible
A. Cloudflare’s Free Version vs. Cloudflare V2
We mentioned earlier that Cloudscraper has a few limitations and not being able to scrape websites protected by Cloudflare bot detection v2 is a major one. This is the newer version of bot detection provided by Cloudflare and is currently being used by quite a few websites. One such website is Author.
Here is what the homepage of Author looks like:
If you try to scrape data from this website using Cloudscraper, you will see the following exception:
</p>
<pre>cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.</pre>
<p>Even though this exception alludes to the existence of a paid version of Cloudscraper, there isn’t one. Unfortunately, Cloudscraper completely falls apart in the face of the latest bot detection algorithm used by Cloudflare.
B. Scraping JavaScript Content
Cloudscraper might struggle with advanced JavaScript challenges implemented by Cloudflare. These challenges often require solving complex puzzles or interacting with dynamic elements, which can be difficult for automated tools like Cloudscraper to navigate.
C. Rate Limiting
Cloudflare often imposes rate limits on requests to prevent abuse. Cloudscraper might not be able to effectively manage these limits, leading to delays or failed requests.
D. Evolving Bot Detection Techniques
Cloudflare is constantly updating its bot detection techniques. Cloudscraper, as an open-source tool, may not always keep up with these changes, making it less effective over time.
ScraperAPI: A More Powerful Alternatives to Cloudscraper
If you want to scrape websites that Cloudscraper can not currently scrape or if you want to achieve scale and better performance, you should look into Cloudscraper alternatives. One of the best alternatives available today is ScraperAPI.
ScraperAPI can handle the latest version of the bot detection algorithm used by Cloudflare and is regularly updated with new anti-bot evasion techniques to keep your scraping jobs running smoothly.
Plus, ScraperAPI also offers other web scraping benefits that improve your overall data extraction projects. Some of them are:
- Structured data endpoints: gather structured data in a JSON format using ScraperAPI’s Amazon APIs, Google APIs, and more.
- DataPipeline: schedule data collection process for up to 10,000 URLs with minimum code.
- Forever free plan or 7-day free trial: leverage ScraperAPI’s generous free plan, offering 1,000 recurring API credits, or take advantage of the 7-day free trial with 5,000 API credits to experience this powerful web scraping tool firsthand.
You can quickly get started by going to the ScraperAPI dashboard page and signing up for a new account:
After signing up, you will see your API Key and some sample code:
The quickest way to start using ScraperAPI without modifying your existing code is to use ScraperAPI as a proxy with requests. Here is how you can do so:
</p>
<pre>import requests
proxies = {
"http": "http://scraperapi:APIKEY@proxy-server.scraperapi.com:8001"
}
r = requests.get('https://author.today/', proxies=proxies, verify=False)
print(r.text)</pre>
<p>Note: Don’t forget to replace APIKEY with your personal API key from the dashboard.
This is it! With just a few lines of code, you don’t have to think about Cloudflare’s bot detection system again. ScraperAPI will make sure it uses unblocked proxies and advanced techniques to evade the bot-detection system in place. Now, you can spend more of your time focusing on your core business logic.





