



Is your Amazon web scraping project facing challenges like frequent blocks or inconsistent performance? Selecting the right Amazon API is crucial for ensuring seamless and reliable data extraction.
After evaluating various web scraping tools and proxies, we’ve curated a list of the top five Amazon API options. These tools excel in their unique features, pricing, and reliability, making them ideal for extracting various Amazon data.
TL;DR: 5 Top Amazon APIs for Web Scraping
Here are the leading 5 Amazon scraping APIs we’re going to compare:
- ScraperAPI: Best Amazon API to collect structured JSON data with a simple API call
- Octoparse: Best no-code tool to build local scrapers with a visual interface
- Bright Data: Best Amazon datasets seller
- ScrapingBee: Great proxies with a built-in headless browser
- Zyte: Best Scrapy manager and alternative datasets seller
TL;DR — When it comes to Amazon APIs, ScraperAPI offers a compelling solution. While we may have a vested interest, we believe ScraperAPI’s comprehensive tooling sets it apart from other providers.
One of ScraperAPI’s key advantages is its structured data endpoint. This allows you to extract JSON data from any Amazon page, including products, searches, reviews, and more. This structured format simplifies data analysis and integration.
1. ScraperAPI: Best Amazon API for Web Data Scraping
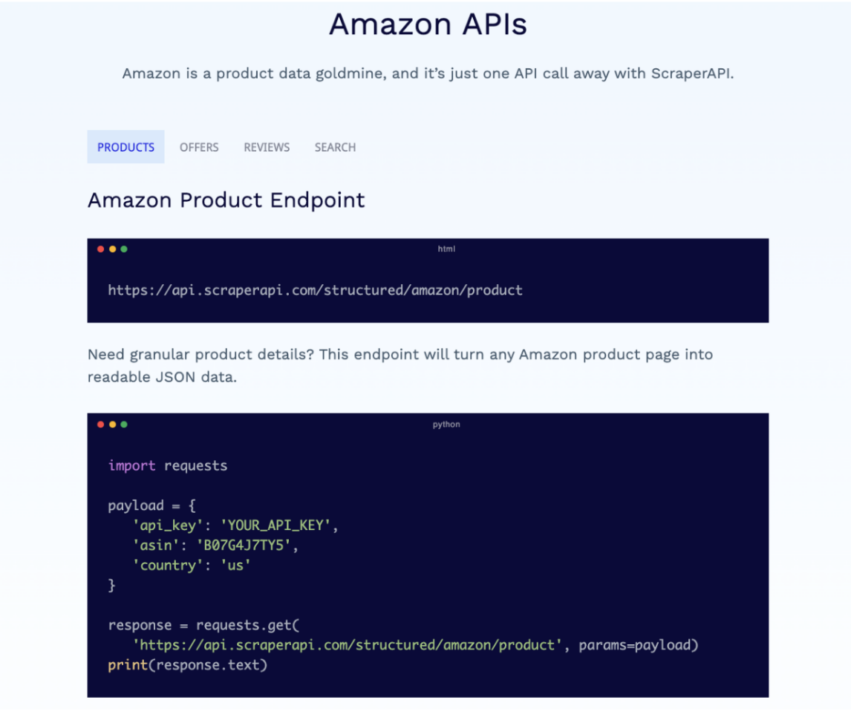
ScraperAPI is a robust web scraping solution designed to be easy to use, reliable, and consistent. It uses machine learning and years of statistical analysis to choose the right IP address and headers to guarantee a successful request.
It offers the most comprehensive set of tools for developers and data teams like:
- A pool of 40M+ IP addresses– including data center, residential and mobile proxies – across 50+ countries
- Smart IP rotation system to ensure 99.99% success rates
- CAPTCHA handling
- JavaScript rendering
- Simple-to-use structured data endpoints to collect JSON data from domains like Google, Amazon, and Twitter
Its Amazon API allows you to collect data from any Amazon property in JSON format with a simple API call, including scraping Amazon product data.
For example, with the product ASIN number, you’ll be able to use the Amazon Product endpoint to turn this:
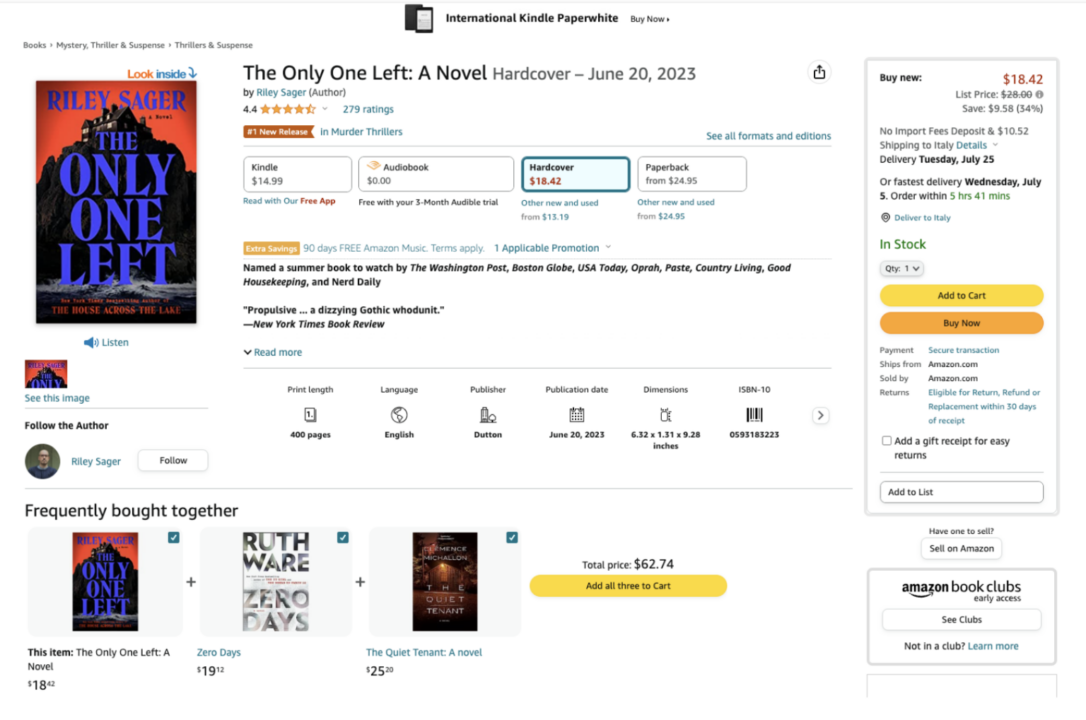
Into this:
{
"name":"The Only One Left: A Novel",
"product_information": {
"publisher":" Dutton (June 20, 2023)",
"language":" English",
"hardcover":" 400 pages",
"isbn_10":" 0593183223",
"isbn_13":" 978-0593183229",
"item_weight":" 1.35 pounds",
"dimensions":" 6.32 x 1.31 x 9.28 inches",
.
.
.
}
}
In the background, ScraperAPI takes care of any complexity thrown your way, ensuring a 99.99% success rate.
You can also use ScraperAPI’s standard API to bypass Amazon’s anti-scraping mechanism and get the raw HTML response, scaling your data collection project while avoiding getting blocked.
With ScraperAPI, you have complete control over the data you get and can either leave the parsing of the page to ScraperAPI or take it into your hands. The choice is yours!
Learn how to use ScraperAPI’s structured data endpoints with our simple-to-follow tutorial, or get started for free with 5,000 API credits.
Pros:
- Collect formatted Amazon data with a simple API call
- Save time on parsing
- Get access to 40M+ IP addresses and a built-in intelligent IP rotation
- Built for enterprise use without the price tag
- Integrates with any system and supports every tech-stack
Cons:
- You need a moderate level of programming experience
Related: Discover the 10 best-rotating proxies for Amazon data scraping.
2. Octoparse: Best No-Code Option Amazon API
Octoparse is a desktop, no-code software that allows you to build your own scrapers using a visual interface. Because it’s no-code, it is an excellent choice for beginners or for teams without coding experience.
The tool works by navigating to a URL and pointing and clicking on the elements you want to collect data from. Every click is recording a step, and once you have the entire workflow defined, you can run the task and export the data once it’s done processing.
The best part is that it counts with ready-to-use templates that can save you time. In the case of Amazon, there are multiple templates available to collect product data, reviews, and more:
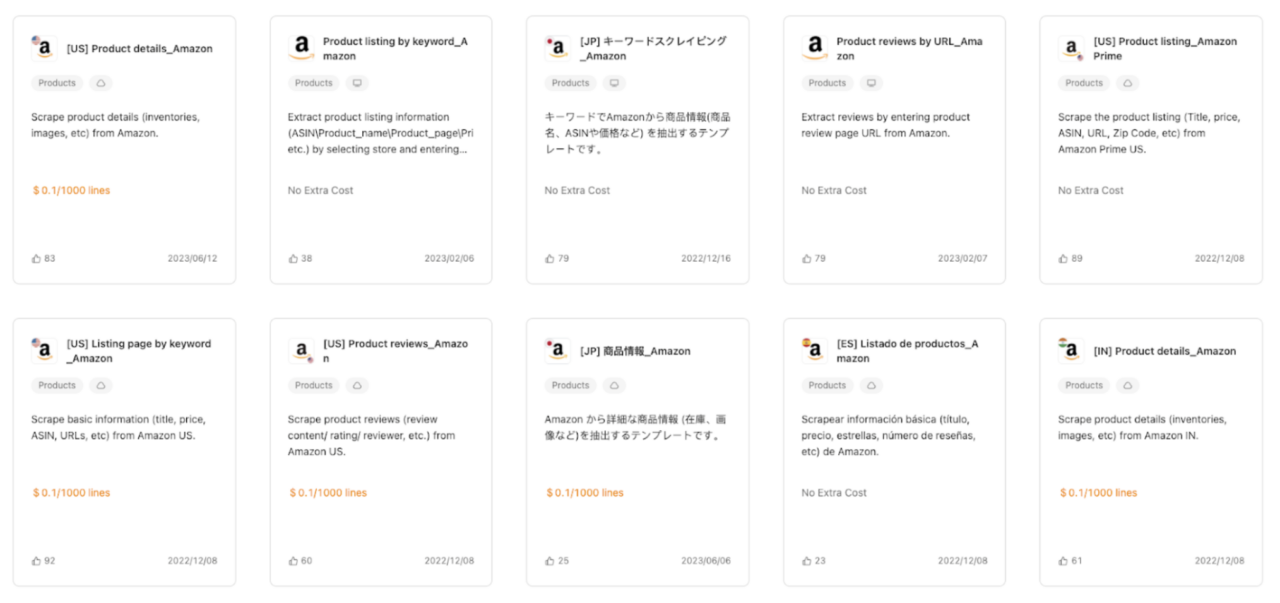
Related: Learn how to build an Amazon review scraper in 5 minutes!
Of course, there are some tradeoffs:
- Although you don’t necessarily need to know how to code, in many cases, you’ll need to understand at least how to fine- tune XPath selectors to avoid getting irrelevant data or getting locked out of an element because the tool can’t automatically pick the right expression.
- Because the tool works with XPath selectors, changes on your target page’s structure can break your scrapers.
- Being a local software, the more tasks you run, the more demanding it’ll be on your machine, so you’ll have to take into account your infrastructure if you’re planning to use Octoparse in an enterprise environment.
Pros:
- No coding skills required
- Easy-to-use visual interface
- Ready to use templates for several Amazon domains
Cons:
- Dependent on your local machine’s infrastructure
- Requires some knowledge of XPath selectors
- Susceptible to break if your target websites change their structure
3. Bright Data: Best Datasets Sellers Amazon API
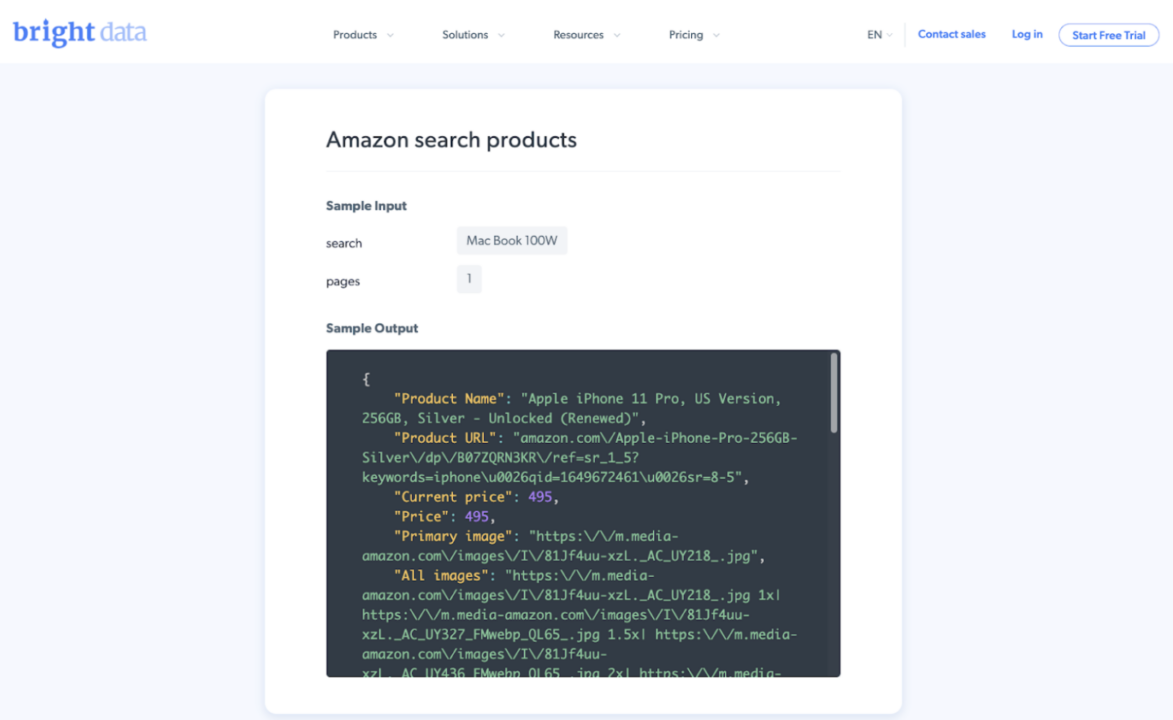
Bright Data is a compilation of data collection tools, including proxy pools, web scraping integrated development environments (IDE), and on-demand datasets.
Similar to ScraperAPI, Bright Data offers an IDE to help you pull structured JSON data from Amazon and has some ready-to-use templates to speed up development time. However, Bright Data’s IDE only works with JavaScript, so if you don’t have advanced knowledge in JS, you won’t be able to use their IDE.
Note: Additionally, the tool is very opinionated on how you must build your scrapers, which makes it harder to use than the simple get() request ScraperAPI requires.
Another factor to keep in mind is cost. As you can see in our ScraperAPI vs. Bright Data comparison, the latter is way more expensive. For example, enterprise companies using Bright Data’s proxy pools can save up to $77k a year by switching to ScraperAPI.
That said, where Bright Data definitely shines is in its on-demand Amazon datasets. Just specify the information you need and from which Amazon properties and you’ll get access to over 300M records.
This is a perfect choice for teams that don’t want to develop their own scrapers or don’t have the skills to do so.
Pros:
- Access to over 300M Amazon records
- Customizable data points and delivery methods
- Regular updates to already purchased datasets
Cons:
- The most expensive tool on the list
- For more granular and independent scraping, you’re locked to JavaScript
- Competitors can have access to the same data as you
Related: Discover the top 5 BrightData alternatives for scraping Amazon data.
4. ScrapingBee: Best for Built-In Headless Browser Amazon API
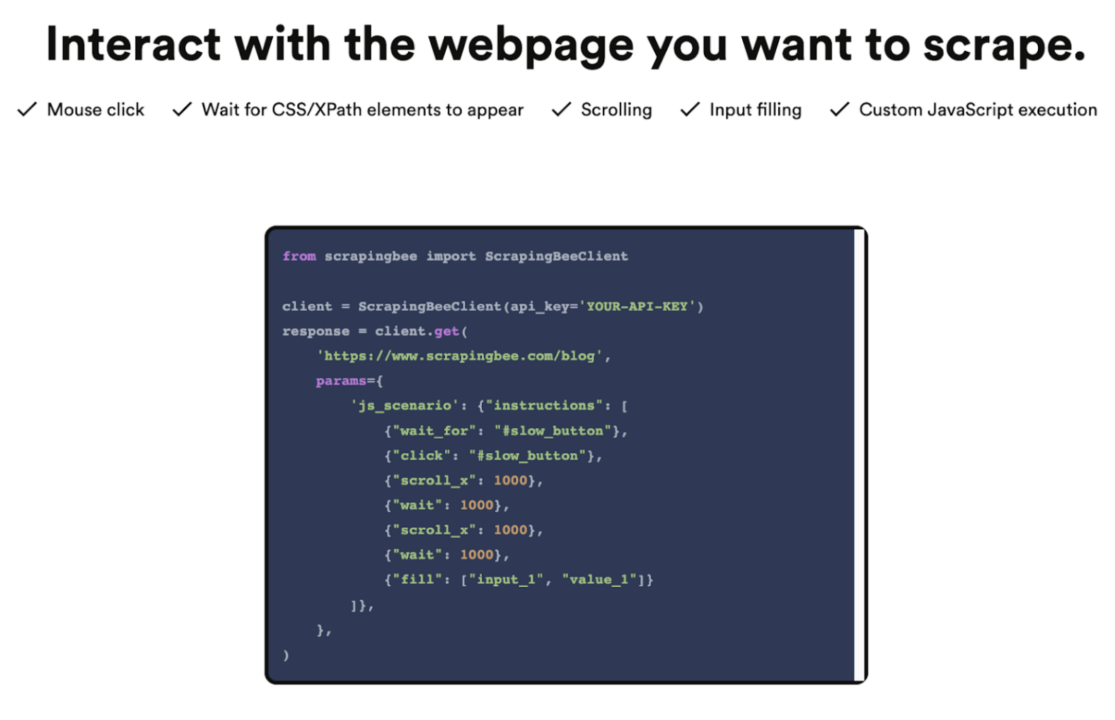
ScrapingBee is a web scraping solution designed to handle IP rotation and headless browsers, using a real browser instance (chrome) to render your target site for extraction.
ScrapingBee differs from other solutions in this list because it offers a “JavaScript Scenario” feature that allows you to control its built-in headless browser, giving you the ability to interact with the website.
As a point of comparison, ScraperAPI’s rendering feature will render your target page before returning its HTML – helping you collect data from single-page applications –but doesn’t provide an interface to interact with the website.
Still, this is a feature you’re not likely to use to scrape Amazon.
However, it’s worth noting that ScrapingBee comes with a higher price tag than ScraperAPI, charging extra for features like geotargeting – which is necessary to scrape localized Amazon data.
Check our ScrapingBee vs. ScraperAPI comparison.
Pros:
- Provides built-in tools to interact with dynamic websites
Cons:
- More expensive than similar tools like ScraperAPI
- Features like geotargeting are locked behind premium proxies, adding a higher cost to scrape localized data
- It doesn’t have a dedicated Amazon endpoint
5. Zyte: Best Scrapy Manager Amazon API

Zyte (formerly ScrapingHub) is a collection of web scraping tools like a smart proxy manager and an API similar to ScrapingBee. It also offers pre-built datasets and automatic web scrapers that are capable of extracting e-commerce data using specific data types.
However, what makes Zyte stand out from the rest in the list is its Scrapy Cloud service, which allows you to deploy your own spiders using Zyte’s infrastructure.
Just like Bright Data, Zyte also sells pre-built datasets – potentially including Amazon product information.
That said, Zyte can be more expensive than ScrapingBee and ScraperAPI, and its pricing is not as clear. There’s a lot of emphasis on letting their team build your scrapers, so if you’re looking to outsource your data collection efforts and can afford the price tag, it might be the best solution for you.
Pros:
- A comprehensive number of web scraping options
- Pre-built datasets ready to buy
- Offers a Scrapy infrastructure to deploy your spiders to the cloud
Cons:
- More expensive than similar tools on the list
- It can be quite complex to use
- There’s no Amazon specific endpoint
- Vague pricing model
ScraperAPI Offers The Best Amazon API for Extracting Amazon Data
Each tool in the list has its own strengths and weaknesses and can be used to pull data out of Amazon properties without getting blocked or breaching terms of service.
However, in 8 out of 10 scenarios, ScraperAPI is the best Amazon API you can use to collect data at an enterprise scale without breaking the bank.
It offers a reliable infrastructure to ensure bypassing any anti-scraping mechanism in your way with a simple API call, turning any Amazon page (product, reviews, search, etc.) into structured JSON data, and making it easy to integrate into your own tools, workflows or any other project you have in mind.
If you’re ready to collect data faster and more consistently than ever, try ScraperAPI for free with 5,000 API calls and all premium features.
Until next time, happy scraping!
The Best Amazon API for Web Scraping – FAQs
Find the answers to the most common questions about Amazon API, scraping Amazon data, and ScraperAPI.
1. Why Scrape Amazon Data?
Scraping Amazon allows you to gather pricing data, conduct market research, manage product catalogs, analyze content, and explore product opportunities, helping you make data-driven decisions.
With Amazon data, you can also create tools like pricing monitors or product comparisons, to mention just a couple.
2. How Does Amazon Detect Scrapers?
Amazon employs various techniques to detect scrapers, including analyzing user behavior patterns, monitoring excessive requests from IP addresses, employing CAPTCHAs, tracking abnormal browsing activity, and using machine learning algorithms to identify scraping patterns.
To bypass these mechanisms, use ScraperAPI’s Amazon endpoint, which allows you to collect structured JSON data from any Amazon domain and page type with a simple API call – never get blocked again!
3. Do I Need an API to Scrape Amazon Data?
Amazon uses advanced anti-scraping mechanisms that will detect any scraper after just a few requests. If you don’t want to get blocked and banned permanently from the platform, the best solution is to use a web scraping tool to hide your real IP, handle proxy rotation and make the data collection process smoother and more secure.
4. Is It Legal to Scrape from Amazon?
Scraping publicly available data from any website is 100% legal. As long as you avoid collecting data behind logins or paywalls, you won’t have any problems scraping product data from Amazon.
For more information, check our guide on the legalities of web scraping.




