



PHP is a widely used backend language. Hated by many, and used for a lot of applications like WordPress. However, when thinking about web scraping PHP isn’t the first option that comes to mind.
With tools like Scrapy for Python or Cheerio for Node.js making web scraping simple, it’s hard to imagine why to use PHP to scrape data. Until you learn all the different options you have with it.
Because it has an active community and has been around for so long, PHP has a lot of tools to make web scraping not only simpler but more powerful.
If you already know PHP or you’re interested in learning a backend language with the ability to extract web data fast and efficiently, then this tutorial is for you.
Today, we’re going to explore a few of the tools you’ll have at your disposal and do a real-life code example to build your first web scraper with PHP.
Choosing a PHP Web Scraping Library
There are plenty of ways to do web scraping in PHP. But the most efficient way is to use a library that has built-in all the tools you need to download and parse URLs.
Otherwise, we would have to spend more time and write more complex code to do simple tasks like sending an HTTP request.
If we were going to divide web scraping into its core tasks, it would look like this:
- First, we would send an HTTP request to a server to get the source code of the page.
- Then, we would have to parse the DOM to identify and filter the information to extract the data we need.
- Finally, we would want to format the data to make it more understandable – like into a CSV or JSON file.
Just for the HTTP request, we could use several different methods like:
- fsockopen() – which although not use for doing HTTP requests, is totally possible to do so. Of course, it would require a lot of unnecessary code that we don’t really want to write.
- cURL – which is a client for URLs that allows you to perform HTTP requests with ease but won’t be very helpful to navigate the HTML file and extract the data we’re looking for.
- Using an HTTP client like Guzzle or Goutte – which would also make parsing the HTML DOM tree easier than the previous options.
As you can see, the last two are what we’re calling a ready-to-use tool for web scraping with PHP.
Why Using Goutte for PHP Web Scraping?
You already know we’re going to use Goutte for this example – spoilers from the title -, but do you know why?
Guzzle is definitely a great option for web scraping. It simplifies making the HTTP request and has the ability to parse the downloaded file to extract data.
The problem is that to make it happen, we would have to turn the downloaded HTML file into a DOMDocument and then use XPath expressions to navigate the document to select the nodes we want to get.
These add extra steps that we can overcome easily using Goutte instead.
Goutte is an HTTP client built for web scraping by Fabian Potencier, creator of the Symfony framework.
This library combines four Symfony components that make web scraping very simple and elegant:
- The BrowserKit – which simulates the behavior of a browser.
- The DomCrawler – this component allows us to navigate the DOM document with expressions like
$crawler = $crawler->filter('body > h2');and many other methods. - The CssSelector – this component makes selecting elements super easy by allowing us to use CSS selectors to pick an element and then transform it into the corresponding XPath expression for us. For example, this snippet
$crawler->filter('.fire');will find all the elements withclass="fire". - The Symfony HTTP Client – this is the newest component and has gained a lot of popularity since realized in 2019.
For these reasons, we’ll be using Goutte for the rest of this tutorial.
Note: we’ll be publishing a Guzzle tutorial in the future so stay tuned to our blog and social media.
Building a Web Scraper With PHP and Goutte
Before we can actually start writing our code, it’s important to understand the structure of the site we want to scrape.
For this tutorial, we’ll be scraping NewChic’s women t-shirt page to extract the:
- Name of the t-shirt
- Link to the piece
- Price
A scraper like this can be used for eCommerce businesses that want to do a competitive analysis.
Let’s start by inspecting the page.
1. Inspect the Page Using the Browser Dev Tools
On our target website, right-click over the page and click on ‘inspect’ – alternatively, you can hit ctrl + shift + c.
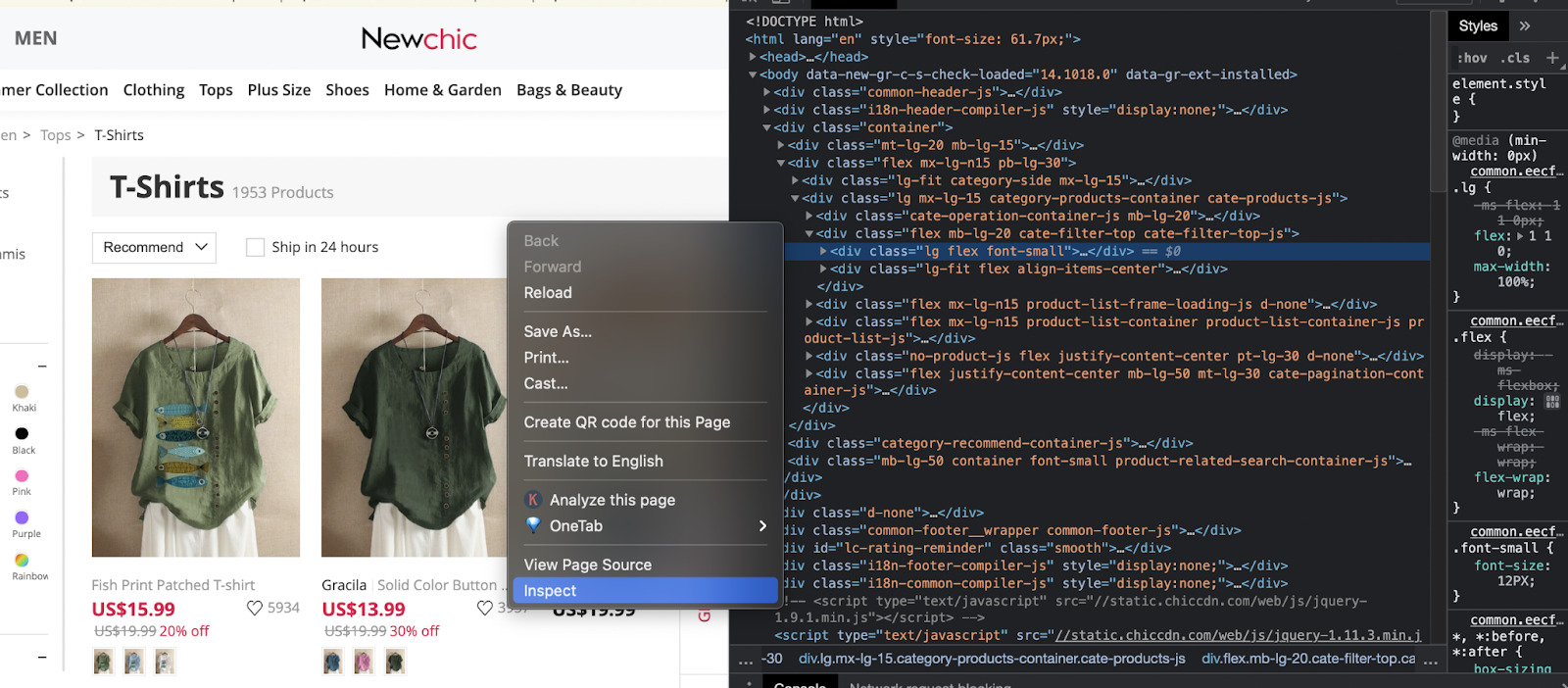
It will open the inspector tool on your browser.
What we’re seeing in the HTML code our browser is using to display the page. Every line has information about an element on the page.
What we really care about is the tags, classes, and IDs for each element, as these are the details we’ll use to make our scraper find the information we need.
So, let’s start with the title of the cloth. For that, right-click over the element and inspect it.

We can see that the name of the t-shirt is wrapped between <a> tags inside <p> tags.
That said, it surely isn’t the only link on the page. If we just use the tag of the element, we would be pulling all the links from the page, including navigation links, footer links, and everything else.
That’s where classes come into the game.
For the t-shirt’s name, the <a> tag has the class “lg text-ellipsis d-block text-hover-underline text-secondary-hover font-small-12 text-grey product-item-name-js“. So we want to make sure that all the other elements use the same class.

After checking a few more, they all use the same class which is perfect for us, as we can then use it to select our titles and the link.
Note: we’ll explore how to extract the href attribute of an <a> tag later on.
Next, we’ll do the same thing for each element:
- For the price:
span class="product-item-final-price-js price product-price-js font-middle font-bold text-black-light-1“
- For the link: we’ll use the same as for the title but instead of getting the text, we’ll be pulling the href value.
2. Install PHP and all Necessary Dependencies
Before we download any file, let’s first check if we have any version of PHP already installed. Type into your terminal php -v.

This is the notification we get because we’re using an M1 Macbook. What’s important is that we have version 7.3.24 of PHP.
If you don’t have it installed, then follow these steps to install PHP on your Mac:
- Go to https://brew.sh/ and install Homebrew. It is a missing package manager for macOS
- After Homebrew is installed, you can install PHP with the following command: brew install php – Before starting the download, it will request your machine’s password.
You can also follow this simple video on installing PHP 8 in macOS Big Sur.
Note: here’s a resource that explains how to install PHP on Windows.
Installing Composer Globally
Now that PHP is on our machine, we’ll download Composer (a PHP package manager we’ll use to download Goutte) by following their documentation.
- Open your terminal on your desktop (cd desktop) and write
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');". A file named composer-setup.php will be on your desktop now.

- Next, copy and paste the following command:
</p>
php -r "if (hash_file('sha384', 'composer-setup.php') === '756890a4488ce9024fc62c56153228907f1545c228516cbf63f885e036d37e9a59d27d63f46af1d4d07ee0f76181c7d3') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;"
<p>This will verify that the setup file was downloaded correctly.

- After verifying the file, we’ll run the script with php composer-setup.php. This command will download and install the actual Composer.


- If we stop at this point, we’ll only be able to call the Composer from the desktop, which is not what we want. To move it to our Path, we’ll use the command
mv composer.phar /usr/local/bin/composer.
![]()
Oops! We had a little problem with our command. But don’t worry, all we need to do is use sudo in our command, so it will look like this:
</p>
sudo mv composer.phar /usr/local/bin/composer
<p>It will ask for our password and then move the file to the indicated directory.
- To finish the process, let’s call Composer to verify that it’s working correctly by typing composer into the terminal. It should call the executable and show you the following message.


If it is not working, go to your finder, hit shift+command+G, and enter the usr/local/bin/ path into the pop-up.
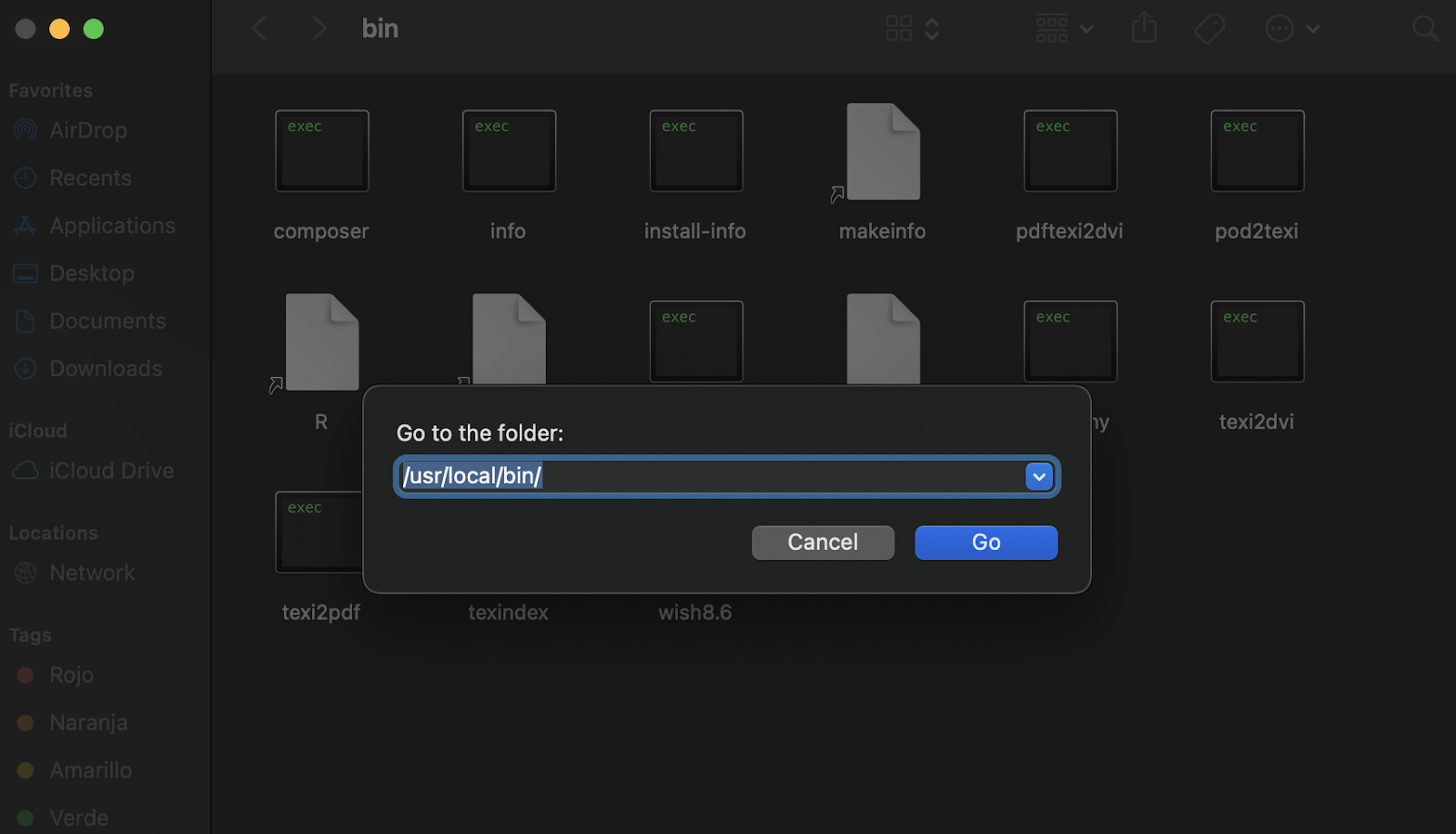
Noticed that our ‘composer.phar’ file is now called ‘composer’ and it’s an executable file. If you’re seeing it still being a .phar file, just change its name and you’ll be able to use the composer command.
Note: After this is done, you can delete the installer using the following command php -r "unlink('composer-setup.php');".
Installing Guzzle and Goutte
The reason we’re installing Guzzle is because Goutte needs it to run properly.
Run composer require guzzlehttp/guzzle in your terminal to install Guzzle and composer require fabpot/goutte to install goutte, respectively.
It will take a few seconds and then we’ll be ready to start writing our scraper.
3. Scrape all Titles From the Page
We’re going to be using Visual Studio Code but you can follow along using your preferred text editor.
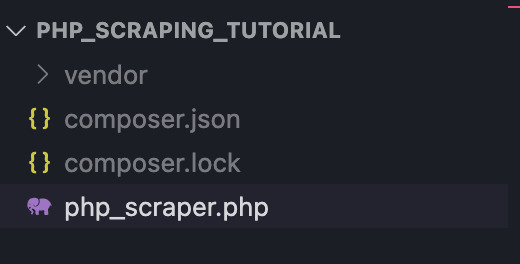
Let’s create a folder called ‘php_scraper_tutorial’ and go to it in visual studio. Then, open a new terminal and install Goutte inside using composer require fabpot/goutte.
It will add a new folder called ‘vendor’ and two files (‘composer.json’ and ‘composer.lock’). With those ready, create a new file called ‘php_scraper.php’. Your folder should look something like this:
We’ll start our file with the PHP tag (<?php) and import our dependency to our project.
</p>
require 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
<p>The PHP autoloading will load every library we need automatically, saving us a lot of time and headaches. Then we open a new Goutte client through which we’ll send the request.
To do so, we’ll create a new instance called ‘$crawler’ and give make it send the request to Newchic’s page, specifying the method – in our case GET – before the URL.
</p>
$crawler = $client->request('GET', 'https://www.newchic.com/women-t-shirts-c-3666/?mg_id=1&from=nav&country=223&NA=1')
<p>But we don’t just want the HTML, do we?
After getting the response, we want to use the CSS class we identified before to extract only the names of each t-shirt. That’s when filter() comes to save the day.
</p>
$crawler->filter('.lg text-ellipsis d-block text-hover-underline text-s;econdary-hover font-small-12 text-grey product-item-name-js')->each(function($node){
var_dump($node->text());
});
<p>Our script will filter all the <a> elements that match the class we specified and iterate through each of the nodes (because we’ll have more than one when extracting all the elements).
However, after running the script we’re actually getting a fatal error, and nothing is returned.
This is very common in web scraping (and in any development environment for that matter) and the important thing is not to get discouraged.
After a lot of tries, we used the chrome extension SelectorGadget to get the right CSS selector.
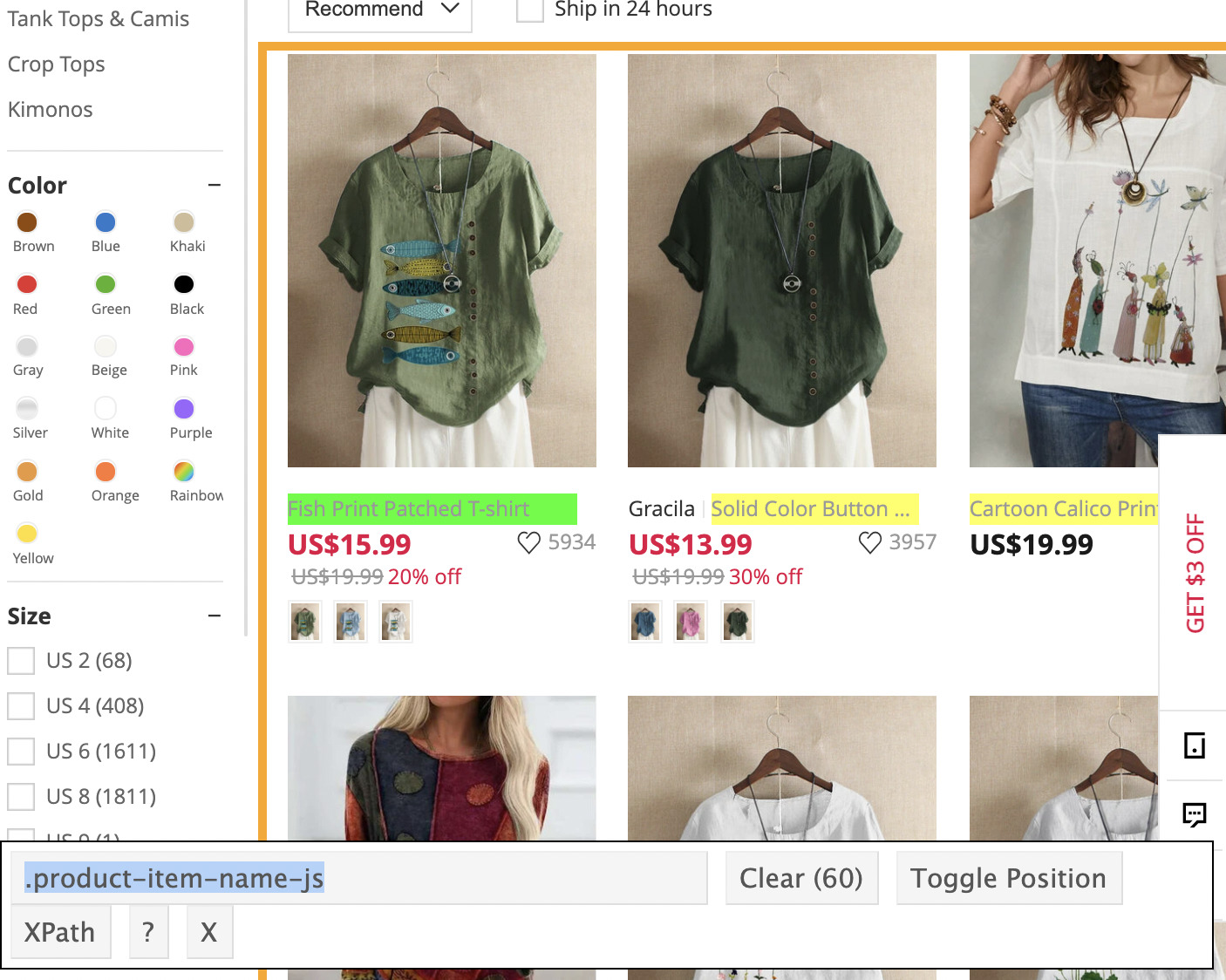
Apparently, the problem was that our script wasn’t able to find the class we told it to look for. So it was crashing in the middle of the operation.
After updating the code:
</p>
$crawler->filter('.product-item-name-js')->each(function($node){
var_dump($node->text());
});
<p>We were able to run the code and get the 60 product names on the page:

Wait… Spanish? What just happened?
Newchic’s website shows different content depending on location (like Amazon would) and because the IP from which we’re sending the request is from a Latin country, the site responds with the Spanish version of the page.
To overcome this, we need to change our IP address.
4. Integrate Scraper API with PHP for geotargeting
Scraper API is a solution that combines 3rd party proxies, AI, and years of statistical data to prevent our scrapers to get blocked by CAPTCHAs, bans and other anti-scraping techniques.
What’s more, we can use the API to execute JavaScript (for which we would have to use a headless browser for) and access geo-specific data.
First, let’s create a free Scraper API account to get access to 5000 free API credits (per month) and our API key.
Once we’re in our dashboard, we’ll use the cURL sample to build the URL we’re using for our script.

What we’re doing now is adding Newchic’s URL after the url parameter, plus an extra parameter at the end of the string.
</p>
$crawler = $client->request('GET', 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb6266xxxxxxxx&url=https://www.newchic.com/women-t-shirts-c-3666/?mg_id=1&from=nav&country=223&NA=1&country_code=us');
<p>The country_code parameter will tell Scraper API to send the request from a US proxy.
If we now run our script we’ll see that the content that returns is now in English and it’s what US users will see in their browsers.

For a complete list of country codes available and more, take a look at our detailed documentation.
Note: If you want to get access data from a site that requires you to execute JavaScript, just set render=true, and remember that every parameter is separated by a &.
5. Scrape the Multiple Elements from a Web Page
For this section, we’ll mix things a little. We want to create a different variable for each of the elements we want to grab.
For starters, let’s change the first filter to make our PHP scraper look for the element wrapping the name, price, and link.
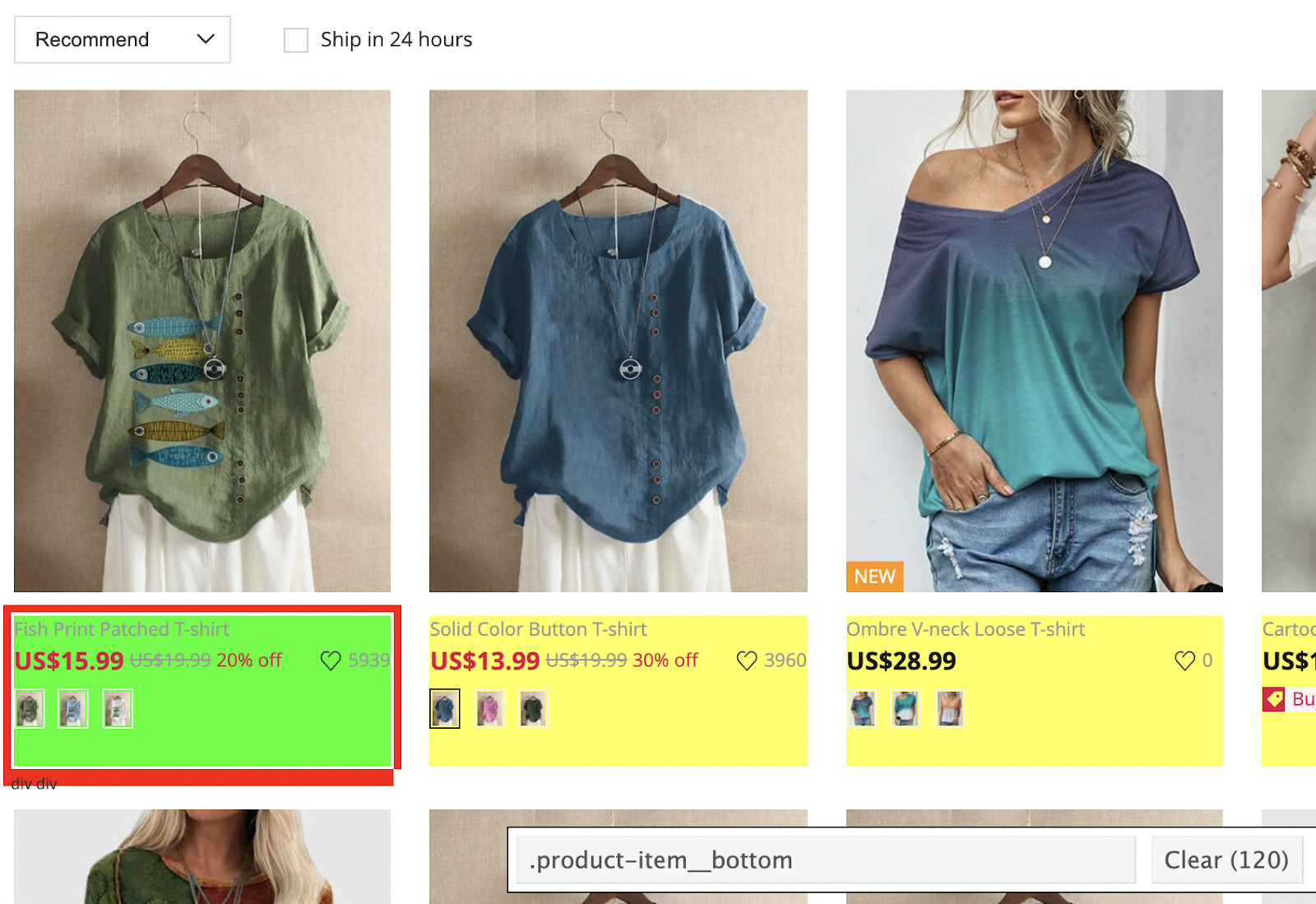
We’ll create new variables for each element, and use the filter() function to find the element inside the $node.
</p>
crawler->filter('.product-item__bottom')->each(function($node){
$name = $node->filter('.product-item-name-js')->text();
$price = $node->filter('.product-price-js')->text();
<p>For the price and name we want to grab the text but that’s not the case for the link. To get the value inside the href attribute, we’ll use attr(‘href’) method. Just to make sure it finds the correct line, we added the a tag inside the CSS selector.
</p>
$link = $node->filter('a.product-item-name-js')->attr('href');
<p>After updating our file, it should look like this:
</p>
include 'vendor/autoload.php';
use Goutte\Client;
$client = new Client();
$crawler = $client->request('GET', 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660fc6ee44&url=https://www.newchic.com/women-t-shirts-c-3666/?mg_id=1&from=nav&country=223&NA=1&country_code=us');
$crawler->filter('.product-item__bottom')->each(function($node){
$name = $node->filter('.product-item-name-js')->text();
$price = $node->filter('.product-price-js')->text();
$link = $node->filter('a.product-item-name-js')->attr('href');
});
<p>Wrapping Up
Congratulations! You just created your first PHP web scraper using Goutte. Of course, there’s still a lot to learn.
For now, we’ll stop this tutorial at this point as it is an introduction to web scraping with PHP.
In future tutorials, we’ll expand our scraper capabilities so it can follow links to scrape multiple pages from one script and turn our scraped data into a CSV file we can use for further analysis.
If you’d like to learn more about web scraping, take a look at our tips for large-scale scraping projects.
For more information about using Scraper API, check the Scraper API cheat sheet and scraping best practices page. You’ll understand the main challenges every web scraper will face and how to solve them with a simple API call.
Happy scraping!






